| Table 5.2: Mapping of NTL variants to various memory hierarchies. |
The RISC-V Instruction Set Manual |
Contributors to all versions of the spec in alphabetical order (please contact editors to suggest corrections): Arvind, Krste Asanović, Rimas Avižienis, Jacob Bachmeyer, Christopher F. Batten, Allen J. Baum, Alex Bradbury, Scott Beamer, Preston Briggs, Christopher Celio, Chuanhua Chang, David Chisnall, Paul Clayton, Palmer Dabbelt, Ken Dockser, Roger Espasa, Greg Favor, Shaked Flur, Stefan Freudenberger, Marc Gauthier, Andy Glew, Jan Gray, Michael Hamburg, John Hauser, David Horner, Bruce Hoult, Bill Huffman, Alexandre Joannou, Olof Johansson, Ben Keller, David Kruckemyer, Yunsup Lee, Paul Loewenstein, Daniel Lustig, Yatin Manerkar, Luc Maranget, Margaret Martonosi, Joseph Myers, Vijayanand Nagarajan, Rishiyur Nikhil, Jonas Oberhauser, Stefan O’Rear, Albert Ou, John Ousterhout, David Patterson, Christopher Pulte, Jose Renau, Josh Scheid, Colin Schmidt, Peter Sewell, Susmit Sarkar, Michael Taylor, Wesley Terpstra, Matt Thomas, Tommy Thorn, Caroline Trippel, Ray VanDeWalker, Muralidaran Vijayaraghavan, Megan Wachs, Andrew Waterman, Robert Watson, Derek Williams, Andrew Wright, Reinoud Zandijk, and Sizhuo Zhang.
This document is released under a Creative Commons Attribution 4.0 International License.
This document is a derivative of “The RISC-V Instruction Set Manual, Volume I: User-Level ISA Version 2.1” released under the following license: © 2010–2017 Andrew Waterman, Yunsup Lee, David Patterson, Krste Asanović. Creative Commons Attribution 4.0 International License.
Please cite as: “The RISC-V Instruction Set Manual, Volume I: User-Level ISA, Document Version 20191214-draft”, Editors Andrew Waterman and Krste Asanović, RISC-V International, December 2019.
This document describes the RISC-V unprivileged architecture.
The ISA modules marked Ratified have been ratified at this time. The modules marked Frozen are not expected to change significantly before being put up for ratification. The modules marked Draft are expected to change before ratification.
The document contains the following versions of the RISC-V ISA modules:
Base Version Status RVWMO 2.0 Ratified RV32I 2.1 Ratified RV64I 2.1 Ratified RV32E 1.9 Draft RV128I 1.7 Draft Extension Version Status M 2.0 Ratified A 2.1 Ratified F 2.2 Ratified D 2.2 Ratified Q 2.2 Ratified C 2.0 Ratified Counters 2.0 Draft L 0.0 Draft B 0.0 Draft J 0.0 Draft T 0.0 Draft P 0.2 Draft V 0.7 Draft Zicsr 2.0 Ratified Zifencei 2.0 Ratified Zihintpause 2.0 Ratified Zihintntl 0.2 Draft Zam 0.1 Draft Zfh 1.0 Ratified Zfhmin 1.0 Ratified Zfinx 1.0 Ratified Zdinx 1.0 Ratified Zhinx 1.0 Ratified Zhinxmin 1.0 Ratified Ztso 0.1 Frozen
This document describes the RISC-V unprivileged architecture.
The ISA modules marked Ratified have been ratified at this time. The modules marked Frozen are not expected to change significantly before being put up for ratification. The modules marked Draft are expected to change before ratification.
The document contains the following versions of the RISC-V ISA modules:
Base Version Status RVWMO 2.0 Ratified RV32I 2.1 Ratified RV64I 2.1 Ratified RV32E 1.9 Draft RV128I 1.7 Draft Extension Version Status M 2.0 Ratified A 2.1 Ratified F 2.2 Ratified D 2.2 Ratified Q 2.2 Ratified C 2.0 Ratified Counters 2.0 Draft L 0.0 Draft B 0.0 Draft J 0.0 Draft T 0.0 Draft P 0.2 Draft V 0.7 Draft Zicsr 2.0 Ratified Zifencei 2.0 Ratified Zam 0.1 Draft Ztso 0.1 Frozen
The changes in this version of the document include:
This document describes the RISC-V unprivileged architecture.
The RVWMO memory model has been ratified at this time. The ISA modules marked Ratified, have been ratified at this time. The modules marked Frozen are not expected to change significantly before being put up for ratification. The modules marked Draft are expected to change before ratification.
The document contains the following versions of the RISC-V ISA modules:
Base Version Status RVWMO 2.0 Ratified RV32I 2.1 Ratified RV64I 2.1 Ratified RV32E 1.9 Draft RV128I 1.7 Draft Extension Version Status Zifencei 2.0 Ratified Zicsr 2.0 Ratified M 2.0 Ratified A 2.0 Frozen F 2.2 Ratified D 2.2 Ratified Q 2.2 Ratified C 2.0 Ratified Ztso 0.1 Frozen Counters 2.0 Draft L 0.0 Draft B 0.0 Draft J 0.0 Draft T 0.0 Draft P 0.2 Draft V 0.7 Draft N 1.1 Draft Zam 0.1 Draft
The changes in this version of the document include:
This is version 2.2 of the document describing the RISC-V user-level architecture. The document contains the following versions of the RISC-V ISA modules:
Base Version Draft Frozen? RV32I 2.0 Y RV32E 1.9 N RV64I 2.0 Y RV128I 1.7 N Extension Version Frozen? M 2.0 Y A 2.0 Y F 2.0 Y D 2.0 Y Q 2.0 Y L 0.0 N C 2.0 Y B 0.0 N J 0.0 N T 0.0 N P 0.1 N V 0.7 N N 1.1 N
To date, no parts of the standard have been officially ratified by the RISC-V Foundation, but the components labeled “frozen” above are not expected to change during the ratification process beyond resolving ambiguities and holes in the specification.
The major changes in this version of the document include:
This is version 2.1 of the document describing the RISC-V user-level architecture. Note the frozen user-level ISA base and extensions IMAFDQ version 2.0 have not changed from the previous version of this document [], but some specification holes have been fixed and the documentation has been improved. Some changes have been made to the software conventions.
This is the second release of the user ISA specification, and we intend the specification of the base user ISA plus general extensions (i.e., IMAFD) to remain fixed for future development. The following changes have been made since Version 1.0 [] of this ISA specification.
RISC-V (pronounced “risk-five”) is a new instruction-set architecture (ISA) that was originally designed to support computer architecture research and education, but which we now hope will also become a standard free and open architecture for industry implementations. Our goals in defining RISC-V include:
The RISC-V ISA is defined avoiding implementation details as much as possible (although commentary is included on implementation-driven decisions) and should be read as the software-visible interface to a wide variety of implementations rather than as the design of a particular hardware artifact. The RISC-V manual is structured in two volumes. This volume covers the design of the base unprivileged instructions, including optional unprivileged ISA extensions. Unprivileged instructions are those that are generally usable in all privilege modes in all privileged architectures, though behavior might vary depending on privilege mode and privilege architecture. The second volume provides the design of the first (“classic”) privileged architecture. The manuals use IEC 80000-13:2008 conventions, with a byte of 8 bits.
A RISC-V hardware platform can contain one or more RISC-V-compatible processing cores together with other non-RISC-V-compatible cores, fixed-function accelerators, various physical memory structures, I/O devices, and an interconnect structure to allow the components to communicate.
A component is termed a core if it contains an independent instruction fetch unit. A RISC-V-compatible core might support multiple RISC-V-compatible hardware threads, or harts, through multithreading.
A RISC-V core might have additional specialized instruction-set extensions or an added coprocessor. We use the term coprocessor to refer to a unit that is attached to a RISC-V core and is mostly sequenced by a RISC-V instruction stream, but which contains additional architectural state and instruction-set extensions, and possibly some limited autonomy relative to the primary RISC-V instruction stream.
We use the term accelerator to refer to either a non-programmable fixed-function unit or a core that can operate autonomously but is specialized for certain tasks. In RISC-V systems, we expect many programmable accelerators will be RISC-V-based cores with specialized instruction-set extensions and/or customized coprocessors. An important class of RISC-V accelerators are I/O accelerators, which offload I/O processing tasks from the main application cores.
The system-level organization of a RISC-V hardware platform can range from a single-core microcontroller to a many-thousand-node cluster of shared-memory manycore server nodes. Even small systems-on-a-chip might be structured as a hierarchy of multicomputers and/or multiprocessors to modularize development effort or to provide secure isolation between subsystems.
The behavior of a RISC-V program depends on the execution environment in which it runs. A RISC-V execution environment interface (EEI) defines the initial state of the program, the number and type of harts in the environment including the privilege modes supported by the harts, the accessibility and attributes of memory and I/O regions, the behavior of all legal instructions executed on each hart (i.e., the ISA is one component of the EEI), and the handling of any interrupts or exceptions raised during execution including environment calls. Examples of EEIs include the Linux application binary interface (ABI), or the RISC-V supervisor binary interface (SBI). The implementation of a RISC-V execution environment can be pure hardware, pure software, or a combination of hardware and software. For example, opcode traps and software emulation can be used to implement functionality not provided in hardware. Examples of execution environment implementations include:
From the perspective of software running in a given execution environment, a hart is a resource that autonomously fetches and executes RISC-V instructions within that execution environment. In this respect, a hart behaves like a hardware thread resource even if time-multiplexed onto real hardware by the execution environment. Some EEIs support the creation and destruction of additional harts, for example, via environment calls to fork new harts.
The execution environment is responsible for ensuring the eventual forward progress of each of its harts. For a given hart, that responsibility is suspended while the hart is exercising a mechanism that explicitly waits for an event, such as the wait-for-interrupt instruction defined in Volume II of this specification; and that responsibility ends if the hart is terminated. The following events constitute forward progress:
The important distinction between a hardware thread (hart) and a software thread context is that the software running inside an execution environment is not responsible for causing progress of each of its harts; that is the responsibility of the outer execution environment. So the environment’s harts operate like hardware threads from the perspective of the software inside the execution environment.
An execution environment implementation might time-multiplex a set of guest harts onto fewer host harts provided by its own execution environment but must do so in a way that guest harts operate like independent hardware threads. In particular, if there are more guest harts than host harts then the execution environment must be able to preempt the guest harts and must not wait indefinitely for guest software on a guest hart to “yield" control of the guest hart.
A RISC-V ISA is defined as a base integer ISA, which must be present in any implementation, plus optional extensions to the base ISA. The base integer ISAs are very similar to that of the early RISC processors except with no branch delay slots and with support for optional variable-length instruction encodings. A base is carefully restricted to a minimal set of instructions sufficient to provide a reasonable target for compilers, assemblers, linkers, and operating systems (with additional privileged operations), and so provides a convenient ISA and software toolchain “skeleton” around which more customized processor ISAs can be built.
Although it is convenient to speak of the RISC-V ISA, RISC-V is actually a family of related ISAs, of which there are currently four base ISAs. Each base integer instruction set is characterized by the width of the integer registers and the corresponding size of the address space and by the number of integer registers. There are two primary base integer variants, RV32I and RV64I, described in Chapters 3 and 8, which provide 32-bit or 64-bit address spaces respectively. We use the term XLEN to refer to the width of an integer register in bits (either 32 or 64). Chapter 7 describes the RV32E subset variant of the RV32I base instruction set, which has been added to support small microcontrollers, and which has half the number of integer registers. Chapter 9 sketches a future RV128I variant of the base integer instruction set supporting a flat 128-bit address space (XLEN=128). The base integer instruction sets use a two’s-complement representation for signed integer values.
The main advantage of explicitly separating base ISAs is that each base ISA can be optimized for its needs without requiring to support all the operations needed for other base ISAs. For example, RV64I can omit instructions and CSRs that are only needed to cope with the narrower registers in RV32I. The RV32I variants can use encoding space otherwise reserved for instructions only required by wider address-space variants.
The main disadvantage of not treating the design as a single ISA is that it complicates the hardware needed to emulate one base ISA on another (e.g., RV32I on RV64I). However, differences in addressing and illegal instruction traps generally mean some mode switch would be required in hardware in any case even with full superset instruction encodings, and the different RISC-V base ISAs are similar enough that supporting multiple versions is relatively low cost. Although some have proposed that the strict superset design would allow legacy 32-bit libraries to be linked with 64-bit code, this is impractical in practice, even with compatible encodings, due to the differences in software calling conventions and system-call interfaces.
The RISC-V privileged architecture provides fields in misa to control the unprivileged ISA at each level to support emulating different base ISAs on the same hardware. We note that newer SPARC and MIPS ISA revisions have deprecated support for running 32-bit code unchanged on 64-bit systems.
A related question is why there is a different encoding for 32-bit adds in RV32I (ADD) and RV64I (ADDW)? The ADDW opcode could be used for 32-bit adds in RV32I and ADDD for 64-bit adds in RV64I, instead of the existing design which uses the same opcode ADD for 32-bit adds in RV32I and 64-bit adds in RV64I with a different opcode ADDW for 32-bit adds in RV64I. This would also be more consistent with the use of the same LW opcode for 32-bit load in both RV32I and RV64I. The very first versions of RISC-V ISA did have a variant of this alternate design, but the RISC-V design was changed to the current choice in January 2011. Our focus was on supporting 32-bit integers in the 64-bit ISA not on providing compatibility with the 32-bit ISA, and the motivation was to remove the asymmetry that arose from having not all opcodes in RV32I have a *W suffix (e.g., ADDW, but AND not ANDW). In hindsight, this was perhaps not well-justified and a consequence of designing both ISAs at the same time as opposed to adding one later to sit on top of another, and also from a belief we had to fold platform requirements into the ISA spec which would imply that all the RV32I instructions would have been required in RV64I. It is too late to change the encoding now, but this is also of little practical consequence for the reasons stated above.
It has been noted we could enable the *W variants as an extension to RV32I systems to provide a common encoding across RV64I and a future RV32 variant.
RISC-V has been designed to support extensive customization and specialization. Each base integer ISA can be extended with one or more optional instruction-set extensions. An extension may be categorized as either standard, custom, or non-conforming. For this purpose, we divide each RISC-V instruction-set encoding space (and related encoding spaces such as the CSRs) into three disjoint categories: standard, reserved, and custom. Standard extensions and encodings are defined by RISC-V International; any extensions not defined by RISC-V International are non-standard. Each base ISA and its standard extensions use only standard encodings, and shall not conflict with each other in their uses of these encodings. Reserved encodings are currently not defined but are saved for future standard extensions; once thus used, they become standard encodings. Custom encodings shall never be used for standard extensions and are made available for vendor-specific non-standard extensions. Non-standard extensions are either custom extensions, that use only custom encodings, or non-conforming extensions, that use any standard or reserved encoding. Instruction-set extensions are generally shared but may provide slightly different functionality depending on the base ISA. Chapter 28 describes various ways of extending the RISC-V ISA. We have also developed a naming convention for RISC-V base instructions and instruction-set extensions, described in detail in Chapter 29.
To support more general software development, a set of standard extensions are defined to provide integer multiply/divide, atomic operations, and single and double-precision floating-point arithmetic. The base integer ISA is named “I” (prefixed by RV32 or RV64 depending on integer register width), and contains integer computational instructions, integer loads, integer stores, and control-flow instructions. The standard integer multiplication and division extension is named “M”, and adds instructions to multiply and divide values held in the integer registers. The standard atomic instruction extension, denoted by “A”, adds instructions that atomically read, modify, and write memory for inter-processor synchronization. The standard single-precision floating-point extension, denoted by “F”, adds floating-point registers, single-precision computational instructions, and single-precision loads and stores. The standard double-precision floating-point extension, denoted by “D”, expands the floating-point registers, and adds double-precision computational instructions, loads, and stores. The standard “C” compressed instruction extension provides narrower 16-bit forms of common instructions.
Beyond the base integer ISA and the standard GC extensions, we believe it is rare that a new instruction will provide a significant benefit for all applications, although it may be very beneficial for a certain domain. As energy efficiency concerns are forcing greater specialization, we believe it is important to simplify the required portion of an ISA specification. Whereas other architectures usually treat their ISA as a single entity, which changes to a new version as instructions are added over time, RISC-V will endeavor to keep the base and each standard extension constant over time, and instead layer new instructions as further optional extensions. For example, the base integer ISAs will continue as fully supported standalone ISAs, regardless of any subsequent extensions.
A RISC-V hart has a single byte-addressable address space of 2XLEN bytes for all memory accesses. A word of memory is defined as 32 bits (4 bytes). Correspondingly, a halfword is 16 bits (2 bytes), a doubleword is 64 bits (8 bytes), and a quadword is 128 bits (16 bytes). The memory address space is circular, so that the byte at address 2XLEN−1 is adjacent to the byte at address zero. Accordingly, memory address computations done by the hardware ignore overflow and instead wrap around modulo 2XLEN.
The execution environment determines the mapping of hardware resources into a hart’s address space. Different address ranges of a hart’s address space may (1) be vacant, or (2) contain main memory, or (3) contain one or more I/O devices. Reads and writes of I/O devices may have visible side effects, but accesses to main memory cannot. Although it is possible for the execution environment to call everything in a hart’s address space an I/O device, it is usually expected that some portion will be specified as main memory.
When a RISC-V platform has multiple harts, the address spaces of any two harts may be entirely the same, or entirely different, or may be partly different but sharing some subset of resources, mapped into the same or different address ranges.
Executing each RISC-V machine instruction entails one or more memory accesses, subdivided into implicit and explicit accesses. For each instruction executed, an implicit memory read (instruction fetch) is done to obtain the encoded instruction to execute. Many RISC-V instructions perform no further memory accesses beyond instruction fetch. Specific load and store instructions perform an explicit read or write of memory at an address determined by the instruction. The execution environment may dictate that instruction execution performs other implicit memory accesses (such as to implement address translation) beyond those documented for the unprivileged ISA.
The execution environment determines what portions of the non-vacant address space are accessible for each kind of memory access. For example, the set of locations that can be implicitly read for instruction fetch may or may not have any overlap with the set of locations that can be explicitly read by a load instruction; and the set of locations that can be explicitly written by a store instruction may be only a subset of locations that can be read. Ordinarily, if an instruction attempts to access memory at an inaccessible address, an exception is raised for the instruction. Vacant locations in the address space are never accessible.
Except when specified otherwise, implicit reads that do not raise an exception may occur arbitrarily early and speculatively, even before the machine could possibly prove that the read will be needed. For instance, a valid implementation could attempt to read all of main memory at the earliest opportunity, cache as many fetchable (executable) bytes as possible for later instruction fetches, and avoid reading main memory for instruction fetches ever again. To ensure that certain implicit reads are ordered only after writes to the same memory locations, software must execute specific fence or cache-control instructions defined for this purpose (such as the FENCE.I instruction defined in Chapter 4).
The memory accesses (implicit or explicit) made by a hart may appear to occur in a different order as perceived by another hart or by any other agent that can access the same memory. This perceived reordering of memory accesses is always constrained, however, by the applicable memory consistency model. The default memory consistency model for RISC-V is the RISC-V Weak Memory Ordering (RVWMO), defined in Chapter 18 and in appendices. Optionally, an implementation may adopt the stronger model of Total Store Ordering, as defined in Chapter 26. The execution environment may also add constraints that further limit the perceived reordering of memory accesses. Since the RVWMO model is the weakest model allowed for any RISC-V implementation, software written for this model is compatible with the actual memory consistency rules of all RISC-V implementations. As with implicit reads, software must execute fence or cache-control instructions to ensure specific ordering of memory accesses beyond the requirements of the assumed memory consistency model and execution environment.
The base RISC-V ISA has fixed-length 32-bit instructions that must be naturally aligned on 32-bit boundaries. However, the standard RISC-V encoding scheme is designed to support ISA extensions with variable-length instructions, where each instruction can be any number of 16-bit instruction parcels in length and parcels are naturally aligned on 16-bit boundaries. The standard compressed ISA extension described in Chapter 19 reduces code size by providing compressed 16-bit instructions and relaxes the alignment constraints to allow all instructions (16 bit and 32 bit) to be aligned on any 16-bit boundary to improve code density.
We use the term IALIGN (measured in bits) to refer to the instruction-address alignment constraint the implementation enforces. IALIGN is 32 bits in the base ISA, but some ISA extensions, including the compressed ISA extension, relax IALIGN to 16 bits. IALIGN may not take on any value other than 16 or 32.
We use the term ILEN (measured in bits) to refer to the maximum instruction length supported by an implementation, and which is always a multiple of IALIGN. For implementations supporting only a base instruction set, ILEN is 32 bits. Implementations supporting longer instructions have larger values of ILEN.
Figure 2.1 illustrates the standard RISC-V instruction-length encoding convention. All the 32-bit instructions in the base ISA have their lowest two bits set to 11. The optional compressed 16-bit instruction-set extensions have their lowest two bits equal to 00, 01, or 10.
A portion of the 32-bit instruction-encoding space has been tentatively allocated for instructions longer than 32 bits. The entirety of this space is reserved at this time, and the following proposal for encoding instructions longer than 32 bits is not considered frozen.
Standard instruction-set extensions encoded with more than 32 bits have additional low-order bits set to 1, with the conventions for 48-bit and 64-bit lengths shown in Figure 2.1. Instruction lengths between 80 bits and 176 bits are encoded using a 3-bit field in bits [14:12] giving the number of 16-bit words in addition to the first 5×16-bit words. The encoding with bits [14:12] set to 111 is reserved for future longer instruction encodings.
xxxxxxxxxxxxxxaa 16-bit (aa ≠ 11) xxxxxxxxxxxxxxxx xxxxxxxxxxxbbb11 32-bit (bbb ≠ 111) ···xxxx xxxxxxxxxxxxxxxx xxxxxxxxxx011111 48-bit ···xxxx xxxxxxxxxxxxxxxx xxxxxxxxx0111111 64-bit ···xxxx xxxxxxxxxxxxxxxx xnnnxxxxx1111111 (80+16*nnn)-bit, nnn≠111 ···xxxx xxxxxxxxxxxxxxxx x111xxxxx1111111 Reserved for ≥192-bits Byte Address: base+4 base+2 base
Figure 2.1: RISC-V instruction length encoding. Only the 16-bit and 32-bit encodings are considered frozen at this time.
An implementation of the standard IMAFD ISA need only hold the most-significant 30 bits in instruction caches (a 6.25% saving). On instruction cache refills, any instructions encountered with either low bit clear should be recoded into illegal 30-bit instructions before storing in the cache to preserve illegal instruction exception behavior.
Perhaps more importantly, by condensing our base ISA into a subset of the 32-bit instruction word, we leave more space available for non-standard and custom extensions. In particular, the base RV32I ISA uses less than 1/8 of the encoding space in the 32-bit instruction word. As described in Chapter 28, an implementation that does not require support for the standard compressed instruction extension can map 3 additional non-conforming 30-bit instruction spaces into the 32-bit fixed-width format, while preserving support for standard ≥32-bit instruction-set extensions. Further, if the implementation also does not need instructions >32-bits in length, it can recover a further four major opcodes for non-conforming extensions.
Encodings with bits [15:0] all zeros are defined as illegal instructions. These instructions are considered to be of minimal length: 16 bits if any 16-bit instruction-set extension is present, otherwise 32 bits. The encoding with bits [ILEN-1:0] all ones is also illegal; this instruction is considered to be ILEN bits long.
Software can rely on a naturally aligned 32-bit word containing zero to act as an illegal instruction on all RISC-V implementations, to be used by software where an illegal instruction is explicitly desired. Defining a corresponding known illegal value for all ones is more difficult due to the variable-length encoding. Software cannot generally use the illegal value of ILEN bits of all 1s, as software might not know ILEN for the eventual target machine (e.g., if software is compiled into a standard binary library used by many different machines). Defining a 32-bit word of all ones as illegal was also considered, as all machines must support a 32-bit instruction size, but this requires the instruction-fetch unit on machines with ILEN>32 report an illegal instruction exception rather than an access-fault exception when such an instruction borders a protection boundary, complicating variable-instruction-length fetch and decode.
RISC-V base ISAs have either little-endian or big-endian memory systems, with the privileged architecture further defining bi-endian operation. Instructions are stored in memory as a sequence of 16-bit little-endian parcels, regardless of memory system endianness. Parcels forming one instruction are stored at increasing halfword addresses, with the lowest-addressed parcel holding the lowest-numbered bits in the instruction specification.
We have to fix the order in which instruction parcels are stored in memory, independent of memory system endianness, to ensure that the length-encoding bits always appear first in halfword address order. This allows the length of a variable-length instruction to be quickly determined by an instruction-fetch unit by examining only the first few bits of the first 16-bit instruction parcel.
We further make the instruction parcels themselves little-endian to decouple the instruction encoding from the memory system endianness altogether. This design benefits both software tooling and bi-endian hardware. Otherwise, for instance, a RISC-V assembler or disassembler would always need to know the intended active endianness, despite that in bi-endian systems, the endianness mode might change dynamically during execution. In contrast, by giving instructions a fixed endianness, it is sometimes possible for carefully written software to be endianness-agnostic even in binary form, much like position-independent code.
The choice to have instructions be only little-endian does have consequences, however, for RISC-V software that encodes or decodes machine instructions. Big-endian JIT compilers, for example, must swap the byte order when storing to instruction memory.
Once we had decided to fix on a little-endian instruction encoding, this naturally led to placing the length-encoding bits in the LSB positions of the instruction format to avoid breaking up opcode fields.
We use the term exception to refer to an unusual condition occurring at run time associated with an instruction in the current RISC-V hart. We use the term interrupt to refer to an external asynchronous event that may cause a RISC-V hart to experience an unexpected transfer of control. We use the term trap to refer to the transfer of control to a trap handler caused by either an exception or an interrupt.
The instruction descriptions in following chapters describe conditions that can raise an exception during execution. The general behavior of most RISC-V EEIs is that a trap to some handler occurs when an exception is signaled on an instruction (except for floating-point exceptions, which, in the standard floating-point extensions, do not cause traps). The manner in which interrupts are generated, routed to, and enabled by a hart depends on the EEI.
How traps are handled and made visible to software running on the hart depends on the enclosing execution environment. From the perspective of software running inside an execution environment, traps encountered by a hart at runtime can have four different effects:
Table 2.1 shows the characteristics of each kind of trap.
The EEI defines for each trap whether it is handled precisely, though the recommendation is to maintain preciseness where possible. Contained and requested traps can be observed to be imprecise by software inside the execution environment. Invisible traps, by definition, cannot be observed to be precise or imprecise by software running inside the execution environment. Fatal traps can be observed to be imprecise by software running inside the execution environment, if known-errorful instructions do not cause immediate termination.
Because this document describes unprivileged instructions, traps are rarely mentioned. Architectural means to handle contained traps are defined in the privileged architecture manual, along with other features to support richer EEIs. Unprivileged instructions that are defined solely to cause requested traps are documented here. Invisible traps are, by their nature, out of scope for this document. Instruction encodings that are not defined here and not defined by some other means may cause a fatal trap.
The architecture fully describes what implementations must do and any constraints on what they may do. In cases where the architecture intentionally does not constrain implementations, the term unspecified is explicitly used.
The term unspecified refers to a behavior or value that is intentionally unconstrained. The definition of these behaviors or values is open to extensions, platform standards, or implementations. Extensions, platform standards, or implementation documentation may provide normative content to further constrain cases that the base architecture defines as unspecified.
Like the base architecture, extensions should fully describe allowable behavior and values and use the term unspecified for cases that are intentionally unconstrained. These cases may be constrained or defined by other extensions, platform standards, or implementations.
This chapter describes the RV32I base integer instruction set.
In practice, a hardware implementation including the machine-mode privileged architecture will also require the 6 CSR instructions.
Subsets of the base integer ISA might be useful for pedagogical purposes, but the base has been defined such that there should be little incentive to subset a real hardware implementation beyond omitting support for misaligned memory accesses and treating all SYSTEM instructions as a single trap.
Figure 3.1 shows the unprivileged state for the base integer ISA. For RV32I, the 32 x registers are each 32 bits wide, i.e., XLEN=32. Register x0 is hardwired with all bits equal to 0. General purpose registers x1–x31 hold values that various instructions interpret as a collection of Boolean values, or as two’s complement signed binary integers or unsigned binary integers.
There is one additional unprivileged register: the program counter pc holds the address of the current instruction.
XLEN-1 0 x0 / zero x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x16 x17 x18 x19 x20 x21 x22 x23 x24 x25 x26 x27 x28 x29 x30 x31 XLEN XLEN-1 0 pc XLEN
Figure 3.1: RISC-V base unprivileged integer register state.
Hardware might choose to accelerate function calls and returns that use x1 or x5. See the descriptions of the JAL and JALR instructions.
The optional compressed 16-bit instruction format is designed around the assumption that x1 is the return address register and x2 is the stack pointer. Software using other conventions will operate correctly but may have greater code size.
For these reasons, we chose a conventional size of 32 integer registers for RV32I. Dynamic register usage tends to be dominated by a few frequently accessed registers, and regfile implementations can be optimized to reduce access energy for the frequently accessed registers []. The optional compressed 16-bit instruction format mostly only accesses 8 registers and hence can provide a dense instruction encoding, while additional instruction-set extensions could support a much larger register space (either flat or hierarchical) if desired.
For resource-constrained embedded applications, we have defined the RV32E subset, which only has 16 registers (Chapter 7).
In the base RV32I ISA, there are four core instruction formats (R/I/S/U), as shown in Figure 3.2. All are a fixed 32 bits in length and must be aligned on a four-byte boundary in memory. An instruction-address-misaligned exception is generated on a taken branch or unconditional jump if the target address is not four-byte aligned. This exception is reported on the branch or jump instruction, not on the target instruction. No instruction-address-misaligned exception is generated for a conditional branch that is not taken.
Instruction-address-misaligned exceptions are reported on the branch or jump that would cause instruction misalignment to help debugging, and to simplify hardware design for systems with IALIGN=32, where these are the only places where misalignment can occur.
The behavior upon decoding a reserved instruction is unspecified.
31 25 24 20 19 15 14 12 11 7 6 0 funct7 rs2 rs1 funct3 rd opcode R-type imm[11:0] rs1 funct3 rd opcode I-type imm[11:5] rs2 rs1 funct3 imm[4:0] opcode S-type imm[31:12] rd opcode U-type
Figure 3.2: RISC-V base instruction formats. Each immediate subfield is labeled with the bit position (imm[x ]) in the immediate value being produced, rather than the bit position within the instruction’s immediate field as is usually done.
The RISC-V ISA keeps the source (rs1 and rs2) and destination (rd) registers at the same position in all formats to simplify decoding. Except for the 5-bit immediates used in CSR instructions (Chapter 12), immediates are always sign-extended, and are generally packed towards the leftmost available bits in the instruction and have been allocated to reduce hardware complexity. In particular, the sign bit for all immediates is always in bit 31 of the instruction to speed sign-extension circuitry.
In practice, most immediates are either small or require all XLEN bits. We chose an asymmetric immediate split (12 bits in regular instructions plus a special load-upper-immediate instruction with 20 bits) to increase the opcode space available for regular instructions.
Immediates are sign-extended because we did not observe a benefit to using zero-extension for some immediates as in the MIPS ISA and wanted to keep the ISA as simple as possible.
There are a further two variants of the instruction formats (B/J) based on the handling of immediates, as shown in Figure 3.3.
31 30 25 24 21 20 19 15 14 12 11 8 7 6 0 funct7 rs2 rs1 funct3 rd opcode R-type imm[11:0] rs1 funct3 rd opcode I-type imm[11:5] rs2 rs1 funct3 imm[4:0] opcode S-type imm[12] imm[10:5] rs2 rs1 funct3 imm[4:1] imm[11] opcode B-type imm[31:12] rd opcode U-type imm[20] imm[10:1] imm[11] imm[19:12] rd opcode J-type
Figure 3.3: RISC-V base instruction formats showing immediate variants.
The only difference between the S and B formats is that the 12-bit immediate field is used to encode branch offsets in multiples of 2 in the B format. Instead of shifting all bits in the instruction-encoded immediate left by one in hardware as is conventionally done, the middle bits (imm[10:1]) and sign bit stay in fixed positions, while the lowest bit in S format (inst[7]) encodes a high-order bit in B format.
Similarly, the only difference between the U and J formats is that the 20-bit immediate is shifted left by 12 bits to form U immediates and by 1 bit to form J immediates. The location of instruction bits in the U and J format immediates is chosen to maximize overlap with the other formats and with each other.
Figure 3.4 shows the immediates produced by each of the base instruction formats, and is labeled to show which instruction bit (inst[y ]) produces each bit of the immediate value.
31 30 20 19 12 11 10 5 4 1 0 — inst[31] — inst[30:25] inst[24:21] inst[20] I-immediate — inst[31] — inst[30:25] inst[11:8] inst[7] S-immediate — inst[31] — inst[7] inst[30:25] inst[11:8] 0 B-immediate inst[31] inst[30:20] inst[19:12] — 0 — U-immediate — inst[31] — inst[19:12] inst[20] inst[30:25] inst[24:21] 0 J-immediate
Figure 3.4: Types of immediate produced by RISC-V instructions. The fields are labeled with the instruction bits used to construct their value. Sign extension always uses inst[31].
Although more complex implementations might have separate adders for branch and jump calculations and so would not benefit from keeping the location of immediate bits constant across types of instruction, we wanted to reduce the hardware cost of the simplest implementations. By rotating bits in the instruction encoding of B and J immediates instead of using dynamic hardware muxes to multiply the immediate by 2, we reduce instruction signal fanout and immediate mux costs by around a factor of 2. The scrambled immediate encoding will add negligible time to static or ahead-of-time compilation. For dynamic generation of instructions, there is some small additional overhead, but the most common short forward branches have straightforward immediate encodings.
Most integer computational instructions operate on XLEN bits of values held in the integer register file. Integer computational instructions are either encoded as register-immediate operations using the I-type format or as register-register operations using the R-type format. The destination is register rd for both register-immediate and register-register instructions. No integer computational instructions cause arithmetic exceptions.
add t0, t1, t2; bltu t0, t1, overflow.For signed addition, if one operand’s sign is known, overflow checking
requires only a single branch after the addition:
addi t0, t1, +imm; blt t0, t1, overflow. This covers the
common case of addition with an immediate operand.
For general signed addition, three additional instructions after the addition are required, leveraging the observation that the sum should be less than one of the operands if and only if the other operand is negative.
add t0, t1, t2
slti t3, t2, 0
slt t4, t0, t1
bne t3, t4, overflow
In RV64I, checks of 32-bit signed additions can be optimized further by comparing the results of ADD and ADDW on the operands.
31 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:0] | rs1 | funct3 | rd | opcode |
12 | 5 | 3 | 5 | 7 |
I-immediate[11:0] | src | ADDI/SLTI[U] | dest | OP-IMM |
I-immediate[11:0] | src | ANDI/ORI/XORI | dest | OP-IMM |
ADDI adds the sign-extended 12-bit immediate to register rs1. Arithmetic overflow is ignored and the result is simply the low XLEN bits of the result. ADDI rd, rs1, 0 is used to implement the MV rd, rs1 assembler pseudoinstruction.
SLTI (set less than immediate) places the value 1 in register rd if register rs1 is less than the sign-extended immediate when both are treated as signed numbers, else 0 is written to rd. SLTIU is similar but compares the values as unsigned numbers (i.e., the immediate is first sign-extended to XLEN bits then treated as an unsigned number). Note, SLTIU rd, rs1, 1 sets rd to 1 if rs1 equals zero, otherwise sets rd to 0 (assembler pseudoinstruction SEQZ rd, rs).
ANDI, ORI, XORI are logical operations that perform bitwise AND, OR, and XOR on register rs1 and the sign-extended 12-bit immediate and place the result in rd. Note, XORI rd, rs1, -1 performs a bitwise logical inversion of register rs1 (assembler pseudoinstruction NOT rd, rs).
31 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:5] | imm[4:0] | rs1 | funct3 | rd | opcode |
7 | 5 | 5 | 3 | 5 | 7 |
0000000 | shamt[4:0] | src | SLLI | dest | OP-IMM |
0000000 | shamt[4:0] | src | SRLI | dest | OP-IMM |
0100000 | shamt[4:0] | src | SRAI | dest | OP-IMM |
Shifts by a constant are encoded as a specialization of the I-type format. The operand to be shifted is in rs1, and the shift amount is encoded in the lower 5 bits of the I-immediate field. The right shift type is encoded in bit 30. SLLI is a logical left shift (zeros are shifted into the lower bits); SRLI is a logical right shift (zeros are shifted into the upper bits); and SRAI is an arithmetic right shift (the original sign bit is copied into the vacated upper bits).
31 12 | 11 7 | 6 0 |
| imm[31:12] | rd | opcode |
20 | 5 | 7 |
U-immediate[31:12] | dest | LUI |
U-immediate[31:12] | dest | AUIPC
|
LUI (load upper immediate) is used to build 32-bit constants and uses the U-type format. LUI places the 32-bit U-immediate value into the destination register rd, filling in the lowest 12 bits with zeros.
AUIPC (add upper immediate to pc) is used to build pc-relative addresses and uses the U-type format. AUIPC forms a 32-bit offset from the U-immediate, filling in the lowest 12 bits with zeros, adds this offset to the address of the AUIPC instruction, then places the result in register rd.
The AUIPC instruction supports two-instruction sequences to access arbitrary offsets from the PC for both control-flow transfers and data accesses. The combination of an AUIPC and the 12-bit immediate in a JALR can transfer control to any 32-bit PC-relative address, while an AUIPC plus the 12-bit immediate offset in regular load or store instructions can access any 32-bit PC-relative data address.
The current PC can be obtained by setting the U-immediate to 0. Although a JAL +4 instruction could also be used to obtain the local PC (of the instruction following the JAL), it might cause pipeline breaks in simpler microarchitectures or pollute BTB structures in more complex microarchitectures.
RV32I defines several arithmetic R-type operations. All operations read the rs1 and rs2 registers as source operands and write the result into register rd. The funct7 and funct3 fields select the type of operation.
31 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct7 | rs2 | rs1 | funct3 | rd | opcode |
7 | 5 | 5 | 3 | 5 | 7 |
0000000 | src2 | src1 | ADD/SLT/SLTU | dest | OP |
0000000 | src2 | src1 | AND/OR/XOR | dest | OP |
0000000 | src2 | src1 | SLL/SRL | dest | OP |
0100000 | src2 | src1 | SUB/SRA | dest | OP |
ADD performs the addition of rs1 and rs2. SUB performs the subtraction of rs2 from rs1. Overflows are ignored and the low XLEN bits of results are written to the destination rd. SLT and SLTU perform signed and unsigned compares respectively, writing 1 to rd if rs1 < rs2, 0 otherwise. Note, SLTU rd, x0, rs2 sets rd to 1 if rs2 is not equal to zero, otherwise sets rd to zero (assembler pseudoinstruction SNEZ rd, rs). AND, OR, and XOR perform bitwise logical operations.
SLL, SRL, and SRA perform logical left, logical right, and arithmetic right shifts on the value in register rs1 by the shift amount held in the lower 5 bits of register rs2.
31 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:0] | rs1 | funct3 | rd | opcode |
12 | 5 | 3 | 5 | 7 |
0 | 0 | ADDI | 0 | OP-IMM |
The NOP instruction does not change any architecturally visible state, except for advancing the pc and incrementing any applicable performance counters. NOP is encoded as ADDI x0, x0, 0.
ADDI was chosen for the NOP encoding as this is most likely to take fewest resources to execute across a range of systems (if not optimized away in decode). In particular, the instruction only reads one register. Also, an ADDI functional unit is more likely to be available in a superscalar design as adds are the most common operation. In particular, address-generation functional units can execute ADDI using the same hardware needed for base+offset address calculations, while register-register ADD or logical/shift operations require additional hardware.
RV32I provides two types of control transfer instructions: unconditional jumps and conditional branches. Control transfer instructions in RV32I do not have architecturally visible delay slots.
If an instruction access-fault or instruction page-fault exception occurs on the target of a jump or taken branch, the exception is reported on the target instruction, not on the jump or branch instruction.
The jump and link (JAL) instruction uses the J-type format, where the J-immediate encodes a signed offset in multiples of 2 bytes. The offset is sign-extended and added to the address of the jump instruction to form the jump target address. Jumps can therefore target a ±1 MiB range. JAL stores the address of the instruction following the jump (pc+4) into register rd. The standard software calling convention uses x1 as the return address register and x5 as an alternate link register.
Plain unconditional jumps (assembler pseudoinstruction J) are encoded as a JAL with rd=x0.
| 31 | 30 21 | 20 | 19 12 | 11 7 | 6 0 |
| imm[20] | imm[10:1] | imm[11] | imm[19:12] | rd | opcode |
1 | 10 | 1 | 8 | 5 | 7 |
| offset[20:1] | dest | JAL | |||
The indirect jump instruction JALR (jump and link register) uses the I-type encoding. The target address is obtained by adding the sign-extended 12-bit I-immediate to the register rs1, then setting the least-significant bit of the result to zero. The address of the instruction following the jump (pc+4) is written to register rd. Register x0 can be used as the destination if the result is not required.
31 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:0] | rs1 | funct3 | rd | opcode |
12 | 5 | 3 | 5 | 7 |
offset[11:0] | base | 0 | dest | JALR |
Note that the JALR instruction does not treat the 12-bit immediate as multiples of 2 bytes, unlike the conditional branch instructions. This avoids one more immediate format in hardware. In practice, most uses of JALR will have either a zero immediate or be paired with a LUI or AUIPC, so the slight reduction in range is not significant.
Clearing the least-significant bit when calculating the JALR target address both simplifies the hardware slightly and allows the low bit of function pointers to be used to store auxiliary information. Although there is potentially a slight loss of error checking in this case, in practice jumps to an incorrect instruction address will usually quickly raise an exception.
When used with a base rs1=x0, JALR can be used to implement a single instruction subroutine call to the lowest 2 KiB or highest 2 KiB address region from anywhere in the address space, which could be used to implement fast calls to a small runtime library. Alternatively, an ABI could dedicate a general-purpose register to point to a library elsewhere in the address space.
The JAL and JALR instructions will generate an instruction-address-misaligned exception if the target address is not aligned to a four-byte boundary.
Return-address prediction stacks are a common feature of high-performance instruction-fetch units, but require accurate detection of instructions used for procedure calls and returns to be effective. For RISC-V, hints as to the instructions’ usage are encoded implicitly via the register numbers used. A JAL instruction should push the return address onto a return-address stack (RAS) only when rd is x1 or x5. JALR instructions should push/pop a RAS as shown in the Table 3.1.
When two different link registers (x1 and x5) are given as
rs1 and rd, then the RAS is both popped and pushed to
support coroutines. If rs1 and rd are the same link
register (either x1 or x5), the RAS is only pushed to
enable macro-op fusion of the sequences:
lui ra, imm20; jalr ra, imm12(ra) and
auipc ra, imm20; jalr ra, imm12(ra)
All branch instructions use the B-type instruction format. The 12-bit B-immediate encodes signed offsets in multiples of 2 bytes. The offset is sign-extended and added to the address of the branch instruction to give the target address. The conditional branch range is ±4 KiB.
| 31 | 30 25 | 24 20 | 19 15 | 14 12 | 11 8 | 7 | 6 0 |
| imm[12] | imm[10:5] | rs2 | rs1 | funct3 | imm[4:1] | imm[11] | opcode |
1 | 6 | 5 | 5 | 3 | 4 | 1 | 7 |
| offset[12|10:5] | src2 | src1 | BEQ/BNE | offset[11|4:1] | BRANCH | ||
| offset[12|10:5] | src2 | src1 | BLT[U] | offset[11|4:1] | BRANCH | ||
| offset[12|10:5] | src2 | src1 | BGE[U] | offset[11|4:1] | BRANCH | ||
Branch instructions compare two registers. BEQ and BNE take the branch if registers rs1 and rs2 are equal or unequal respectively. BLT and BLTU take the branch if rs1 is less than rs2, using signed and unsigned comparison respectively. BGE and BGEU take the branch if rs1 is greater than or equal to rs2, using signed and unsigned comparison respectively. Note, BGT, BGTU, BLE, and BLEU can be synthesized by reversing the operands to BLT, BLTU, BGE, and BGEU, respectively.
Software should be optimized such that the sequential code path is the most common path, with less-frequently taken code paths placed out of line. Software should also assume that backward branches will be predicted taken and forward branches as not taken, at least the first time they are encountered. Dynamic predictors should quickly learn any predictable branch behavior.
Unlike some other architectures, the RISC-V jump (JAL with rd=x0) instruction should always be used for unconditional branches instead of a conditional branch instruction with an always-true condition. RISC-V jumps are also PC-relative and support a much wider offset range than branches, and will not pollute conditional-branch prediction tables.
We considered but did not include static branch hints in the instruction encoding. These can reduce the pressure on dynamic predictors, but require more instruction encoding space and software profiling for best results, and can result in poor performance if production runs do not match profiling runs.
We considered but did not include conditional moves or predicated instructions, which can effectively replace unpredictable short forward branches. Conditional moves are the simpler of the two, but are difficult to use with conditional code that might cause exceptions (memory accesses and floating-point operations). Predication adds additional flag state to a system, additional instructions to set and clear flags, and additional encoding overhead on every instruction. Both conditional move and predicated instructions add complexity to out-of-order microarchitectures, adding an implicit third source operand due to the need to copy the original value of the destination architectural register into the renamed destination physical register if the predicate is false. Also, static compile-time decisions to use predication instead of branches can result in lower performance on inputs not included in the compiler training set, especially given that unpredictable branches are rare, and becoming rarer as branch prediction techniques improve.
We note that various microarchitectural techniques exist to dynamically convert unpredictable short forward branches into internally predicated code to avoid the cost of flushing pipelines on a branch mispredict [, , ] and have been implemented in commercial processors []. The simplest techniques just reduce the penalty of recovering from a mispredicted short forward branch by only flushing instructions in the branch shadow instead of the entire fetch pipeline, or by fetching instructions from both sides using wide instruction fetch or idle instruction fetch slots. More complex techniques for out-of-order cores add internal predicates on instructions in the branch shadow, with the internal predicate value written by the branch instruction, allowing the branch and following instructions to be executed speculatively and out-of-order with respect to other code [].
The conditional branch instructions will generate an instruction-address-misaligned exception if the target address is not aligned to a four-byte boundary and the branch condition evaluates to true. If the branch condition evaluates to false, the instruction-address-misaligned exception will not be raised.
RV32I is a load-store architecture, where only load and store instructions access memory and arithmetic instructions only operate on CPU registers. RV32I provides a 32-bit address space that is byte-addressed. The EEI will define what portions of the address space are legal to access with which instructions (e.g., some addresses might be read only, or support word access only). Loads with a destination of x0 must still raise any exceptions and cause any other side effects even though the load value is discarded.
The EEI will define whether the memory system is little-endian or big-endian. In RISC-V, endianness is byte-address invariant.
In a little-endian configuration, multibyte stores write the least-significant register byte at the lowest memory byte address, followed by the other register bytes in ascending order of their significance. Loads similarly transfer the contents of the lesser memory byte addresses to the less-significant register bytes.
In a big-endian configuration, multibyte stores write the most-significant register byte at the lowest memory byte address, followed by the other register bytes in descending order of their significance. Loads similarly transfer the contents of the greater memory byte addresses to the less-significant register bytes.
31 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:0] | rs1 | funct3 | rd | opcode |
12 | 5 | 3 | 5 | 7 |
offset[11:0] | base | width | dest | LOAD |
31 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:5] | rs2 | rs1 | funct3 | imm[4:0] | opcode |
7 | 5 | 5 | 3 | 5 | 7 |
offset[11:5] | src | base | width | offset[4:0] | STORE |
Load and store instructions transfer a value between the registers and memory. Loads are encoded in the I-type format and stores are S-type. The effective address is obtained by adding register rs1 to the sign-extended 12-bit offset. Loads copy a value from memory to register rd. Stores copy the value in register rs2 to memory.
The LW instruction loads a 32-bit value from memory into rd. LH loads a 16-bit value from memory, then sign-extends to 32-bits before storing in rd. LHU loads a 16-bit value from memory but then zero extends to 32-bits before storing in rd. LB and LBU are defined analogously for 8-bit values. The SW, SH, and SB instructions store 32-bit, 16-bit, and 8-bit values from the low bits of register rs2 to memory.
Regardless of EEI, loads and stores whose effective addresses are naturally aligned shall not raise an address-misaligned exception. Loads and stores whose effective address is not naturally aligned to the referenced datatype (i.e., the effective address is not divisible by the size of the access in bytes) have behavior dependent on the EEI.
An EEI may guarantee that misaligned loads and stores are fully supported, and so the software running inside the execution environment will never experience a contained or fatal address-misaligned trap. In this case, the misaligned loads and stores can be handled in hardware, or via an invisible trap into the execution environment implementation, or possibly a combination of hardware and invisible trap depending on address.
An EEI may not guarantee misaligned loads and stores are handled invisibly. In this case, loads and stores that are not naturally aligned may either complete execution successfully or raise an exception. The exception raised can be either an address-misaligned exception or an access-fault exception. For a memory access that would otherwise be able to complete except for the misalignment, an access-fault exception can be raised instead of an address-misaligned exception if the misaligned access should not be emulated, e.g., if accesses to the memory region have side effects. When an EEI does not guarantee misaligned loads and stores are handled invisibly, the EEI must define if exceptions caused by address misalignment result in a contained trap (allowing software running inside the execution environment to handle the trap) or a fatal trap (terminating execution).
Even when misaligned loads and stores complete successfully, these accesses might run extremely slowly depending on the implementation (e.g., when implemented via an invisible trap). Furthermore, whereas naturally aligned loads and stores are guaranteed to execute atomically, misaligned loads and stores might not, and hence require additional synchronization to ensure atomicity.
31 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| fm | PI | PO | PR | PW | SI | SO | SR | SW | rs1 | funct3 | rd | opcode |
4 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 5 | 3 | 5 | 7 |
FM | predecessor | successor | 0 | FENCE | 0 | MISC-MEM | ||||||
The FENCE instruction is used to order device I/O and memory accesses as viewed by other RISC-V harts and external devices or coprocessors. Any combination of device input (I), device output (O), memory reads (R), and memory writes (W) may be ordered with respect to any combination of the same. Informally, no other RISC-V hart or external device can observe any operation in the successor set following a FENCE before any operation in the predecessor set preceding the FENCE. Chapter 18 provides a precise description of the RISC-V memory consistency model.
The FENCE instruction also orders memory reads and writes made by the hart as observed by memory reads and writes made by an external device. However, FENCE does not order observations of events made by an external device using any other signaling mechanism.
The EEI will define what I/O operations are possible, and in particular, which memory addresses when accessed by load and store instructions will be treated and ordered as device input and device output operations respectively rather than memory reads and writes. For example, memory-mapped I/O devices will typically be accessed with uncached loads and stores that are ordered using the I and O bits rather than the R and W bits. Instruction-set extensions might also describe new I/O instructions that will also be ordered using the I and O bits in a FENCE.
fm field Mnemonic Meaning 0000 none Normal Fence 2*1000 2*TSO With FENCE RW,RW: exclude write-to-read ordering Otherwise: Reserved for future use. other Reserved for future use.
Table 3.2: Fence mode encoding.
The fence mode field fm defines the semantics of the FENCE. A FENCE with fm=0000 orders all memory operations in its predecessor set before all memory operations in its successor set.
The FENCE.TSO instruction is encoded as a FENCE instruction with fm=1000, predecessor=RW, and successor=RW. FENCE.TSO orders all load operations in its predecessor set before all memory operations in its successor set, and all store operations in its predecessor set before all store operations in its successor set. This leaves non-AMO store operations in the FENCE.TSO’s predecessor set unordered with non-AMO loads in its successor set.
The unused fields in the FENCE instructions—rs1 and rd—are reserved for finer-grain fences in future extensions. For forward compatibility, base implementations shall ignore these fields, and standard software shall zero these fields. Likewise, many fm and predecessor/successor set settings in Table 3.2 are also reserved for future use. Base implementations shall treat all such reserved configurations as normal fences with fm=0000, and standard software shall use only non-reserved configurations.
SYSTEM instructions are used to access system functionality that might require privileged access and are encoded using the I-type instruction format. These can be divided into two main classes: those that atomically read-modify-write control and status registers (CSRs), and all other potentially privileged instructions. CSR instructions are described in Chapter 12, and the base unprivileged instructions are described in the following section.
31 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct12 | rs1 | funct3 | rd | opcode |
12 | 5 | 3 | 5 | 7 |
ECALL | 0 | PRIV | 0 | SYSTEM |
EBREAK | 0 | PRIV | 0 | SYSTEM |
These two instructions cause a precise requested trap to the supporting execution environment.
The ECALL instruction is used to make a service request to the execution environment. The EEI will define how parameters for the service request are passed, but usually these will be in defined locations in the integer register file.
The EBREAK instruction is used to return control to a debugging environment.
Another use of EBREAK is to support “semihosting”, where the execution environment includes a debugger that can provide services over an alternate system call interface built around the EBREAK instruction. Because the RISC-V base ISAs do not provide more than one EBREAK instruction, RISC-V semihosting uses a special sequence of instructions to distinguish a semihosting EBREAK from a debugger inserted EBREAK.
slli x0, x0, 0x1f # Entry NOP
ebreak # Break to debugger
srai x0, x0, 7 # NOP encoding the semihosting call number 7
Note that these three instructions must be 32-bit-wide instructions, i.e., they mustn’t be among the compressed 16-bit instructions described in Chapter 19.
The shift NOP instructions are still considered available for use as HINTs.
Semihosting is a form of service call and would be more naturally encoded as an ECALL using an existing ABI, but this would require the debugger to be able to intercept ECALLs, which is a newer addition to the debug standard. We intend to move over to using ECALLs with a standard ABI, in which case, semihosting can share a service ABI with an existing standard.
We note that ARM processors have also moved to using SVC instead of BKPT for semihosting calls in newer designs.
RV32I reserves a large encoding space for HINT instructions, which are usually used to communicate performance hints to the microarchitecture. Like the NOP instruction, HINTs do not change any architecturally visible state, except for advancing the pc and any applicable performance counters. Implementations are always allowed to ignore the encoded hints.
Most RV32I HINTs are encoded as integer computational instructions with rd=x0. The other RV32I HINTs are encoded as FENCE instructions with a null predecessor or successor set and with fm=0.
As another example, a FENCE instruction with a zero pred field and a zero fm field is a HINT; the succ, rs1, and rd fields encode the arguments to the HINT. A simple implementation can simply execute the HINT as a FENCE that orders the null set of prior memory accesses before whichever subsequent memory accesses are encoded in the succ field. Since the intersection of the predecessor and successor sets is null, the instruction imposes no memory orderings, and so it has no architecturally visible effect.
Table 3.3 lists all RV32I HINT code points. 91% of the HINT space is reserved for standard HINTs. The remainder of the HINT space is designated for custom HINTs: no standard HINTs will ever be defined in this subspace.
Instruction Constraints Code Points Purpose LUI rd=x0 220 10*Reserved for future standard use AUIPC rd=x0 220 2*ADDI rd=x0, and either 2*217−1 rs1≠x0 or imm≠0 ANDI rd=x0 217 ORI rd=x0 217 XORI rd=x0 217 ADD rd=x0, rs1≠x0 210−32 2*ADD rd=x0, rs1=x0, 2*28 rs2≠x2–x5 4*ADD 4*[l]rd=x0, rs1=x0,
rs2=x2–x54*4 (rs2=x2) NTL.P1 (rs2=x3) NTL.PALL (rs2=x4) NTL.S1 (rs2=x5) NTL.ALL SUB rd=x0 210 17*Reserved for future standard use AND rd=x0 210 OR rd=x0 210 XOR rd=x0 210 SLL rd=x0 210 SRL rd=x0 210 SRA rd=x0 210 3*FENCE rd=x0, rs1≠x0, 3*210−63 fm=0, and either pred=0 or succ=0 3*FENCE rd≠x0, rs1=x0, 3*210−63 fm=0, and either pred=0 or succ=0 2*FENCE rd=rs1=x0, fm=0, 2*15 pred=0, succ≠0 2*FENCE rd=rs1=x0, fm=0, 2*15 pred≠W, succ=0 2*FENCE rd=rs1=x0, fm=0, 2*1 2*PAUSE pred=W, succ=0 SLTI rd=x0 217 7*Designated for custom use SLTIU rd=x0 217 SLLI rd=x0 210 SRLI rd=x0 210 SRAI rd=x0 210 SLT rd=x0 210 SLTU rd=x0 210
Table 3.3: RV32I HINT instructions.
This chapter defines the “Zifencei” extension, which includes the FENCE.I instruction that provides explicit synchronization between writes to instruction memory and instruction fetches on the same hart. Currently, this instruction is the only standard mechanism to ensure that stores visible to a hart will also be visible to its instruction fetches.
The FENCE.I instruction was previously part of the base I instruction set. Two main issues are driving moving this out of the mandatory base, although at time of writing it is still the only standard method for maintaining instruction-fetch coherence.
First, it has been recognized that on some systems, FENCE.I will be expensive to implement and alternate mechanisms are being discussed in the memory model task group. In particular, for designs that have an incoherent instruction cache and an incoherent data cache, or where the instruction cache refill does not snoop a coherent data cache, both caches must be completely flushed when a FENCE.I instruction is encountered. This problem is exacerbated when there are multiple levels of I and D cache in front of a unified cache or outer memory system.
Second, the instruction is not powerful enough to make available at user level in a Unix-like operating system environment. The FENCE.I only synchronizes the local hart, and the OS can reschedule the user hart to a different physical hart after the FENCE.I. This would require the OS to execute an additional FENCE.I as part of every context migration. For this reason, the standard Linux ABI has removed FENCE.I from user-level and now requires a system call to maintain instruction-fetch coherence, which allows the OS to minimize the number of FENCE.I executions required on current systems and provides forward-compatibility with future improved instruction-fetch coherence mechanisms.
Future approaches to instruction-fetch coherence under discussion include providing more restricted versions of FENCE.I that only target a given address specified in rs1, and/or allowing software to use an ABI that relies on machine-mode cache-maintenance operations.
31 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:0] | rs1 | funct3 | rd | opcode |
12 | 5 | 3 | 5 | 7 |
0 | 0 | FENCE.I | 0 | MISC-MEM |
The FENCE.I instruction is used to synchronize the instruction and data streams. RISC-V does not guarantee that stores to instruction memory will be made visible to instruction fetches on a RISC-V hart until that hart executes a FENCE.I instruction. A FENCE.I instruction ensures that a subsequent instruction fetch on a RISC-V hart will see any previous data stores already visible to the same RISC-V hart. FENCE.I does not ensure that other RISC-V harts’ instruction fetches will observe the local hart’s stores in a multiprocessor system. To make a store to instruction memory visible to all RISC-V harts, the writing hart also has to execute a data FENCE before requesting that all remote RISC-V harts execute a FENCE.I.
The unused fields in the FENCE.I instruction, imm[11:0], rs1, and rd, are reserved for finer-grain fences in future extensions. For forward compatibility, base implementations shall ignore these fields, and standard software shall zero these fields.
The NTL instructions are HINTs that indicate that the explicit memory accesses of the immediately subsequent instruction (henceforth “target instruction”) exhibit poor temporal locality of reference. The NTL instructions do not change architectural state, nor do they alter the architecturally visible effects of the target instruction. Four variants are provided:
The NTL.P1 instruction indicates that the target instruction does not exhibit temporal locality within the capacity of the innermost level of private cache in the memory hierarchy. NTL.P1 is encoded as ADD x0, x0, x2.
The NTL.PALL instruction indicates that the target instruction does not exhibit temporal locality within the capacity of any level of private cache in the memory hierarchy. NTL.PALL is encoded as ADD x0, x0, x3.
The NTL.S1 instruction indicates that the target instruction does not exhibit temporal locality within the capacity of the innermost level of shared cache in the memory hierarchy. NTL.S1 is encoded as ADD x0, x0, x4.
The NTL.ALL instruction indicates that the target instruction does not exhibit temporal locality within the capacity of any level of cache in the memory hierarchy. NTL.ALL is encoded as ADD x0, x0, x5.
A microarchitecture might use the NTL instructions to inform the cache replacement policy, or to decide which cache to allocate into, or to avoid cache allocation altogether. For example, NTL.P1 might indicate that an implementation should not allocate a line in a private L1 cache, but should allocate in L2 (whether private or shared). In another implementation, NTL.P1 might allocate the line in L1, but in the least-recently used state.
NTL.ALL will typically inform implementations not to allocate anywhere in the cache hierarchy. Programmers should use NTL.ALL for accesses that have no exploitable temporal locality.
Like any HINTs, these instructions may be freely ignored. Hence, although they are described in terms of cache-based memory hierarchies, they do not mandate the provision of caches.
Some implementations might respect these HINTs for some memory accesses but not others: e.g., implementations that implement LR/SC by acquiring a cache line in the exclusive state in L1 might ignore NTL instructions on LR and SC, but might respect NTL instructions for AMOs and regular loads and stores.
Table 5.1 lists several software use cases and the recommended NTL variant that portable software—i.e., software not tuned for any specific implementation’s memory hierarchy—should use in each case.
Scenario Recommended NTL variant Access to a working set between 64 KiB and 256 KiB in size NTL.P1 Access to a working set between 256 KiB and 1 MiB in size NTL.PALL Access to a working set greater than 1 MiB in size NTL.S1 Access with no exploitable temporal locality (e.g., streaming) NTL.ALL Access to a contended synchronization variable NTL.PALL
Table 5.1: Recommended NTL variant for portable software to employ in various scenarios.
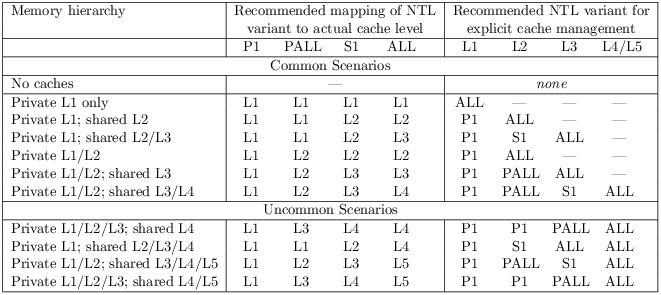
Table 5.2 lists several sample memory hierarchies and recommends how each NTL variant maps onto each cache level. The table also recommends which NTL variant that implementation-tuned software should use to avoid allocating in a particular cache level. For example, for a system with a private L1 and a shared L2, it is recommended that NTL.P1 and NTL.PALL indicate that temporal locality cannot be exploited by the L1, and that NTL.S1 and NTL.ALL indicate that temporal locality cannot be exploited by the L2. Furthermore, software tuned for such a system should use NTL.P1 to indicate a lack of temporal locality exploitable by the L1, or should use NTL.ALL indicate a lack of temporal locality exploitable by the L2.
Table 5.2: Mapping of NTL variants to various memory hierarchies.
If the C extension is provided, compressed variants of these HINTs are also provided: C.NTL.P1 is encoded as C.ADD x0, x2; C.NTL.PALL is encoded as C.ADD x0, x3; C.NTL.S1 is encoded as C.ADD x0, x4; and C.NTL.ALL is encoded as C.ADD x0, x5.
The NTL instructions affect all memory-access instructions except the cache-management instructions in the Zicbom extension.
The NTL instructions can affect cache-management operations other than those in the Zicbom extension. For example, NTL.PALL followed by CBO.ZERO might indicate that the line should be allocated in L3 and zeroed, but not allocated in L1 or L2.
When an NTL instruction is applied to a prefetch hint in the Zicbop extension, it indicates that a cache line should be prefetched into a cache that is outer from the level specified by the NTL.
To prefetch into the innermost level of cache, do not prefix the prefetch instruction with an NTL instruction.
In some systems, NTL.ALL followed by a prefetch instruction might prefetch into a cache or prefetch buffer internal to a memory controller.
Software is discouraged from following an NTL instruction with an instruction that does not explicitly access memory. Nonadherence to this recommendation might reduce performance but otherwise has no architecturally visible effect.
In the event that a trap is taken on the target instruction, implementations are discouraged from applying the NTL to the first instruction in the trap handler. Instead, implementations are recommended to ignore the HINT in this case.
Some implementations might prefer not to process the NTL instruction until the target instruction is seen (e.g., so that the NTL can be fused with the memory access it modifies). Such implementations might preferentially take the interrupt before the NTL, rather than between the NTL and the memory access.
The PAUSE instruction is a HINT that indicates the current hart’s rate of instruction retirement should be temporarily reduced or paused. The duration of its effect must be bounded and may be zero. No architectural state is changed.
A future extension might add primitives similar to the x86 MONITOR/MWAIT instructions, which provide a more efficient mechanism to wait on writes to a specific memory location. However, these instructions would not supplant PAUSE. PAUSE is more appropriate when polling for non-memory events, when polling for multiple events, or when software does not know precisely what events it is polling for.
The duration of a PAUSE instruction’s effect may vary significantly within and among implementations. In typical implementations this duration should be much less than the time to perform a context switch, probably more on the rough order of an on-chip cache miss latency or a cacheless access to main memory.
A series of PAUSE instructions can be used to create a cumulative delay loosely proportional to the number of PAUSE instructions. In spin-wait loops in portable code, however, only one PAUSE instruction should be used before re-evaluating loop conditions, else the hart might stall longer than optimal on some implementations, degrading system performance.
PAUSE is encoded as a FENCE instruction with pred=W, succ=0, fm=0, rd=x0, and rs1=x0.
Like other FENCE instructions, PAUSE cannot be used within LR/SC sequences without voiding the forward-progress guarantee.
The choice of a predecessor set of W is arbitrary, since the successor set is null. Other HINTs similar to PAUSE might be encoded with other predecessor sets.
This chapter describes a draft proposal for the RV32E base integer instruction set, which is a reduced version of RV32I designed for embedded systems. The only change is to reduce the number of integer registers to 16. This chapter only outlines the differences between RV32E and RV32I, and so should be read after Chapter 3.
RV32E reduces the integer register count to 16 general-purpose registers, (x0–x15), where x0 is a dedicated zero register.
RV32E uses the same instruction-set encoding as RV32I, except that only registers x0–x15 are provided. Any future standard extensions will not make use of the instruction bits freed up by the reduced register-specifier fields and so these are designated for custom extensions.
This chapter describes the RV64I base integer instruction set, which builds upon the RV32I variant described in Chapter 3. This chapter presents only the differences with RV32I, so should be read in conjunction with the earlier chapter.
RV64I widens the integer registers and supported user address space to 64 bits (XLEN=64 in Figure 3.1).
Most integer computational instructions operate on XLEN-bit values. Additional instruction variants are provided to manipulate 32-bit values in RV64I, indicated by a ‘W’ suffix to the opcode. These “*W” instructions ignore the upper 32 bits of their inputs and always produce 32-bit signed values, sign-extending them to 64 bits, i.e. bits XLEN-1 through 31 are equal.
31 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:0] | rs1 | funct3 | rd | opcode |
12 | 5 | 3 | 5 | 7 |
I-immediate[11:0] | src | ADDIW | dest | OP-IMM-32 |
ADDIW is an RV64I instruction that adds the sign-extended 12-bit immediate to register rs1 and produces the proper sign-extension of a 32-bit result in rd. Overflows are ignored and the result is the low 32 bits of the result sign-extended to 64 bits. Note, ADDIW rd, rs1, 0 writes the sign-extension of the lower 32 bits of register rs1 into register rd (assembler pseudoinstruction SEXT.W).
31 26 | 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:6] | imm[5] | imm[4:0] | rs1 | funct3 | rd | opcode |
6 | 1 | 5 | 5 | 3 | 5 | 7 |
000000 | shamt[5] | shamt[4:0] | src | SLLI | dest | OP-IMM |
000000 | shamt[5] | shamt[4:0] | src | SRLI | dest | OP-IMM |
010000 | shamt[5] | shamt[4:0] | src | SRAI | dest | OP-IMM |
000000 | 0 | shamt[4:0] | src | SLLIW | dest | OP-IMM-32 |
000000 | 0 | shamt[4:0] | src | SRLIW | dest | OP-IMM-32 |
010000 | 0 | shamt[4:0] | src | SRAIW | dest | OP-IMM-32 |
Shifts by a constant are encoded as a specialization of the I-type format using the same instruction opcode as RV32I. The operand to be shifted is in rs1, and the shift amount is encoded in the lower 6 bits of the I-immediate field for RV64I. The right shift type is encoded in bit 30. SLLI is a logical left shift (zeros are shifted into the lower bits); SRLI is a logical right shift (zeros are shifted into the upper bits); and SRAI is an arithmetic right shift (the original sign bit is copied into the vacated upper bits).
SLLIW, SRLIW, and SRAIW are RV64I-only instructions that are analogously defined but operate on 32-bit values and sign-extend their 32-bit results to 64 bits. SLLIW, SRLIW, and SRAIW encodings with imm[5] ≠ 0 are reserved.
31 12 | 11 7 | 6 0 |
| imm[31:12] | rd | opcode |
20 | 5 | 7 |
U-immediate[31:12] | dest | LUI |
U-immediate[31:12] | dest | AUIPC
|
LUI (load upper immediate) uses the same opcode as RV32I. LUI places the 32-bit U-immediate into register rd, filling in the lowest 12 bits with zeros. The 32-bit result is sign-extended to 64 bits.
AUIPC (add upper immediate to pc) uses the same opcode as RV32I. AUIPC is used to build pc-relative addresses and uses the U-type format. AUIPC forms a 32-bit offset from the U-immediate, filling in the lowest 12 bits with zeros, sign-extends the result to 64 bits, adds it to the address of the AUIPC instruction, then places the result in register rd.
31 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct7 | rs2 | rs1 | funct3 | rd | opcode |
7 | 5 | 5 | 3 | 5 | 7 |
0000000 | src2 | src1 | SLL/SRL | dest | OP |
0100000 | src2 | src1 | SRA | dest | OP |
0000000 | src2 | src1 | ADDW | dest | OP-32 |
0000000 | src2 | src1 | SLLW/SRLW | dest | OP-32 |
0100000 | src2 | src1 | SUBW/SRAW | dest | OP-32 |
ADDW and SUBW are RV64I-only instructions that are defined analogously to ADD and SUB but operate on 32-bit values and produce signed 32-bit results. Overflows are ignored, and the low 32-bits of the result is sign-extended to 64-bits and written to the destination register.
SLL, SRL, and SRA perform logical left, logical right, and arithmetic right shifts on the value in register rs1 by the shift amount held in register rs2. In RV64I, only the low 6 bits of rs2 are considered for the shift amount.
SLLW, SRLW, and SRAW are RV64I-only instructions that are analogously defined but operate on 32-bit values and sign-extend their 32-bit results to 64 bits. The shift amount is given by rs2[4:0].
RV64I extends the address space to 64 bits. The execution environment will define what portions of the address space are legal to access.
31 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:0] | rs1 | funct3 | rd | opcode |
12 | 5 | 3 | 5 | 7 |
offset[11:0] | base | width | dest | LOAD |
31 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:5] | rs2 | rs1 | funct3 | imm[4:0] | opcode |
7 | 5 | 5 | 3 | 5 | 7 |
offset[11:5] | src | base | width | offset[4:0] | STORE |
The LD instruction loads a 64-bit value from memory into register rd for RV64I.
The LW instruction loads a 32-bit value from memory and sign-extends this to 64 bits before storing it in register rd for RV64I. The LWU instruction, on the other hand, zero-extends the 32-bit value from memory for RV64I. LH and LHU are defined analogously for 16-bit values, as are LB and LBU for 8-bit values. The SD, SW, SH, and SB instructions store 64-bit, 32-bit, 16-bit, and 8-bit values from the low bits of register rs2 to memory respectively.
All instructions that are microarchitectural HINTs in RV32I (see Section 3.9) are also HINTs in RV64I. The additional computational instructions in RV64I expand both the standard and custom HINT encoding spaces.
Table 8.1 lists all RV64I HINT code points. 91% of the HINT space is reserved for standard HINTs. The remainder of the HINT space is designated for custom HINTs: no standard HINTs will ever be defined in this subspace.
Instruction Constraints Code Points Purpose LUI rd=x0 220 11*Reserved for future standard use AUIPC rd=x0 220 2*ADDI rd=x0, and either 2*217−1 rs1≠x0 or imm≠0 ANDI rd=x0 217 ORI rd=x0 217 XORI rd=x0 217 ADDIW rd=x0 217 ADD rd=x0, rs1≠x0 210−32 2*ADD rd=x0, rs1=x0, 2*28 rs2≠x2–x5 4*ADD 4*[l]rd=x0, rs1=x0,
rs2=x2–x54*4 (rs2=x2) NTL.P1 (rs2=x3) NTL.PALL (rs2=x4) NTL.S1 (rs2=x5) NTL.ALL SUB rd=x0 210 22*Reserved for future standard use AND rd=x0 210 OR rd=x0 210 XOR rd=x0 210 SLL rd=x0 210 SRL rd=x0 210 SRA rd=x0 210 ADDW rd=x0 210 SUBW rd=x0 210 SLLW rd=x0 210 SRLW rd=x0 210 SRAW rd=x0 210 3*FENCE rd=x0, rs1≠x0, 3*210−63 fm=0, and either pred=0 or succ=0 3*FENCE rd≠x0, rs1=x0, 3*210−63 fm=0, and either pred=0 or succ=0 2*FENCE rd=rs1=x0, fm=0, 2*15 pred=0, succ≠0 2*FENCE rd=rs1=x0, fm=0, 2*15 pred≠W, succ=0 2*FENCE rd=rs1=x0, fm=0, 2*1 2*PAUSE pred=W, succ=0 SLTI rd=x0 217 10*Designated for custom use SLTIU rd=x0 217 SLLI rd=x0 211 SRLI rd=x0 211 SRAI rd=x0 211 SLLIW rd=x0 210 SRLIW rd=x0 210 SRAIW rd=x0 210 SLT rd=x0 210 SLTU rd=x0 210
Table 8.1: RV64I HINT instructions.
“There is only one mistake that can be made in computer design that is difficult to recover from—not having enough address bits for memory addressing and memory management.” Bell and Strecker, ISCA-3, 1976.
This chapter describes RV128I, a variant of the RISC-V ISA supporting a flat 128-bit address space. The variant is a straightforward extrapolation of the existing RV32I and RV64I designs.
History suggests that whenever it becomes clear that more than 64 bits of address space is needed, architects will repeat intensive debates about alternatives to extending the address space, including segmentation, 96-bit address spaces, and software workarounds, until, finally, flat 128-bit address spaces will be adopted as the simplest and best solution.
We have not frozen the RV128 spec at this time, as there might be need to evolve the design based on actual usage of 128-bit address spaces.
RV128I builds upon RV64I in the same way RV64I builds upon RV32I, with integer registers extended to 128 bits (i.e., XLEN=128). Most integer computational instructions are unchanged as they are defined to operate on XLEN bits. The RV64I “*W” integer instructions that operate on 32-bit values in the low bits of a register are retained but now sign extend their results from bit 31 to bit 127. A new set of “*D” integer instructions are added that operate on 64-bit values held in the low bits of the 128-bit integer registers and sign extend their results from bit 63 to bit 127. The “*D” instructions consume two major opcodes (OP-IMM-64 and OP-64) in the standard 32-bit encoding.
Shifts by an immediate (SLLI/SRLI/SRAI) are now encoded using the low 7 bits of the I-immediate, and variable shifts (SLL/SRL/SRA) use the low 7 bits of the shift amount source register.
A LDU (load double unsigned) instruction is added using the existing LOAD major opcode, along with new LQ and SQ instructions to load and store quadword values. SQ is added to the STORE major opcode, while LQ is added to the MISC-MEM major opcode.
The floating-point instruction set is unchanged, although the 128-bit Q floating-point extension can now support FMV.X.Q and FMV.Q.X instructions, together with additional FCVT instructions to and from the T (128-bit) integer format.
This chapter describes the standard integer multiplication and division instruction extension, which is named “M” and contains instructions that multiply or divide values held in two integer registers.
31 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct7 | rs2 | rs1 | funct3 | rd | opcode |
7 | 5 | 5 | 3 | 5 | 7 |
MULDIV | multiplier | multiplicand | MUL/MULH[[S]U] | dest | OP |
MULDIV | multiplier | multiplicand | MULW | dest | OP-32 |
MUL performs an XLEN-bit×XLEN-bit multiplication of rs1 by rs2 and places the lower XLEN bits in the destination register. MULH, MULHU, and MULHSU perform the same multiplication but return the upper XLEN bits of the full 2×XLEN-bit product, for signed×signed, unsigned×unsigned, and signed rs1×unsigned rs2 multiplication, respectively. If both the high and low bits of the same product are required, then the recommended code sequence is: MULH[[S]U] rdh, rs1, rs2; MUL rdl, rs1, rs2 (source register specifiers must be in same order and rdh cannot be the same as rs1 or rs2). Microarchitectures can then fuse these into a single multiply operation instead of performing two separate multiplies.
MULW is an RV64 instruction that multiplies the lower 32 bits of the source registers, placing the sign-extension of the lower 32 bits of the result into the destination register.
31 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct7 | rs2 | rs1 | funct3 | rd | opcode |
7 | 5 | 5 | 3 | 5 | 7 |
MULDIV | divisor | dividend | DIV[U]/REM[U] | dest | OP |
MULDIV | divisor | dividend | DIV[U]W/REM[U]W | dest | OP-32 |
DIV and DIVU perform an XLEN bits by XLEN bits signed and unsigned integer division of rs1 by rs2, rounding towards zero. REM and REMU provide the remainder of the corresponding division operation. For REM, the sign of the result equals the sign of the dividend.
If both the quotient and remainder are required from the same division, the recommended code sequence is: DIV[U] rdq, rs1, rs2; REM[U] rdr, rs1, rs2 (rdq cannot be the same as rs1 or rs2). Microarchitectures can then fuse these into a single divide operation instead of performing two separate divides.
DIVW and DIVUW are RV64 instructions that divide the lower 32 bits of rs1 by the lower 32 bits of rs2, treating them as signed and unsigned integers respectively, placing the 32-bit quotient in rd, sign-extended to 64 bits. REMW and REMUW are RV64 instructions that provide the corresponding signed and unsigned remainder operations respectively. Both REMW and REMUW always sign-extend the 32-bit result to 64 bits, including on a divide by zero.
The semantics for division by zero and division overflow are summarized in Table ??. The quotient of division by zero has all bits set, and the remainder of division by zero equals the dividend. Signed division overflow occurs only when the most-negative integer is divided by −1. The quotient of a signed division with overflow is equal to the dividend, and the remainder is zero. Unsigned division overflow cannot occur.
FIXME table missing during html conversion
The value of all bits set is returned for both unsigned and signed divide by zero to simplify the divider circuitry. The value of all 1s is both the natural value to return for unsigned divide, representing the largest unsigned number, and also the natural result for simple unsigned divider implementations. Signed division is often implemented using an unsigned division circuit and specifying the same overflow result simplifies the hardware.
The Zmmul extension implements the multiplication subset of the M extension. It adds all of the instructions defined in Section 10.1, namely: MUL, MULH, MULHU, MULHSU, and (for RV64 only) MULW. The encodings are identical to those of the corresponding M-extension instructions.
The standard atomic-instruction extension, named “A”, contains instructions that atomically read-modify-write memory to support synchronization between multiple RISC-V harts running in the same memory space. The two forms of atomic instruction provided are load-reserved/store-conditional instructions and atomic fetch-and-op memory instructions. Both types of atomic instruction support various memory consistency orderings including unordered, acquire, release, and sequentially consistent semantics. These instructions allow RISC-V to support the RCsc memory consistency model [].
The base RISC-V ISA has a relaxed memory model, with the FENCE instruction used to impose additional ordering constraints. The address space is divided by the execution environment into memory and I/O domains, and the FENCE instruction provides options to order accesses to one or both of these two address domains.
To provide more efficient support for release consistency [], each atomic instruction has two bits, aq and rl, used to specify additional memory ordering constraints as viewed by other RISC-V harts. The bits order accesses to one of the two address domains, memory or I/O, depending on which address domain the atomic instruction is accessing. No ordering constraint is implied to accesses to the other domain, and a FENCE instruction should be used to order across both domains.
If both bits are clear, no additional ordering constraints are imposed on the atomic memory operation. If only the aq bit is set, the atomic memory operation is treated as an acquire access, i.e., no following memory operations on this RISC-V hart can be observed to take place before the acquire memory operation. If only the rl bit is set, the atomic memory operation is treated as a release access, i.e., the release memory operation cannot be observed to take place before any earlier memory operations on this RISC-V hart. If both the aq and rl bits are set, the atomic memory operation is sequentially consistent and cannot be observed to happen before any earlier memory operations or after any later memory operations in the same RISC-V hart and to the same address domain.
31 27 | 26 | 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | aq | rl | rs2 | rs1 | funct3 | rd | opcode |
5 | 1 | 1 | 5 | 5 | 3 | 5 | 7 |
LR.W/D | ordering | 0 | addr | width | dest | AMO | |
SC.W/D | ordering | src | addr | width | dest | AMO | |
Complex atomic memory operations on a single memory word or doubleword are performed with the load-reserved (LR) and store-conditional (SC) instructions. LR.W loads a word from the address in rs1, places the sign-extended value in rd, and registers a reservation set—a set of bytes that subsumes the bytes in the addressed word. SC.W conditionally writes a word in rs2 to the address in rs1: the SC.W succeeds only if the reservation is still valid and the reservation set contains the bytes being written. If the SC.W succeeds, the instruction writes the word in rs2 to memory, and it writes zero to rd. If the SC.W fails, the instruction does not write to memory, and it writes a nonzero value to rd. Regardless of success or failure, executing an SC.W instruction invalidates any reservation held by this hart. LR.D and SC.D act analogously on doublewords and are only available on RV64. For RV64, LR.W and SC.W sign-extend the value placed in rd.
The main disadvantage of LR/SC over CAS is livelock, which we avoid, under certain circumstances, with an architected guarantee of eventual forward progress as described below. Another concern is whether the influence of the current x86 architecture, with its DW-CAS, will complicate porting of synchronization libraries and other software that assumes DW-CAS is the basic machine primitive. A possible mitigating factor is the recent addition of transactional memory instructions to x86, which might cause a move away from DW-CAS.
More generally, a multi-word atomic primitive is desirable, but there is still considerable debate about what form this should take, and guaranteeing forward progress adds complexity to a system.
The failure code with value 1 is reserved to encode an unspecified failure. Other failure codes are reserved at this time, and portable software should only assume the failure code will be non-zero.
For LR and SC, the A extension requires that the address held in rs1 be naturally aligned to the size of the operand (i.e., eight-byte aligned for 64-bit words and four-byte aligned for 32-bit words). If the address is not naturally aligned, an address-misaligned exception or an access-fault exception will be generated. The access-fault exception can be generated for a memory access that would otherwise be able to complete except for the misalignment, if the misaligned access should not be emulated.
Misaligned LR/SC sequences also raise the possibility of accessing multiple reservation sets at once, which present definitions do not provide for.
An implementation can register an arbitrarily large reservation set on each LR, provided the reservation set includes all bytes of the addressed data word or doubleword. An SC can only pair with the most recent LR in program order. An SC may succeed only if no store from another hart to the reservation set can be observed to have occurred between the LR and the SC, and if there is no other SC between the LR and itself in program order. An SC may succeed only if no write from a device other than a hart to the bytes accessed by the LR instruction can be observed to have occurred between the LR and SC. Note this LR might have had a different effective address and data size, but reserved the SC’s address as part of the reservation set.
The SC must fail if the address is not within the reservation set of the most recent LR in program order. The SC must fail if a store to the reservation set from another hart can be observed to occur between the LR and SC. The SC must fail if a write from some other device to the bytes accessed by the LR can be observed to occur between the LR and SC. (If such a device writes the reservation set but does not write the bytes accessed by the LR, the SC may or may not fail.) An SC must fail if there is another SC (to any address) between the LR and the SC in program order. The precise statement of the atomicity requirements for successful LR/SC sequences is defined by the Atomicity Axiom in Section 18.1.
A platform specification may constrain the size and shape of the reservation set. For example, the Unix platform is expected to require of main memory that the reservation set be of fixed size, contiguous, naturally aligned, and no greater than the virtual memory page size.
An SC instruction can never be observed by another RISC-V hart before the LR instruction that established the reservation. The LR/SC sequence can be given acquire semantics by setting the aq bit on the LR instruction. The LR/SC sequence can be given release semantics by setting the rl bit on the SC instruction. Setting the aq bit on the LR instruction, and setting both the aq and the rl bit on the SC instruction makes the LR/SC sequence sequentially consistent, meaning that it cannot be reordered with earlier or later memory operations from the same hart.
If neither bit is set on both LR and SC, the LR/SC sequence can be observed to occur before or after surrounding memory operations from the same RISC-V hart. This can be appropriate when the LR/SC sequence is used to implement a parallel reduction operation.
Software should not set the rl bit on an LR instruction unless the aq bit is also set, nor should software set the aq bit on an SC instruction unless the rl bit is also set. LR.rl and SC.aq instructions are not guaranteed to provide any stronger ordering than those with both bits clear, but may result in lower performance.
# a0 holds address of memory location # a1 holds expected value # a2 holds desired value # a0 holds return value, 0 if successful, !0 otherwise cas: lr.w t0, (a0) # Load original value. bne t0, a1, fail # Doesn't match, so fail. sc.w t0, a2, (a0) # Try to update. bnez t0, cas # Retry if store-conditional failed. li a0, 0 # Set return to success. jr ra # Return. fail: li a0, 1 # Set return to failure. jr ra # Return.
Figure 11.1: Sample code for compare-and-swap function using LR/SC.
LR/SC can be used to construct lock-free data structures. An example using LR/SC to implement a compare-and-swap function is shown in Figure 11.1. If inlined, compare-and-swap functionality need only take four instructions.
The standard A extension defines constrained LR/SC loops, which have the following properties:
LR/SC sequences that do not lie within constrained LR/SC loops are unconstrained. Unconstrained LR/SC sequences might succeed on some attempts on some implementations, but might never succeed on other implementations.
Software is not forbidden from using unconstrained LR/SC sequences, but portable software must detect the case that the sequence repeatedly fails, then fall back to an alternate code sequence that does not rely on an unconstrained LR/SC sequence. Implementations are permitted to unconditionally fail any unconstrained LR/SC sequence.
If a hart H enters a constrained LR/SC loop, the execution environment must guarantee that one of the following events eventually occurs:
Loads and load-reserved instructions do not by themselves impede the progress of other harts’ LR/SC sequences. We note this constraint implies, among other things, that loads and load-reserved instructions executed by other harts (possibly within the same core) cannot impede LR/SC progress indefinitely. For example, cache evictions caused by another hart sharing the cache cannot impede LR/SC progress indefinitely. Typically, this implies reservations are tracked independently of evictions from any shared cache. Similarly, cache misses caused by speculative execution within a hart cannot impede LR/SC progress indefinitely.
These definitions admit the possibility that SC instructions may spuriously fail for implementation reasons, provided progress is eventually made.
Earlier versions of this specification imposed a stronger starvation-freedom guarantee. However, the weaker livelock-freedom guarantee is sufficient to implement the C11 and C++11 languages, and is substantially easier to provide in some microarchitectural styles.
31 27 | 26 | 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | aq | rl | rs2 | rs1 | funct3 | rd | opcode |
5 | 1 | 1 | 5 | 5 | 3 | 5 | 7 |
AMOSWAP.W/D | ordering | src | addr | width | dest | AMO | |
AMOADD.W/D | ordering | src | addr | width | dest | AMO | |
AMOAND.W/D | ordering | src | addr | width | dest | AMO | |
AMOOR.W/D | ordering | src | addr | width | dest | AMO | |
AMOXOR.W/D | ordering | src | addr | width | dest | AMO | |
AMOMAX[U].W/D | ordering | src | addr | width | dest | AMO | |
AMOMIN[U].W/D | ordering | src | addr | width | dest | AMO | |
The atomic memory operation (AMO) instructions perform read-modify-write operations for multiprocessor synchronization and are encoded with an R-type instruction format. These AMO instructions atomically load a data value from the address in rs1, place the value into register rd, apply a binary operator to the loaded value and the original value in rs2, then store the result back to the original address in rs1. AMOs can either operate on 64-bit (RV64 only) or 32-bit words in memory. For RV64, 32-bit AMOs always sign-extend the value placed in rd, and ignore the upper 32 bits of the original value of rs2.
For AMOs, the A extension requires that the address held in rs1 be naturally aligned to the size of the operand (i.e., eight-byte aligned for 64-bit words and four-byte aligned for 32-bit words). If the address is not naturally aligned, an address-misaligned exception or an access-fault exception will be generated. The access-fault exception can be generated for a memory access that would otherwise be able to complete except for the misalignment, if the misaligned access should not be emulated. The “Zam” extension, described in Chapter 24, relaxes this requirement and specifies the semantics of misaligned AMOs.
The operations supported are swap, integer add, bitwise AND, bitwise OR, bitwise XOR, and signed and unsigned integer maximum and minimum. Without ordering constraints, these AMOs can be used to implement parallel reduction operations, where typically the return value would be discarded by writing to x0.
The set of AMOs was chosen to support the C11/C++11 atomic memory operations efficiently, and also to support parallel reductions in memory. Another use of AMOs is to provide atomic updates to memory-mapped device registers (e.g., setting, clearing, or toggling bits) in the I/O space.
To help implement multiprocessor synchronization, the AMOs optionally provide release consistency semantics. If the aq bit is set, then no later memory operations in this RISC-V hart can be observed to take place before the AMO. Conversely, if the rl bit is set, then other RISC-V harts will not observe the AMO before memory accesses preceding the AMO in this RISC-V hart. Setting both the aq and the rl bit on an AMO makes the sequence sequentially consistent, meaning that it cannot be reordered with earlier or later memory operations from the same hart.
An example code sequence for a critical section guarded by a test-and-test-and-set spinlock is shown in Figure 11.2. Note the first AMO is marked aq to order the lock acquisition before the critical section, and the second AMO is marked rl to order the critical section before the lock relinquishment.
li t0, 1 # Initialize swap value. again: lw t1, (a0) # Check if lock is held. bnez t1, again # Retry if held. amoswap.w.aq t1, t0, (a0) # Attempt to acquire lock. bnez t1, again # Retry if held. # ... # Critical section. # ... amoswap.w.rl x0, x0, (a0) # Release lock by storing 0.
Figure 11.2: Sample code for mutual exclusion. a0 contains the address of the lock.
The instructions in the “A” extension can also be used to provide sequentially consistent loads and stores. A sequentially consistent load can be implemented as an LR with both aq and rl set. A sequentially consistent store can be implemented as an AMOSWAP that writes the old value to x0 and has both aq and rl set.
RISC-V defines a separate address space of 4096 Control and Status registers associated with each hart. This chapter defines the full set of CSR instructions that operate on these CSRs.
The counters and timers are no longer considered mandatory parts of the standard base ISAs, and so the CSR instructions required to access them have been moved out of Chapter 3 into this separate chapter.
All CSR instructions atomically read-modify-write a single CSR, whose CSR specifier is encoded in the 12-bit csr field of the instruction held in bits 31–20. The immediate forms use a 5-bit zero-extended immediate encoded in the rs1 field.
31 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| csr | rs1 | funct3 | rd | opcode |
12 | 5 | 3 | 5 | 7 |
source/dest | source | CSRRW | dest | SYSTEM |
source/dest | source | CSRRS | dest | SYSTEM |
source/dest | source | CSRRC | dest | SYSTEM |
source/dest | uimm[4:0] | CSRRWI | dest | SYSTEM |
source/dest | uimm[4:0] | CSRRSI | dest | SYSTEM |
source/dest | uimm[4:0] | CSRRCI | dest | SYSTEM |
The CSRRW (Atomic Read/Write CSR) instruction atomically swaps values in the CSRs and integer registers. CSRRW reads the old value of the CSR, zero-extends the value to XLEN bits, then writes it to integer register rd. The initial value in rs1 is written to the CSR. If rd=x0, then the instruction shall not read the CSR and shall not cause any of the side effects that might occur on a CSR read.
The CSRRS (Atomic Read and Set Bits in CSR) instruction reads the value of the CSR, zero-extends the value to XLEN bits, and writes it to integer register rd. The initial value in integer register rs1 is treated as a bit mask that specifies bit positions to be set in the CSR. Any bit that is high in rs1 will cause the corresponding bit to be set in the CSR, if that CSR bit is writable. Other bits in the CSR are not explicitly written.
The CSRRC (Atomic Read and Clear Bits in CSR) instruction reads the value of the CSR, zero-extends the value to XLEN bits, and writes it to integer register rd. The initial value in integer register rs1 is treated as a bit mask that specifies bit positions to be cleared in the CSR. Any bit that is high in rs1 will cause the corresponding bit to be cleared in the CSR, if that CSR bit is writable. Other bits in the CSR are not explicitly written.
For both CSRRS and CSRRC, if rs1=x0, then the instruction will not write to the CSR at all, and so shall not cause any of the side effects that might otherwise occur on a CSR write, nor raise illegal instruction exceptions on accesses to read-only CSRs. Both CSRRS and CSRRC always read the addressed CSR and cause any read side effects regardless of rs1 and rd fields. Note that if rs1 specifies a register holding a zero value other than x0, the instruction will still attempt to write the unmodified value back to the CSR and will cause any attendant side effects. A CSRRW with rs1=x0 will attempt to write zero to the destination CSR.
The CSRRWI, CSRRSI, and CSRRCI variants are similar to CSRRW, CSRRS, and CSRRC respectively, except they update the CSR using an XLEN-bit value obtained by zero-extending a 5-bit unsigned immediate (uimm[4:0]) field encoded in the rs1 field instead of a value from an integer register. For CSRRSI and CSRRCI, if the uimm[4:0] field is zero, then these instructions will not write to the CSR, and shall not cause any of the side effects that might otherwise occur on a CSR write, nor raise illegal instruction exceptions on accesses to read-only CSRs. For CSRRWI, if rd=x0, then the instruction shall not read the CSR and shall not cause any of the side effects that might occur on a CSR read. Both CSRRSI and CSRRCI will always read the CSR and cause any read side effects regardless of rd and rs1 fields.
Register operand Instruction rd is x0 rs1 is x0 Reads CSR Writes CSR CSRRW Yes – No Yes CSRRW No – Yes Yes CSRRS/CSRRC – Yes Yes No CSRRS/CSRRC – No Yes Yes Immediate operand Instruction rd is x0 uimm=0 Reads CSR Writes CSR CSRRWI Yes – No Yes CSRRWI No – Yes Yes CSRRSI/CSRRCI – Yes Yes No CSRRSI/CSRRCI – No Yes Yes
Table 12.1: Conditions determining whether a CSR instruction reads or writes the specified CSR.
Table 12.1 summarizes the behavior of the CSR instructions with respect to whether they read and/or write the CSR.
For any event or consequence that occurs due to a CSR having a particular value, if a write to the CSR gives it that value, the resulting event or consequence is said to be an indirect effect of the write. Indirect effects of a CSR write are not considered by the RISC-V ISA to be side effects of that write.
On the other hand, if a bulb is rigged to light whenever the value of a particular CSR is odd, then turning the light on and off is not considered a side effect of writing to the CSR but merely an indirect effect of such writes.
More concretely, the RISC-V privileged architecture defined in Volume II specifies that certain combinations of CSR values cause a trap to occur. When an explicit write to a CSR creates the conditions that trigger the trap, the trap is not considered a side effect of the write but merely an indirect effect.
Standard CSRs do not have any side effects on reads. Standard CSRs may have side effects on writes. Custom extensions might add CSRs for which accesses have side effects on either reads or writes.
Some CSRs, such as the instructions-retired counter, instret, may be modified as side effects of instruction execution. In these cases, if a CSR access instruction reads a CSR, it reads the value prior to the execution of the instruction. If a CSR access instruction writes such a CSR, the write is done instead of the increment. In particular, a value written to instret by one instruction will be the value read by the following instruction.
The assembler pseudoinstruction to read a CSR, CSRR rd, csr, is encoded as CSRRS rd, csr, x0. The assembler pseudoinstruction to write a CSR, CSRW csr, rs1, is encoded as CSRRW x0, csr, rs1, while CSRWI csr, uimm, is encoded as CSRRWI x0, csr, uimm.
Further assembler pseudoinstructions are defined to set and clear bits in the CSR when the old value is not required: CSRS/CSRC csr, rs1; CSRSI/CSRCI csr, uimm.
Each RISC-V hart normally observes its own CSR accesses, including its implicit CSR accesses, as performed in program order. In particular, unless specified otherwise, a CSR access is performed after the execution of any prior instructions in program order whose behavior modifies or is modified by the CSR state and before the execution of any subsequent instructions in program order whose behavior modifies or is modified by the CSR state. Furthermore, an explicit CSR read returns the CSR state before the execution of the instruction, while an explicit CSR write suppresses and overrides any implicit writes or modifications to the same CSR by the same instruction.
Likewise, any side effects from an explicit CSR access are normally observed to occur synchronously in program order. Unless specified otherwise, the full consequences of any such side effects are observable by the very next instruction, and no consequences may be observed out-of-order by preceding instructions. (Note the distinction made earlier between side effects and indirect effects of CSR writes.)
For the RVWMO memory consistency model (Chapter 18), CSR accesses are weakly ordered by default, so other harts or devices may observe CSR accesses in an order different from program order. In addition, CSR accesses are not ordered with respect to explicit memory accesses, unless a CSR access modifies the execution behavior of the instruction that performs the explicit memory access or unless a CSR access and an explicit memory access are ordered by either the syntactic dependencies defined by the memory model or the ordering requirements defined by the Memory-Ordering PMAs section in Volume II of this manual. To enforce ordering in all other cases, software should execute a FENCE instruction between the relevant accesses. For the purposes of the FENCE instruction, CSR read accesses are classified as device input (I), and CSR write accesses are classified as device output (O).
These CSR-ordering constraints are imposed to support ordering main memory and memory-mapped I/O accesses with respect to CSR accesses that are visible to, or affected by, devices or other harts. Examples include the time, cycle, and mcycle CSRs, in addition to CSRs that reflect pending interrupts, like mip and sip. Note that implicit reads of such CSRs (e.g., taking an interrupt because of a change in mip) are also ordered as device input.
Most CSRs (including, e.g., the fcsr) are not visible to other harts; their accesses can be freely reordered in the global memory order with respect to FENCE instructions without violating this specification.
The hardware platform may define that accesses to certain CSRs are strongly ordered, as defined by the Memory-Ordering PMAs section in Volume II of this manual. Accesses to strongly ordered CSRs have stronger ordering constraints with respect to accesses to both weakly ordered CSRs and accesses to memory-mapped I/O regions.
RISC-V ISAs provide a set of up to 32×64-bit performance counters and timers that are accessible via unprivileged XLEN-bit read-only CSR registers 0xC00–0xC1F (with the upper 32 bits accessed via CSR registers 0xC80–0xC9F on RV32). These counters are divided between the “Zicntr” and “Zihpm” extensions.
The Zicntr standard extension comprises the first three of these counters (CYCLE, TIME, and INSTRET), which have dedicated functions (cycle count, real-time clock, and instructions retired, respectively). The Zicntr extension depends on the Zicsr extension.
31 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| csr | rs1 | funct3 | rd | opcode |
12 | 5 | 3 | 5 | 7 |
RDCYCLE[H] | 0 | CSRRS | dest | SYSTEM |
RDTIME[H] | 0 | CSRRS | dest | SYSTEM |
RDINSTRET[H] | 0 | CSRRS | dest | SYSTEM |
RV32I provides a number of 64-bit read-only user-level counters, which are mapped into the 12-bit CSR address space and accessed in 32-bit pieces using CSRRS instructions. In RV64I, the CSR instructions can manipulate 64-bit CSRs. In particular, the RDCYCLE, RDTIME, and RDINSTRET pseudoinstructions read the full 64 bits of the cycle, time, and instret counters. Hence, the RDCYCLEH, RDTIMEH, and RDINSTRETH instructions are RV32I-only.
The RDCYCLE pseudoinstruction reads the low XLEN bits of the cycle CSR which holds a count of the number of clock cycles executed by the processor core on which the hart is running from an arbitrary start time in the past. RDCYCLEH is an RV32I-only instruction that reads bits 63–32 of the same cycle counter. The underlying 64-bit counter should never overflow in practice. The rate at which the cycle counter advances will depend on the implementation and operating environment. The execution environment should provide a means to determine the current rate (cycles/second) at which the cycle counter is incrementing.
Cores don’t have to be exposed to software at all, and an implementor might choose to pretend multiple harts on one physical core are running on separate cores with one hart/core, and provide separate cycle counters for each hart. This might make sense in a simple barrel processor (e.g., CDC 6600 peripheral processors) where inter-hart timing interactions are non-existent or minimal.
Where there is more than one hart/core and dynamic multithreading, it is not generally possible to separate out cycles per hart (especially with SMT). It might be possible to define a separate performance counter that tried to capture the number of cycles a particular hart was running, but this definition would have to be very fuzzy to cover all the possible threading implementations. For example, should we only count cycles for which any instruction was issued to execution for this hart, and/or cycles any instruction retired, or include cycles this hart was occupying machine resources but couldn’t execute due to stalls while other harts went into execution? Likely, “all of the above” would be needed to have understandable performance stats. This complexity of defining a per-hart cycle count, and also the need in any case for a total per-core cycle count when tuning multithreaded code led to just standardizing the per-core cycle counter, which also happens to work well for the common single hart/core case.
Standardizing what happens during “sleep” is not practical given that what “sleep” means is not standardized across execution environments, but if the entire core is paused (entirely clock-gated or powered-down in deep sleep), then it is not executing clock cycles, and the cycle count shouldn’t be increasing per the spec. There are many details, e.g., whether clock cycles required to reset a processor after waking up from a power-down event should be counted, and these are considered execution-environment-specific details.
Even though there is no precise definition that works for all platforms, this is still a useful facility for most platforms, and an imprecise, common, “usually correct” standard here is better than no standard. The intent of RDCYCLE was primarily performance monitoring/tuning, and the specification was written with that goal in mind.
The RDTIME pseudoinstruction reads the low XLEN bits of the time CSR, which counts wall-clock real time that has passed from an arbitrary start time in the past. RDTIMEH is an RV32I-only instruction that reads bits 63–32 of the same real-time counter. The underlying 64-bit counter increments by one with each tick of the real-time clock, and, for realistic real-time clock frequencies, should never overflow in practice. The execution environment should provide a means of determining the period of a counter tick (seconds/tick). The period must be constant. The real-time clocks of all harts in a single user application should be synchronized to within one tick of the real-time clock. The environment should provide a means to determine the accuracy of the clock (i.e., the maximum relative error between the nominal and actual real-time clock periods).
The RDINSTRET pseudoinstruction reads the low XLEN bits of the instret CSR, which counts the number of instructions retired by this hart from some arbitrary start point in the past. RDINSTRETH is an RV32I-only instruction that reads bits 63–32 of the same instruction counter. The underlying 64-bit counter should never overflow in practice.
The following code sequence will read a valid 64-bit cycle counter value into x3:x2, even if the counter overflows its lower half between reading its upper and lower halves.
again: rdcycleh x3 rdcycle x2 rdcycleh x4 bne x3, x4, again
Figure 13.1: Sample code for reading the 64-bit cycle counter in RV32.
We required the counters be 64 bits wide, even on RV32, as otherwise it is very difficult for software to determine if values have overflowed. For a low-end implementation, the upper 32 bits of each counter can be implemented using software counters incremented by a trap handler triggered by overflow of the lower 32 bits. The sample code described above shows how the full 64-bit width value can be safely read using the individual 32-bit instructions.
In some applications, it is important to be able to read multiple counters at the same instant in time. When run under a multitasking environment, a user thread can suffer a context switch while attempting to read the counters. One solution is for the user thread to read the real-time counter before and after reading the other counters to determine if a context switch occurred in the middle of the sequence, in which case the reads can be retried. We considered adding output latches to allow a user thread to snapshot the counter values atomically, but this would increase the size of the user context, especially for implementations with a richer set of counters.
The Zihpm extension comprises the 29 additional unprivileged 64-bit hardware performance counters, hpmcounter3–hpmcounter31. For RV32, the upper 32 bits of these performance counters are accessible via additional CSRs hpmcounter3h–hpmcounter31h. These counters count platform-specific events and are configured via additional privileged registers. The number and width of these additional counters, and the set of events they count, is platform-specific. The Zihpm extension depends on the Zicsr extension.
It would be useful to eventually standardize event settings to count ISA-level metrics, such as the number of floating-point instructions executed for example, and possibly a few common microarchitectural metrics, such as “L1 instruction cache misses”.
This chapter describes the standard instruction-set extension for single-precision floating-point, which is named “F” and adds single-precision floating-point computational instructions compliant with the IEEE 754-2008 arithmetic standard []. The F extension depends on the “Zicsr” extension for control and status register access.
The F extension adds 32 floating-point registers, f0–f31, each 32 bits wide, and a floating-point control and status register fcsr, which contains the operating mode and exception status of the floating-point unit. This additional state is shown in Figure 14.1. We use the term FLEN to describe the width of the floating-point registers in the RISC-V ISA, and FLEN=32 for the F single-precision floating-point extension. Most floating-point instructions operate on values in the floating-point register file. Floating-point load and store instructions transfer floating-point values between registers and memory. Instructions to transfer values to and from the integer register file are also provided.
FLEN-1 0 f0 f1 f2 f3 f4 f5 f6 f7 f8 f9 f10 f11 f12 f13 f14 f15 f16 f17 f18 f19 f20 f21 f22 f23 f24 f25 f26 f27 f28 f29 f30 f31 FLEN 31 0 fcsr 32
Figure 14.1: RISC-V standard F extension single-precision floating-point state.
The floating-point control and status register, fcsr, is a RISC-V control and status register (CSR). It is a 32-bit read/write register that selects the dynamic rounding mode for floating-point arithmetic operations and holds the accrued exception flags, as shown in Figure 14.2.
4 3 2 1 0 Reserved Rounding Mode (frm) Accrued Exceptions (fflags) NV DZ OF UF NX 1 1 1 1 1
Figure 14.2: Floating-point control and status register.
The fcsr register can be read and written with the FRCSR and FSCSR instructions, which are assembler pseudoinstructions built on the underlying CSR access instructions. FRCSR reads fcsr by copying it into integer register rd. FSCSR swaps the value in fcsr by copying the original value into integer register rd, and then writing a new value obtained from integer register rs1 into fcsr.
The fields within the fcsr can also be accessed individually through different CSR addresses, and separate assembler pseudoinstructions are defined for these accesses. The FRRM instruction reads the Rounding Mode field frm and copies it into the least-significant three bits of integer register rd, with zero in all other bits. FSRM swaps the value in frm by copying the original value into integer register rd, and then writing a new value obtained from the three least-significant bits of integer register rs1 into frm. FRFLAGS and FSFLAGS are defined analogously for the Accrued Exception Flags field fflags.
Bits 31–8 of the fcsr are reserved for other standard extensions. If these extensions are not present, implementations shall ignore writes to these bits and supply a zero value when read. Standard software should preserve the contents of these bits.
Floating-point operations use either a static rounding mode encoded in the instruction, or a dynamic rounding mode held in frm. Rounding modes are encoded as shown in Table 14.1. A value of 111 in the instruction’s rm field selects the dynamic rounding mode held in frm. The behavior of floating-point instructions that depend on rounding mode when executed with a reserved rounding mode is reserved, including both static reserved rounding modes (101–110) and dynamic reserved rounding modes (101–111). Some instructions, including widening conversions, have the rm field but are nevertheless mathematically unaffected by the rounding mode; software should set their rm field to RNE (000) but implementations must treat the rm field as usual (in particular, with regard to decoding legal vs. reserved encodings).
Rounding Mode Mnemonic Meaning 000 RNE Round to Nearest, ties to Even 001 RTZ Round towards Zero 010 RDN Round Down (towards −∞) 011 RUP Round Up (towards +∞) 100 RMM Round to Nearest, ties to Max Magnitude 101 Reserved for future use. 110 Reserved for future use. 111 DYN In instruction’s rm field, selects dynamic rounding mode; In Rounding Mode register, reserved.
Table 14.1: Rounding mode encoding.
The ratified version of the F spec mandated that an illegal instruction exception was raised when an instruction was executed with a reserved dynamic rounding mode. This has been weakened to reserved, which matches the behavior of static rounding-mode instructions. Raising an illegal instruction exception is still valid behavior when encountering a reserved encoding, so implementations compatible with the ratified spec are compatible with the weakened spec.
The accrued exception flags indicate the exception conditions that have arisen on any floating-point arithmetic instruction since the field was last reset by software, as shown in Table 14.2. The base RISC-V ISA does not support generating a trap on the setting of a floating-point exception flag.
Flag Mnemonic Flag Meaning NV Invalid Operation DZ Divide by Zero OF Overflow UF Underflow NX Inexact
Table 14.2: Accrued exception flag encoding.
Except when otherwise stated, if the result of a floating-point operation is NaN, it is the canonical NaN. The canonical NaN has a positive sign and all significand bits clear except the MSB, a.k.a. the quiet bit. For single-precision floating-point, this corresponds to the pattern 0x7fc00000.
Implementors are free to provide a NaN payload propagation scheme as a nonstandard extension enabled by a nonstandard operating mode. However, the canonical NaN scheme described above must always be supported and should be the default mode.
Operations on subnormal numbers are handled in accordance with the IEEE 754-2008 standard.
In the parlance of the IEEE standard, tininess is detected after rounding.
Floating-point loads and stores use the same base+offset addressing mode as the integer base ISAs, with a base address in register rs1 and a 12-bit signed byte offset. The FLW instruction loads a single-precision floating-point value from memory into floating-point register rd. FSW stores a single-precision value from floating-point register rs2 to memory.
31 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:0] | rs1 | width | rd | opcode |
12 | 5 | 3 | 5 | 7 |
offset[11:0] | base | W | dest | LOAD-FP |
31 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:5] | rs2 | rs1 | width | imm[4:0] | opcode |
7 | 5 | 5 | 3 | 5 | 7 |
offset[11:5] | src | base | W | offset[4:0] | STORE-FP |
FLW and FSW are only guaranteed to execute atomically if the effective address is naturally aligned.
FLW and FSW do not modify the bits being transferred; in particular, the payloads of non-canonical NaNs are preserved.
As described in Section 3.6, the EEI defines whether misaligned floating-point loads and stores are handled invisibly or raise a contained or fatal trap.
Floating-point arithmetic instructions with one or two source operands use the R-type format with the OP-FP major opcode. FADD.S and FMUL.S perform single-precision floating-point addition and multiplication respectively, between rs1 and rs2. FSUB.S performs the single-precision floating-point subtraction of rs2 from rs1. FDIV.S performs the single-precision floating-point division of rs1 by rs2. FSQRT.S computes the square root of rs1. In each case, the result is written to rd.
The 2-bit floating-point format field fmt is encoded as shown in Table 14.3. It is set to S (00) for all instructions in the F extension.
fmt field Mnemonic Meaning 00 S 32-bit single-precision 01 D 64-bit double-precision 10 H 16-bit half-precision 11 Q 128-bit quad-precision
Table 14.3: Format field encoding.
All floating-point operations that perform rounding can select the rounding mode using the rm field with the encoding shown in Table 14.1.
Floating-point minimum-number and maximum-number instructions FMIN.S and FMAX.S write, respectively, the smaller or larger of rs1 and rs2 to rd. For the purposes of these instructions only, the value −0.0 is considered to be less than the value +0.0. If both inputs are NaNs, the result is the canonical NaN. If only one operand is a NaN, the result is the non-NaN operand. Signaling NaN inputs set the invalid operation exception flag, even when the result is not NaN.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FADD/FSUB | S | src2 | src1 | RM | dest | OP-FP |
FMUL/FDIV | S | src2 | src1 | RM | dest | OP-FP |
FSQRT | S | 0 | src | RM | dest | OP-FP |
FMIN-MAX | S | src2 | src1 | MIN/MAX | dest | OP-FP |
Floating-point fused multiply-add instructions require a new standard instruction format. R4-type instructions specify three source registers (rs1, rs2, and rs3) and a destination register (rd). This format is only used by the floating-point fused multiply-add instructions.
FMADD.S multiplies the values in rs1 and rs2, adds the value in rs3, and writes the final result to rd. FMADD.S computes (rs1×rs2)+rs3.
FMSUB.S multiplies the values in rs1 and rs2, subtracts the value in rs3, and writes the final result to rd. FMSUB.S computes (rs1×rs2)-rs3.
FNMSUB.S multiplies the values in rs1 and rs2, negates the product, adds the value in rs3, and writes the final result to rd. FNMSUB.S computes -(rs1×rs2)+rs3.
FNMADD.S multiplies the values in rs1 and rs2, negates the product, subtracts the value in rs3, and writes the final result to rd. FNMADD.S computes -(rs1×rs2)-rs3.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| rs3 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
src3 | S | src2 | src1 | RM | dest | F[N]MADD/F[N]MSUB |
The fused multiply-add instructions must set the invalid operation exception flag when the multiplicands are ∞ and zero, even when the addend is a quiet NaN.
Floating-point-to-integer and integer-to-floating-point conversion instructions are encoded in the OP-FP major opcode space. FCVT.W.S or FCVT.L.S converts a floating-point number in floating-point register rs1 to a signed 32-bit or 64-bit integer, respectively, in integer register rd. FCVT.S.W or FCVT.S.L converts a 32-bit or 64-bit signed integer, respectively, in integer register rs1 into a floating-point number in floating-point register rd. FCVT.WU.S, FCVT.LU.S, FCVT.S.WU, and FCVT.S.LU variants convert to or from unsigned integer values. For XLEN>32, FCVT.W[U].S sign-extends the 32-bit result to the destination register width. FCVT.L[U].S and FCVT.S.L[U] are RV64-only instructions. If the rounded result is not representable in the destination format, it is clipped to the nearest value and the invalid flag is set. Table 14.4 gives the range of valid inputs for FCVT.int.S and the behavior for invalid inputs.
FCVT.W.S FCVT.WU.S FCVT.L.S FCVT.LU.S Minimum valid input (after rounding) −231 0 −263 0 Maximum valid input (after rounding) 231−1 232−1 263−1 264−1 Output for out-of-range negative input −231 0 −263 0 Output for −∞ −231 0 −263 0 Output for out-of-range positive input 231−1 232−1 263−1 264−1 Output for +∞ or NaN 231−1 232−1 263−1 264−1
Table 14.4: Domains of float-to-integer conversions and behavior for invalid inputs.
All floating-point to integer and integer to floating-point conversion instructions round according to the rm field. A floating-point register can be initialized to floating-point positive zero using FCVT.S.W rd, x0, which will never set any exception flags.
All floating-point conversion instructions set the Inexact exception flag if the rounded result differs from the operand value and the Invalid exception flag is not set.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCVT.int.fmt | S | W[U]/L[U] | src | RM | dest | OP-FP |
FCVT.fmt.int | S | W[U]/L[U] | src | RM | dest | OP-FP |
Floating-point to floating-point sign-injection instructions, FSGNJ.S, FSGNJN.S, and FSGNJX.S, produce a result that takes all bits except the sign bit from rs1. For FSGNJ, the result’s sign bit is rs2’s sign bit; for FSGNJN, the result’s sign bit is the opposite of rs2’s sign bit; and for FSGNJX, the sign bit is the XOR of the sign bits of rs1 and rs2. Sign-injection instructions do not set floating-point exception flags, nor do they canonicalize NaNs. Note, FSGNJ.S rx, ry, ry moves ry to rx (assembler pseudoinstruction FMV.S rx, ry); FSGNJN.S rx, ry, ry moves the negation of ry to rx (assembler pseudoinstruction FNEG.S rx, ry); and FSGNJX.S rx, ry, ry moves the absolute value of ry to rx (assembler pseudoinstruction FABS.S rx, ry).
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FSGNJ | S | src2 | src1 | J[N]/JX | dest | OP-FP |
Instructions are provided to move bit patterns between the floating-point and integer registers. FMV.X.W moves the single-precision value in floating-point register rs1 represented in IEEE 754-2008 encoding to the lower 32 bits of integer register rd. The bits are not modified in the transfer, and in particular, the payloads of non-canonical NaNs are preserved. For RV64, the higher 32 bits of the destination register are filled with copies of the floating-point number’s sign bit.
FMV.W.X moves the single-precision value encoded in IEEE 754-2008 standard encoding from the lower 32 bits of integer register rs1 to the floating-point register rd. The bits are not modified in the transfer, and in particular, the payloads of non-canonical NaNs are preserved.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FMV.X.W | S | 0 | src | 000 | dest | OP-FP |
FMV.W.X | S | 0 | src | 000 | dest | OP-FP |
Floating-point compare instructions (FEQ.S, FLT.S, FLE.S) perform the specified comparison between floating-point registers (rs1 = rs2, rs1 < rs2, rs1 ≤ rs2) writing 1 to the integer register rd if the condition holds, and 0 otherwise.
FLT.S and FLE.S perform what the IEEE 754-2008 standard refers to as signaling comparisons: that is, they set the invalid operation exception flag if either input is NaN. FEQ.S performs a quiet comparison: it only sets the invalid operation exception flag if either input is a signaling NaN. For all three instructions, the result is 0 if either operand is NaN.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCMP | S | src2 | src1 | EQ/LT/LE | dest | OP-FP |
The FCLASS.S instruction examines the value in floating-point register rs1 and writes to integer register rd a 10-bit mask that indicates the class of the floating-point number. The format of the mask is described in Table 14.5. The corresponding bit in rd will be set if the property is true and clear otherwise. All other bits in rd are cleared. Note that exactly one bit in rd will be set. FCLASS.S does not set the floating-point exception flags.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCLASS | S | 0 | src | 001 | dest | OP-FP |
rd bit Meaning 0 rs1 is −∞. 1 rs1 is a negative normal number. 2 rs1 is a negative subnormal number. 3 rs1 is −0. 4 rs1 is +0. 5 rs1 is a positive subnormal number. 6 rs1 is a positive normal number. 7 rs1 is +∞. 8 rs1 is a signaling NaN. 9 rs1 is a quiet NaN.
Table 14.5: Format of result of FCLASS instruction.
This chapter describes the standard double-precision floating-point instruction-set extension, which is named “D” and adds double-precision floating-point computational instructions compliant with the IEEE 754-2008 arithmetic standard. The D extension depends on the base single-precision instruction subset F.
The D extension widens the 32 floating-point registers, f0–f31, to 64 bits (FLEN=64 in Figure 14.1). The f registers can now hold either 32-bit or 64-bit floating-point values as described below in Section 15.2.
When multiple floating-point precisions are supported, then valid values of narrower n-bit types, n< FLEN, are represented in the lower n bits of an FLEN-bit NaN value, in a process termed NaN-boxing. The upper bits of a valid NaN-boxed value must be all 1s. Valid NaN-boxed n-bit values therefore appear as negative quiet NaNs (qNaNs) when viewed as any wider m-bit value, n < m ≤ FLEN. Any operation that writes a narrower result to an f register must write all 1s to the uppermost FLEN−n bits to yield a legal NaN-boxed value.
Floating-point n-bit transfer operations move external values held in IEEE standard formats into and out of the f registers, and comprise floating-point loads and stores (FLn/FSn) and floating-point move instructions (FMV.n.X/FMV.X.n). A narrower n-bit transfer, n< FLEN, into the f registers will create a valid NaN-boxed value. A narrower n-bit transfer out of the floating-point registers will transfer the lower n bits of the register ignoring the upper FLEN−n bits.
Apart from transfer operations described in the previous paragraph, all other floating-point operations on narrower n-bit operations, n< FLEN, check if the input operands are correctly NaN-boxed, i.e., all upper FLEN−n bits are 1. If so, the n least-significant bits of the input are used as the input value, otherwise the input value is treated as an n-bit canonical NaN.
Non-recoded implementations unpack and pack the operands to IEEE standard format on the input and output of every floating-point operation. The NaN-boxing cost to a non-recoded implementation is primarily in checking if the upper bits of a narrower operation represent a legal NaN-boxed value, and in writing all 1s to the upper bits of a result.
Recoded implementations use a more convenient internal format to represent floating-point values, with an added exponent bit to allow all values to be held normalized. The cost to the recoded implementation is primarily the extra tagging needed to track the internal types and sign bits, but this can be done without adding new state bits by recoding NaNs internally in the exponent field. Small modifications are needed to the pipelines used to transfer values in and out of the recoded format, but the datapath and latency costs are minimal. The recoding process has to handle shifting of input subnormal values for wide operands in any case, and extracting the NaN-boxed value is a similar process to normalization except for skipping over leading-1 bits instead of skipping over leading-0 bits, allowing the datapath muxing to be shared.
The FLD instruction loads a double-precision floating-point value from memory into floating-point register rd. FSD stores a double-precision value from the floating-point registers to memory.
31 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:0] | rs1 | width | rd | opcode |
12 | 5 | 3 | 5 | 7 |
offset[11:0] | base | D | dest | LOAD-FP |
31 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:5] | rs2 | rs1 | width | imm[4:0] | opcode |
7 | 5 | 5 | 3 | 5 | 7 |
offset[11:5] | src | base | D | offset[4:0] | STORE-FP |
FLD and FSD are only guaranteed to execute atomically if the effective address is naturally aligned and XLEN≥64.
FLD and FSD do not modify the bits being transferred; in particular, the payloads of non-canonical NaNs are preserved.
The double-precision floating-point computational instructions are defined analogously to their single-precision counterparts, but operate on double-precision operands and produce double-precision results.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FADD/FSUB | D | src2 | src1 | RM | dest | OP-FP |
FMUL/FDIV | D | src2 | src1 | RM | dest | OP-FP |
FMIN-MAX | D | src2 | src1 | MIN/MAX | dest | OP-FP |
FSQRT | D | 0 | src | RM | dest | OP-FP |
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| rs3 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
src3 | D | src2 | src1 | RM | dest | F[N]MADD/F[N]MSUB |
Floating-point-to-integer and integer-to-floating-point conversion instructions are encoded in the OP-FP major opcode space. FCVT.W.D or FCVT.L.D converts a double-precision floating-point number in floating-point register rs1 to a signed 32-bit or 64-bit integer, respectively, in integer register rd. FCVT.D.W or FCVT.D.L converts a 32-bit or 64-bit signed integer, respectively, in integer register rs1 into a double-precision floating-point number in floating-point register rd. FCVT.WU.D, FCVT.LU.D, FCVT.D.WU, and FCVT.D.LU variants convert to or from unsigned integer values. For RV64, FCVT.W[U].D sign-extends the 32-bit result. FCVT.L[U].D and FCVT.D.L[U] are RV64-only instructions. The range of valid inputs for FCVT.int.D and the behavior for invalid inputs are the same as for FCVT.int.S.
All floating-point to integer and integer to floating-point conversion instructions round according to the rm field. Note FCVT.D.W[U] always produces an exact result and is unaffected by rounding mode.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCVT.int.D | D | W[U]/L[U] | src | RM | dest | OP-FP |
FCVT.D.int | D | W[U]/L[U] | src | RM | dest | OP-FP |
The double-precision to single-precision and single-precision to double-precision conversion instructions, FCVT.S.D and FCVT.D.S, are encoded in the OP-FP major opcode space and both the source and destination are floating-point registers. The rs2 field encodes the datatype of the source, and the fmt field encodes the datatype of the destination. FCVT.S.D rounds according to the RM field; FCVT.D.S will never round.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCVT.S.D | S | D | src | RM | dest | OP-FP |
FCVT.D.S | D | S | src | RM | dest | OP-FP |
Floating-point to floating-point sign-injection instructions, FSGNJ.D, FSGNJN.D, and FSGNJX.D are defined analogously to the single-precision sign-injection instruction.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FSGNJ | D | src2 | src1 | J[N]/JX | dest | OP-FP |
For XLEN≥64 only, instructions are provided to move bit patterns between the floating-point and integer registers. FMV.X.D moves the double-precision value in floating-point register rs1 to a representation in IEEE 754-2008 standard encoding in integer register rd. FMV.D.X moves the double-precision value encoded in IEEE 754-2008 standard encoding from the integer register rs1 to the floating-point register rd.
FMV.X.D and FMV.D.X do not modify the bits being transferred; in particular, the payloads of non-canonical NaNs are preserved.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FMV.X.D | D | 0 | src | 000 | dest | OP-FP |
FMV.D.X | D | 0 | src | 000 | dest | OP-FP |
We note that for systems that implement a 64-bit floating-point unit including fused multiply-add support and 64-bit floating-point loads and stores, the marginal hardware cost of moving from a 32-bit to a 64-bit integer datapath is low, and a software ABI supporting 32-bit wide address-space and pointers can be used to avoid growth of static data and dynamic memory traffic.
The double-precision floating-point compare instructions are defined analogously to their single-precision counterparts, but operate on double-precision operands.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCMP | D | src2 | src1 | EQ/LT/LE | dest | OP-FP |
The double-precision floating-point classify instruction, FCLASS.D, is defined analogously to its single-precision counterpart, but operates on double-precision operands.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCLASS | D | 0 | src | 001 | dest | OP-FP |
This chapter describes the Q standard extension for 128-bit quad-precision binary floating-point instructions compliant with the IEEE 754-2008 arithmetic standard. The quad-precision binary floating-point instruction-set extension is named “Q”; it depends on the double-precision floating-point extension D. The floating-point registers are now extended to hold either a single, double, or quad-precision floating-point value (FLEN=128). The NaN-boxing scheme described in Section 15.2 is now extended recursively to allow a single-precision value to be NaN-boxed inside a double-precision value which is itself NaN-boxed inside a quad-precision value.
New 128-bit variants of LOAD-FP and STORE-FP instructions are added, encoded with a new value for the funct3 width field.
31 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:0] | rs1 | width | rd | opcode |
12 | 5 | 3 | 5 | 7 |
offset[11:0] | base | Q | dest | LOAD-FP |
31 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:5] | rs2 | rs1 | width | imm[4:0] | opcode |
7 | 5 | 5 | 3 | 5 | 7 |
offset[11:5] | src | base | Q | offset[4:0] | STORE-FP |
FLQ and FSQ are only guaranteed to execute atomically if the effective address is naturally aligned and XLEN=128.
FLQ and FSQ do not modify the bits being transferred; in particular, the payloads of non-canonical NaNs are preserved.
A new supported format is added to the format field of most instructions, as shown in Table 16.1.
fmt field Mnemonic Meaning 00 S 32-bit single-precision 01 D 64-bit double-precision 10 H 16-bit half-precision 11 Q 128-bit quad-precision
Table 16.1: Format field encoding.
The quad-precision floating-point computational instructions are defined analogously to their double-precision counterparts, but operate on quad-precision operands and produce quad-precision results.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FADD/FSUB | Q | src2 | src1 | RM | dest | OP-FP |
FMUL/FDIV | Q | src2 | src1 | RM | dest | OP-FP |
FMIN-MAX | Q | src2 | src1 | MIN/MAX | dest | OP-FP |
FSQRT | Q | 0 | src | RM | dest | OP-FP |
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| rs3 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
src3 | Q | src2 | src1 | RM | dest | F[N]MADD/F[N]MSUB |
New floating-point-to-integer and integer-to-floating-point conversion instructions are added. These instructions are defined analogously to the double-precision-to-integer and integer-to-double-precision conversion instructions. FCVT.W.Q or FCVT.L.Q converts a quad-precision floating-point number to a signed 32-bit or 64-bit integer, respectively. FCVT.Q.W or FCVT.Q.L converts a 32-bit or 64-bit signed integer, respectively, into a quad-precision floating-point number. FCVT.WU.Q, FCVT.LU.Q, FCVT.Q.WU, and FCVT.Q.LU variants convert to or from unsigned integer values. FCVT.L[U].Q and FCVT.Q.L[U] are RV64-only instructions.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCVT.int.Q | Q | W[U]/L[U] | src | RM | dest | OP-FP |
FCVT.Q.int | Q | W[U]/L[U] | src | RM | dest | OP-FP |
New floating-point-to-floating-point conversion instructions are added. These instructions are defined analogously to the double-precision floating-point-to-floating-point conversion instructions. FCVT.S.Q or FCVT.Q.S converts a quad-precision floating-point number to a single-precision floating-point number, or vice-versa, respectively. FCVT.D.Q or FCVT.Q.D converts a quad-precision floating-point number to a double-precision floating-point number, or vice-versa, respectively.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCVT.S.Q | S | Q | src | RM | dest | OP-FP |
FCVT.Q.S | Q | S | src | RM | dest | OP-FP |
FCVT.D.Q | D | Q | src | RM | dest | OP-FP |
FCVT.Q.D | Q | D | src | RM | dest | OP-FP |
Floating-point to floating-point sign-injection instructions, FSGNJ.Q, FSGNJN.Q, and FSGNJX.Q are defined analogously to the double-precision sign-injection instruction.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FSGNJ | Q | src2 | src1 | J[N]/JX | dest | OP-FP |
FMV.X.Q and FMV.Q.X instructions are not provided in RV32 or RV64, so quad-precision bit patterns must be moved to the integer registers via memory.
The quad-precision floating-point compare instructions are defined analogously to their double-precision counterparts, but operate on quad-precision operands.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCMP | Q | src2 | src1 | EQ/LT/LE | dest | OP-FP |
The quad-precision floating-point classify instruction, FCLASS.Q, is defined analogously to its double-precision counterpart, but operates on quad-precision operands.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCLASS | Q | 0 | src | 001 | dest | OP-FP |
This chapter describes the Zfh standard extension for 16-bit half-precision binary floating-point instructions compliant with the IEEE 754-2008 arithmetic standard. The Zfh extension depends on the single-precision floating-point extension, F. The NaN-boxing scheme described in Section 15.2 is extended to allow a half-precision value to be NaN-boxed inside a single-precision value (which may be recursively NaN-boxed inside a double- or quad-precision value when the D or Q extension is present).
New 16-bit variants of LOAD-FP and STORE-FP instructions are added, encoded with a new value for the funct3 width field.
31 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:0] | rs1 | width | rd | opcode |
12 | 5 | 3 | 5 | 7 |
offset[11:0] | base | H | dest | LOAD-FP |
31 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| imm[11:5] | rs2 | rs1 | width | imm[4:0] | opcode |
7 | 5 | 5 | 3 | 5 | 7 |
offset[11:5] | src | base | H | offset[4:0] | STORE-FP |
FLH and FSH are only guaranteed to execute atomically if the effective address is naturally aligned.
FLH and FSH do not modify the bits being transferred; in particular, the payloads of non-canonical NaNs are preserved. FLH NaN-boxes the result written to rd, whereas FSH ignores all but the lower 16 bits in rs2.
A new supported format is added to the format field of most instructions, as shown in Table 17.1.
fmt field Mnemonic Meaning 00 S 32-bit single-precision 01 D 64-bit double-precision 10 H 16-bit half-precision 11 Q 128-bit quad-precision
Table 17.1: Format field encoding.
The half-precision floating-point computational instructions are defined analogously to their single-precision counterparts, but operate on half-precision operands and produce half-precision results.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FADD/FSUB | H | src2 | src1 | RM | dest | OP-FP |
FMUL/FDIV | H | src2 | src1 | RM | dest | OP-FP |
FMIN-MAX | H | src2 | src1 | MIN/MAX | dest | OP-FP |
FSQRT | H | 0 | src | RM | dest | OP-FP |
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| rs3 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
src3 | H | src2 | src1 | RM | dest | F[N]MADD/F[N]MSUB |
New floating-point-to-integer and integer-to-floating-point conversion instructions are added. These instructions are defined analogously to the single-precision-to-integer and integer-to-single-precision conversion instructions. FCVT.W.H or FCVT.L.H converts a half-precision floating-point number to a signed 32-bit or 64-bit integer, respectively. FCVT.H.W or FCVT.H.L converts a 32-bit or 64-bit signed integer, respectively, into a half-precision floating-point number. FCVT.WU.H, FCVT.LU.H, FCVT.H.WU, and FCVT.H.LU variants convert to or from unsigned integer values. FCVT.L[U].H and FCVT.H.L[U] are RV64-only instructions.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCVT.int.H | H | W[U]/L[U] | src | RM | dest | OP-FP |
FCVT.H.int | H | W[U]/L[U] | src | RM | dest | OP-FP |
New floating-point-to-floating-point conversion instructions are added. These instructions are defined analogously to the double-precision floating-point-to-floating-point conversion instructions. FCVT.S.H or FCVT.H.S converts a half-precision floating-point number to a single-precision floating-point number, or vice-versa, respectively. If the D extension is present, FCVT.D.H or FCVT.H.D converts a half-precision floating-point number to a double-precision floating-point number, or vice-versa, respectively. If the Q extension is present, FCVT.Q.H or FCVT.H.Q converts a half-precision floating-point number to a quad-precision floating-point number, or vice-versa, respectively.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCVT.S.H | S | H | src | RM | dest | OP-FP |
FCVT.H.S | H | S | src | RM | dest | OP-FP |
FCVT.D.H | D | H | src | RM | dest | OP-FP |
FCVT.H.D | H | D | src | RM | dest | OP-FP |
FCVT.Q.H | Q | H | src | RM | dest | OP-FP |
FCVT.H.Q | H | Q | src | RM | dest | OP-FP |
Floating-point to floating-point sign-injection instructions, FSGNJ.H, FSGNJN.H, and FSGNJX.H are defined analogously to the single-precision sign-injection instruction.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FSGNJ | H | src2 | src1 | J[N]/JX | dest | OP-FP |
Instructions are provided to move bit patterns between the floating-point and integer registers. FMV.X.H moves the half-precision value in floating-point register rs1 to a representation in IEEE 754-2008 standard encoding in integer register rd, filling the upper XLEN-16 bits with copies of the floating-point number’s sign bit.
FMV.H.X moves the half-precision value encoded in IEEE 754-2008 standard encoding from the lower 16 bits of integer register rs1 to the floating-point register rd, NaN-boxing the result.
FMV.X.H and FMV.H.X do not modify the bits being transferred; in particular, the payloads of non-canonical NaNs are preserved.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FMV.X.H | H | 0 | src | 000 | dest | OP-FP |
FMV.H.X | H | 0 | src | 000 | dest | OP-FP |
The half-precision floating-point compare instructions are defined analogously to their single-precision counterparts, but operate on half-precision operands.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCMP | H | src2 | src1 | EQ/LT/LE | dest | OP-FP |
The half-precision floating-point classify instruction, FCLASS.H, is defined analogously to its single-precision counterpart, but operates on half-precision operands.
31 27 | 26 25 | 24 20 | 19 15 | 14 12 | 11 7 | 6 0 |
| funct5 | fmt | rs2 | rs1 | rm | rd | opcode |
5 | 2 | 5 | 5 | 3 | 5 | 7 |
FCLASS | H | 0 | src | 001 | dest | OP-FP |
This section describes the Zfhmin standard extension, which provides minimal support for 16-bit half-precision binary floating-point instructions. The Zfhmin extension is a subset of the Zfh extension, consisting only of data transfer and conversion instructions. Like Zfh, the Zfhmin extension depends on the single-precision floating-point extension, F. The expectation is that Zfhmin software primarily uses the half-precision format for storage, performing most computation in higher precision.
The Zfhmin extension includes the following instructions from the Zfh extension: FLH, FSH, FMV.X.H, FMV.H.X, FCVT.S.H, and FCVT.H.S. If the D extension is present, the FCVT.D.H and FCVT.H.D instructions are also included. If the Q extension is present, the FCVT.Q.H and FCVT.H.Q instructions are additionally included.
Conversion from 8- or 16-bit integers to half-precision can be emulated by first converting to single-precision, then converting to half-precision. Conversion from 32-bit integer can be emulated by first converting to double-precision. If the D extension is not present and a 1-ulp error under RNE or RMM is tolerable, 32-bit integers can be first converted to single-precision instead. The same remark applies to conversions from 64-bit integers without the Q extension.
This chapter defines the RISC-V memory consistency model. A memory consistency model is a set of rules specifying the values that can be returned by loads of memory. RISC-V uses a memory model called “RVWMO” (RISC-V Weak Memory Ordering) which is designed to provide flexibility for architects to build high-performance scalable designs while simultaneously supporting a tractable programming model.
Under RVWMO, code running on a single hart appears to execute in order from the perspective of other memory instructions in the same hart, but memory instructions from another hart may observe the memory instructions from the first hart being executed in a different order. Therefore, multithreaded code may require explicit synchronization to guarantee ordering between memory instructions from different harts. The base RISC-V ISA provides a FENCE instruction for this purpose, described in Section 3.7, while the atomics extension “A” additionally defines load-reserved/store-conditional and atomic read-modify-write instructions.
The standard ISA extension for misaligned atomics “Zam” (Chapter 24) and the standard ISA extension for total store ordering “Ztso” (Chapter 26) augment RVWMO with additional rules specific to those extensions.
The appendices to this specification provide both axiomatic and operational formalizations of the memory consistency model as well as additional explanatory material.
Memory consistency models supporting overlapping memory accesses of different widths simultaneously remain an active area of academic research and are not yet fully understood. The specifics of how memory accesses of different sizes interact under RVWMO are specified to the best of our current abilities, but they are subject to revision should new issues be uncovered.
The RVWMO memory model is defined in terms of the global memory order, a total ordering of the memory operations produced by all harts. In general, a multithreaded program has many different possible executions, with each execution having its own corresponding global memory order.
The global memory order is defined over the primitive load and store operations generated by memory instructions. It is then subject to the constraints defined in the rest of this chapter. Any execution satisfying all of the memory model constraints is a legal execution (as far as the memory model is concerned).
The program order over memory operations reflects the order in which the instructions that generate each load and store are logically laid out in that hart’s dynamic instruction stream; i.e., the order in which a simple in-order processor would execute the instructions of that hart.
Memory-accessing instructions give rise to memory operations. A memory operation can be either a load operation, a store operation, or both simultaneously. All memory operations are single-copy atomic: they can never be observed in a partially complete state.
Among instructions in RV32GC and RV64GC, each aligned memory instruction gives rise to exactly one memory operation, with two exceptions. First, an unsuccessful SC instruction does not give rise to any memory operations. Second, FLD and FSD instructions may each give rise to multiple memory operations if XLEN<64, as stated in Section 15.3 and clarified below. An aligned AMO gives rise to a single memory operation that is both a load operation and a store operation simultaneously.
A misaligned load or store instruction may be decomposed into a set of component memory operations of any granularity. An FLD or FSD instruction for which XLEN<64 may also be decomposed into a set of component memory operations of any granularity. The memory operations generated by such instructions are not ordered with respect to each other in program order, but they are ordered normally with respect to the memory operations generated by preceding and subsequent instructions in program order. The atomics extension “A” does not require execution environments to support misaligned atomic instructions at all; however, if misaligned atomics are supported via the “Zam” extension, LRs, SCs, and AMOs may be decomposed subject to the constraints of the atomicity axiom for misaligned atomics, which is defined in Chapter 24.
An LR instruction and an SC instruction are said to be paired if the LR precedes the SC in program order and if there are no other LR or SC instructions in between; the corresponding memory operations are said to be paired as well (except in case of a failed SC, where no store operation is generated). The complete list of conditions determining whether an SC must succeed, may succeed, or must fail is defined in Section 11.2.
Load and store operations may also carry one or more ordering annotations from the following set: “acquire-RCpc”, “acquire-RCsc”, “release-RCpc”, and “release-RCsc”. An AMO or LR instruction with aq set has an “acquire-RCsc” annotation. An AMO or SC instruction with rl set has a “release-RCsc” annotation. An AMO, LR, or SC instruction with both aq and rl set has both “acquire-RCsc” and “release-RCsc” annotations.
For convenience, we use the term “acquire annotation” to refer to an acquire-RCpc annotation or an acquire-RCsc annotation. Likewise, a “release annotation” refers to a release-RCpc annotation or a release-RCsc annotation. An “RCpc annotation” refers to an acquire-RCpc annotation or a release-RCpc annotation. An “RCsc annotation” refers to an acquire-RCsc annotation or a release-RCsc annotation.
While there are many different definitions for acquire and release annotations in the literature, in the context of RVWMO these terms are concisely and completely defined by Preserved Program Order rules 2–4.
“RCpc” annotations are currently only used when implicitly assigned to every memory access per the standard extension “Ztso” (Chapter 26). Furthermore, although the ISA does not currently contain native load-acquire or store-release instructions, nor RCpc variants thereof, the RVWMO model itself is designed to be forwards-compatible with the potential addition of any or all of the above into the ISA in a future extension.
The definition of the RVWMO memory model depends in part on the notion of a syntactic dependency, defined as follows.
In the context of defining dependencies, a “register” refers either to an entire general-purpose register, some portion of a CSR, or an entire CSR. The granularity at which dependencies are tracked through CSRs is specific to each CSR and is defined in Section 18.2.
Syntactic dependencies are defined in terms of instructions’ source registers, instructions’ destination registers, and the way instructions carry a dependency from their source registers to their destination registers. This section provides a general definition of all of these terms; however, Section 18.3 provides a complete listing of the specifics for each instruction.
In general, a register r other than x0 is a source register for an instruction i if any of the following hold:
Memory instructions also further specify which source registers are address source registers and which are data source registers.
In general, a register r other than x0 is a destination register for an instruction i if any of the following hold:
Most non-memory instructions carry a dependency from each of their source registers to each of their destination registers. However, there are exceptions to this rule; see Section 18.3
Instruction j has a syntactic dependency on instruction i via destination register s of i and source register r of j if either of the following hold:
Finally, in the definitions that follow, let a and b be two memory operations, and let i and j be the instructions that generate a and b, respectively.
b has a syntactic address dependency on a if r is an address source register for j and j has a syntactic dependency on i via source register r
b has a syntactic data dependency on a if b is a store operation, r is a data source register for j, and j has a syntactic dependency on i via source register r
b has a syntactic control dependency on a if there is an instruction m program-ordered between i and j such that m is a branch or indirect jump and m has a syntactic dependency on i.
The global memory order for any given execution of a program respects some but not all of each hart’s program order. The subset of program order that must be respected by the global memory order is known as preserved program order.
The complete definition of preserved program order is as follows (and note that AMOs are simultaneously both loads and stores): memory operation a precedes memory operation b in preserved program order (and hence also in the global memory order) if a precedes b in program order, a and b both access regular main memory (rather than I/O regions), and any of the following hold:
An execution of a RISC-V program obeys the RVWMO memory consistency model only if there exists a global memory order conforming to preserved program order and satisfying the load value axiom, the atomicity axiom, and the progress axiom.
Each byte of each load i returns the value written to that byte by the store that is the latest in global memory order among the following stores:
If r and w are paired load and store operations generated by aligned LR and SC instructions in a hart h, s is a store to byte x, and r returns a value written by s, then s must precede w in the global memory order, and there can be no store from a hart other than h to byte x following s and preceding w in the global memory order.
No memory operation may be preceded in the global memory order by an infinite sequence of other memory operations.
Name Portions Tracked as Independent Units Aliases fflags Bits 4, 3, 2, 1, 0 fcsr frm entire CSR fcsr fcsr Bits 7-5, 4, 3, 2, 1, 0 fflags, frm
Table 18.1: Granularities at which syntactic dependencies are tracked through CSRs
Note: read-only CSRs are not listed, as they do not participate in the definition of syntactic dependencies.
This section provides a concrete listing of the source and destination registers for each instruction. These listings are used in the definition of syntactic dependencies in Section 18.1.
The term “accumulating CSR” is used to describe a CSR that is both a source and a destination register, but which carries a dependency only from itself to itself.
Instructions carry a dependency from each source register in the “Source Registers” column to each destination register in the “Destination Registers” column, from each source register in the “Source Registers” column to each CSR in the “Accumulating CSRs” column, and from each CSR in the “Accumulating CSRs” column to itself, except where annotated otherwise.
Key:
AAddress source register
DData source register
†The instruction does not carry a dependency from any source register to any destination register
‡The instruction carries dependencies from source register(s) to destination register(s) as specified
| RV32I Base Integer Instruction Set | ||||
| Source | Destination | Accumulating | ||
| Registers | Registers | CSRs | ||
| LUI | rd | |||
| AUIPC | rd | |||
| JAL | rd | |||
| JALR† | rs1 | rd | ||
| BEQ | rs1, rs2 | |||
| BNE | rs1, rs2 | |||
| BLT | rs1, rs2 | |||
| BGE | rs1, rs2 | |||
| BLTU | rs1, rs2 | |||
| BGEU | rs1, rs2 | |||
| LB† | rs1A | rd | ||
| LH† | rs1A | rd | ||
| LW† | rs1A | rd | ||
| LBU† | rs1A | rd | ||
| LHU† | rs1A | rd | ||
| SB | rs1A, rs2D | |||
| SH | rs1A, rs2D | |||
| SW | rs1A, rs2D | |||
| ADDI | rs1 | rd | ||
| SLTI | rs1 | rd | ||
| SLTIU | rs1 | rd | ||
| XORI | rs1 | rd | ||
| ORI | rs1 | rd | ||
| ANDI | rs1 | rd | ||
| SLLI | rs1 | rd | ||
| SRLI | rs1 | rd | ||
| SRAI | rs1 | rd | ||
| ADD | rs1, rs2 | rd | ||
| SUB | rs1, rs2 | rd | ||
| SLL | rs1, rs2 | rd | ||
| SLT | rs1, rs2 | rd | ||
| SLTU | rs1, rs2 | rd | ||
| XOR | rs1, rs2 | rd | ||
| SRL | rs1, rs2 | rd | ||
| SRA | rs1, rs2 | rd | ||
| OR | rs1, rs2 | rd | ||
| AND | rs1, rs2 | rd | ||
| FENCE | ||||
| FENCE.I | ||||
| ECALL | ||||
| EBREAK | ||||
| RV32I Base Integer Instruction Set (continued) | ||||
| Source | Destination | Accumulating | ||
| Registers | Registers | CSRs | ||
| CSRRW‡ | rs1, csr* | rd, csr | *unless rd=x0 | |
| CSRRS‡ | rs1, csr | rd*, csr | *unless rs1=x0 | |
| CSRRC‡ | rs1, csr | rd*, csr | *unless rs1=x0 | |
| ‡carries a dependency from rs1 to csr and from csr to rd | ||||
| RV32I Base Integer Instruction Set (continued) | ||||
| Source | Destination | Accumulating | ||
| Registers | Registers | CSRs | ||
| CSRRWI‡ | csr* | rd, csr | *unless rd=x0 | |
| CSRRSI‡ | csr | rd, csr* | *unless uimm[4:0]=0 | |
| CSRRCI‡ | csr | rd, csr* | *unless uimm[4:0]=0 | |
| ‡carries a dependency from csr to rd | ||||
| RV64I Base Integer Instruction Set | ||||
| Source | Destination | Accumulating | ||
| Registers | Registers | CSRs | ||
| LWU† | rs1A | rd | ||
| LD† | rs1A | rd | ||
| SD | rs1A, rs2D | |||
| SLLI | rs1 | rd | ||
| SRLI | rs1 | rd | ||
| SRAI | rs1 | rd | ||
| ADDIW | rs1 | rd | ||
| SLLIW | rs1 | rd | ||
| SRLIW | rs1 | rd | ||
| SRAIW | rs1 | rd | ||
| ADDW | rs1, rs2 | rd | ||
| SUBW | rs1, rs2 | rd | ||
| SLLW | rs1, rs2 | rd | ||
| SRLW | rs1, rs2 | rd | ||
| SRAW | rs1, rs2 | rd | ||
| RV32M Standard Extension | ||||
| Source | Destination | Accumulating | ||
| Registers | Registers | CSRs | ||
| MUL | rs1, rs2 | rd | ||
| MULH | rs1, rs2 | rd | ||
| MULHSU | rs1, rs2 | rd | ||
| MULHU | rs1, rs2 | rd | ||
| DIV | rs1, rs2 | rd | ||
| DIVU | rs1, rs2 | rd | ||
| REM | rs1, rs2 | rd | ||
| REMU | rs1, rs2 | rd | ||
| RV64M Standard Extension | ||||
| Source | Destination | Accumulating | ||
| Registers | Registers | CSRs | ||
| MULW | rs1, rs2 | rd | ||
| DIVW | rs1, rs2 | rd | ||
| DIVUW | rs1, rs2 | rd | ||
| REMW | rs1, rs2 | rd | ||
| REMUW | rs1, rs2 | rd | ||
| RV32A Standard Extension | ||||
| Source | Destination | Accumulating | ||
| Registers | Registers | CSRs | ||
| LR.W† | rs1A | rd | ||
| SC.W† | rs1A, rs2D | rd* | *if successful | |
| AMOSWAP.W† | rs1A, rs2D | rd | ||
| AMOADD.W† | rs1A, rs2D | rd | ||
| AMOXOR.W† | rs1A, rs2D | rd | ||
| AMOAND.W† | rs1A, rs2D | rd | ||
| AMOOR.W† | rs1A, rs2D | rd | ||
| AMOMIN.W† | rs1A, rs2D | rd | ||
| AMOMAX.W† | rs1A, rs2D | rd | ||
| AMOMINU.W† | rs1A, rs2D | rd | ||
| AMOMAXU.W† | rs1A, rs2D | rd | ||
| RV64A Standard Extension | ||||
| Source | Destination | Accumulating | ||
| Registers | Registers | CSRs | ||
| LR.D† | rs1A | rd | ||
| SC.D† | rs1A, rs2D | rd* | *if successful | |
| AMOSWAP.D† | rs1A, rs2D | rd | ||
| AMOADD.D† | rs1A, rs2D | rd | ||
| AMOXOR.D† | rs1A, rs2D | rd | ||
| AMOAND.D† | rs1A, rs2D | rd | ||
| AMOOR.D† | rs1A, rs2D | rd | ||
| AMOMIN.D† | rs1A, rs2D | rd | ||
| AMOMAX.D† | rs1A, rs2D | rd | ||
| AMOMINU.D† | rs1A, rs2D | rd | ||
| AMOMAXU.D† | rs1A, rs2D | rd | ||
| RV32F Standard Extension | ||||
| Source | Destination | Accumulating | ||
| Registers | Registers | CSRs | ||
| FLW† | rs1A | rd | ||
| FSW | rs1A, rs2D | |||
| FMADD.S | rs1, rs2, rs3, frm* | rd | NV, OF, UF, NX | *if rm=111 |
| FMSUB.S | rs1, rs2, rs3, frm* | rd | NV, OF, UF, NX | *if rm=111 |
| FNMSUB.S | rs1, rs2, rs3, frm* | rd | NV, OF, UF, NX | *if rm=111 |
| FNMADD.S | rs1, rs2, rs3, frm* | rd | NV, OF, UF, NX | *if rm=111 |
| FADD.S | rs1, rs2, frm* | rd | NV, OF, NX | *if rm=111 |
| FSUB.S | rs1, rs2, frm* | rd | NV, OF, NX | *if rm=111 |
| FMUL.S | rs1, rs2, frm* | rd | NV, OF, UF, NX | *if rm=111 |
| FDIV.S | rs1, rs2, frm* | rd | NV, DZ, OF, UF, NX | *if rm=111 |
| FSQRT.S | rs1, frm* | rd | NV, NX | *if rm=111 |
| FSGNJ.S | rs1, rs2 | rd | ||
| FSGNJN.S | rs1, rs2 | rd | ||
| FSGNJX.S | rs1, rs2 | rd | ||
| FMIN.S | rs1, rs2 | rd | NV | |
| FMAX.S | rs1, rs2 | rd | NV | |
| FCVT.W.S | rs1, frm* | rd | NV, NX | *if rm=111 |
| FCVT.WU.S | rs1, frm* | rd | NV, NX | *if rm=111 |
| FMV.X.W | rs1 | rd | ||
| FEQ.S | rs1, rs2 | rd | NV | |
| FLT.S | rs1, rs2 | rd | NV | |
| FLE.S | rs1, rs2 | rd | NV | |
| FCLASS.S | rs1 | rd | ||
| FCVT.S.W | rs1, frm* | rd | NX | *if rm=111 |
| FCVT.S.WU | rs1, frm* | rd | NX | *if rm=111 |
| FMV.W.X | rs1 | rd | ||
| RV64F Standard Extension | ||||
| Source | Destination | Accumulating | ||
| Registers | Registers | CSRs | ||
| FCVT.L.S | rs1, frm* | rd | NV, NX | *if rm=111 |
| FCVT.LU.S | rs1, frm* | rd | NV, NX | *if rm=111 |
| FCVT.S.L | rs1, frm* | rd | NX | *if rm=111 |
| FCVT.S.LU | rs1, frm* | rd | NX | *if rm=111 |
| RV32D Standard Extension | ||||
| Source | Destination | Accumulating | ||
| Registers | Registers | CSRs | ||
| FLD† | rs1A | rd | ||
| FSD | rs1A, rs2D | |||
| FMADD.D | rs1, rs2, rs3, frm* | rd | NV, OF, UF, NX | *if rm=111 |
| FMSUB.D | rs1, rs2, rs3, frm* | rd | NV, OF, UF, NX | *if rm=111 |
| FNMSUB.D | rs1, rs2, rs3, frm* | rd | NV, OF, UF, NX | *if rm=111 |
| FNMADD.D | rs1, rs2, rs3, frm* | rd | NV, OF, UF, NX | *if rm=111 |
| FADD.D | rs1, rs2, frm* | rd | NV, OF, NX | *if rm=111 |
| FSUB.D | rs1, rs2, frm* | rd | NV, OF, NX | *if rm=111 |
| FMUL.D | rs1, rs2, frm* | rd | NV, OF, UF, NX | *if rm=111 |
| FDIV.D | rs1, rs2, frm* | rd | NV, DZ, OF, UF, NX | *if rm=111 |
| FSQRT.D | rs1, frm* | rd | NV, NX | *if rm=111 |
| FSGNJ.D | rs1, rs2 | rd | ||
| FSGNJN.D | rs1, rs2 | rd | ||
| FSGNJX.D | rs1, rs2 | rd | ||
| FMIN.D | rs1, rs2 | rd | NV | |
| FMAX.D | rs1, rs2 | rd | NV | |
| FCVT.S.D | rs1, frm* | rd | NV, OF, UF, NX | *if rm=111 |
| FCVT.D.S | rs1 | rd | NV | |
| FEQ.D | rs1, rs2 | rd | NV | |
| FLT.D | rs1, rs2 | rd | NV | |
| FLE.D | rs1, rs2 | rd | NV | |
| FCLASS.D | rs1 | rd | ||
| FCVT.W.D | rs1, frm* | rd | NV, NX | *if rm=111 |
| FCVT.WU.D | rs1, frm* | rd | NV, NX | *if rm=111 |
| FCVT.D.W | rs1 | rd | ||
| FCVT.D.WU | rs1 | rd | ||
| RV64D Standard Extension | ||||
| Source | Destination | Accumulating | ||
| Registers | Registers | CSRs | ||
| FCVT.L.D | rs1, frm* | rd | NV, NX | *if rm=111 |
| FCVT.LU.D | rs1, frm* | rd | NV, NX | *if rm=111 |
| FMV.X.D | rs1 | rd | ||
| FCVT.D.L | rs1, frm* | rd | NX | *if rm=111 |
| FCVT.D.LU | rs1, frm* | rd | NX | *if rm=111 |
| FMV.D.X | rs1 | rd | ||
This chapter describes the current proposal for the RISC-V standard compressed instruction-set extension, named “C”, which reduces static and dynamic code size by adding short 16-bit instruction encodings for common operations. The C extension can be added to any of the base ISAs (RV32, RV64, RV128), and we use the generic term “RVC” to cover any of these. Typically, 50%–60% of the RISC-V instructions in a program can be replaced with RVC instructions, resulting in a 25%–30% code-size reduction.
RVC uses a simple compression scheme that offers shorter 16-bit versions of common 32-bit RISC-V instructions when: the immediate or address offset is small, or one of the registers is the zero register (x0), the ABI link register (x1), or the ABI stack pointer (x2), or the destination register and the first source register are identical, or the registers used are the 8 most popular ones.
The C extension is compatible with all other standard instruction extensions. The C extension allows 16-bit instructions to be freely intermixed with 32-bit instructions, with the latter now able to start on any 16-bit boundary, i.e., IALIGN=16. With the addition of the C extension, no instructions can raise instruction-address-misaligned exceptions.
The compressed instruction encodings are mostly common across RV32C, RV64C, and RV128C, but as shown in Table 19.4, a few opcodes are used for different purposes depending on base ISA. For example, the wider address-space RV64C and RV128C variants require additional opcodes to compress loads and stores of 64-bit integer values, while RV32C uses the same opcodes to compress loads and stores of single-precision floating-point values. Similarly, RV128C requires additional opcodes to capture loads and stores of 128-bit integer values, while these same opcodes are used for loads and stores of double-precision floating-point values in RV32C and RV64C. If the C extension is implemented, the appropriate compressed floating-point load and store instructions must be provided whenever the relevant standard floating-point extension (F and/or D) is also implemented. In addition, RV32C includes a compressed jump and link instruction to compress short-range subroutine calls, where the same opcode is used to compress ADDIW for RV64C and RV128C.
Although single-precision loads and stores are not a significant source of static or dynamic compression for benchmarks compiled for the currently supported ABIs, for microcontrollers that only provide hardware single-precision floating-point units and have an ABI that only supports single-precision floating-point numbers, the single-precision loads and stores will be used at least as frequently as double-precision loads and stores in the measured benchmarks. Hence, the motivation to provide compressed support for these in RV32C.
Short-range subroutine calls are more likely in small binaries for microcontrollers, hence the motivation to include these in RV32C.
Although reusing opcodes for different purposes for different base ISAs adds some complexity to documentation, the impact on implementation complexity is small even for designs that support multiple base ISAs. The compressed floating-point load and store variants use the same instruction format with the same register specifiers as the wider integer loads and stores.
RVC was designed under the constraint that each RVC instruction expands into a single 32-bit instruction in either the base ISA (RV32I/E, RV64I, or RV128I) or the F and D standard extensions where present. Adopting this constraint has two main benefits:
Hardware designs can simply expand RVC instructions during decode, simplifying verification and minimizing modifications to existing microarchitectures. Compilers can be unaware of the RVC extension and leave code compression to the assembler and linker, although a compression-aware compiler will generally be able to produce better results.
It is important to note that the C extension is not designed to be a stand-alone ISA, and is meant to be used alongside a base ISA.
In 1963, CDC introduced the Cray-designed CDC 6600 [], a precursor to RISC architectures, that introduced a register-rich load-store architecture with instructions of two lengths, 15-bits and 30-bits. The later Cray-1 design used a very similar instruction format, with 16-bit and 32-bit instruction lengths.
The initial RISC ISAs from the 1980s all picked performance over code size, which was reasonable for a workstation environment, but not for embedded systems. Hence, both ARM and MIPS subsequently made versions of the ISAs that offered smaller code size by offering an alternative 16-bit wide instruction set instead of the standard 32-bit wide instructions. The compressed RISC ISAs reduced code size relative to their starting points by about 25–30%, yielding code that was significantly smaller than 80x86. This result surprised some, as their intuition was that the variable-length CISC ISA should be smaller than RISC ISAs that offered only 16-bit and 32-bit formats.
Since the original RISC ISAs did not leave sufficient opcode space free to include these unplanned compressed instructions, they were instead developed as complete new ISAs. This meant compilers needed different code generators for the separate compressed ISAs. The first compressed RISC ISA extensions (e.g., ARM Thumb and MIPS16) used only a fixed 16-bit instruction size, which gave good reductions in static code size but caused an increase in dynamic instruction count, which led to lower performance compared to the original fixed-width 32-bit instruction size. This led to the development of a second generation of compressed RISC ISA designs with mixed 16-bit and 32-bit instruction lengths (e.g., ARM Thumb2, microMIPS, PowerPC VLE), so that performance was similar to pure 32-bit instructions but with significant code size savings. Unfortunately, these different generations of compressed ISAs are incompatible with each other and with the original uncompressed ISA, leading to significant complexity in documentation, implementations, and software tools support.
Of the commonly used 64-bit ISAs, only PowerPC and microMIPS currently supports a compressed instruction format. It is surprising that the most popular 64-bit ISA for mobile platforms (ARM v8) does not include a compressed instruction format given that static code size and dynamic instruction fetch bandwidth are important metrics. Although static code size is not a major concern in larger systems, instruction fetch bandwidth can be a major bottleneck in servers running commercial workloads, which often have a large instruction working set.
Benefiting from 25 years of hindsight, RISC-V was designed to support compressed instructions from the outset, leaving enough opcode space for RVC to be added as a simple extension on top of the base ISA (along with many other extensions). The philosophy of RVC is to reduce code size for embedded applications and to improve performance and energy-efficiency for all applications due to fewer misses in the instruction cache. Waterman shows that RVC fetches 25%-30% fewer instruction bits, which reduces instruction cache misses by 20%-25%, or roughly the same performance impact as doubling the instruction cache size [].
Table 19.1 shows the nine compressed instruction formats. CR, CI, and CSS can use any of the 32 RVI registers, but CIW, CL, CS, CA, and CB are limited to just 8 of them. Table 19.2 lists these popular registers, which correspond to registers x8 to x15. Note that there is a separate version of load and store instructions that use the stack pointer as the base address register, since saving to and restoring from the stack are so prevalent, and that they use the CI and CSS formats to allow access to all 32 data registers. CIW supplies an 8-bit immediate for the ADDI4SPN instruction.
Compressed register-based floating-point loads and stores also use the CL and CS formats respectively, with the eight registers mapping to f8 to f15.
The formats were designed to keep bits for the two register source specifiers in the same place in all instructions, while the destination register field can move. When the full 5-bit destination register specifier is present, it is in the same place as in the 32-bit RISC-V encoding. Where immediates are sign-extended, the sign-extension is always from bit 12. Immediate fields have been scrambled, as in the base specification, to reduce the number of immediate muxes required.
For many RVC instructions, zero-valued immediates are disallowed and x0 is not a valid 5-bit register specifier. These restrictions free up encoding space for other instructions requiring fewer operand bits.
Format Meaning 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 CR Register funct4 rd/rs1 rs2 op CI Immediate funct3 imm rd/rs1 imm op CSS Stack-relative Store funct3 imm rs2 op CIW Wide Immediate funct3 imm rd ′ op CL Load funct3 imm rs1 ′ imm rd ′ op CS Store funct3 imm rs1 ′ imm rs2 ′ op CA Arithmetic funct6 rd ′/rs1 ′ funct2 rs2 ′ op CB Branch/Arithmetic funct3 offset rd ′/rs1 ′ offset op CJ Jump funct3 jump target op
Table 19.1: Compressed 16-bit RVC instruction formats.
RVC Register Number 000 001 010 011 100 101 110 111 Integer Register Number x8 x9 x10 x11 x12 x13 x14 x15 Integer Register ABI Name s0 s1 a0 a1 a2 a3 a4 a5 Floating-Point Register Number f8 f9 f10 f11 f12 f13 f14 f15 Floating-Point Register ABI Name fs0 fs1 fa0 fa1 fa2 fa3 fa4 fa5
Table 19.2: Registers specified by the three-bit rs1 ′, rs2 ′, and rd ′ fields of the CIW, CL, CS, CA, and CB formats.
To increase the reach of 16-bit instructions, data-transfer instructions use zero-extended immediates that are scaled by the size of the data in bytes: ×4 for words, ×8 for double words, and ×16 for quad words.
RVC provides two variants of loads and stores. One uses the ABI stack pointer, x2, as the base address and can target any data register. The other can reference one of 8 base address registers and one of 8 data registers.
15 13 | 12 | 11 7 | 6 2 | 1 0 |
| funct3 | imm | rd | imm | op |
3 | 1 | 5 | 5 | 2 |
C.LWSP | offset[5] | dest≠0 | offset[4:2|7:6] | C2 |
C.LDSP | offset[5] | dest≠0 | offset[4:3|8:6] | C2 |
C.LQSP | offset[5] | dest≠0 | offset[4|9:6] | C2 |
C.FLWSP | offset[5] | dest | offset[4:2|7:6] | C2 |
C.FLDSP | offset[5] | dest | offset[4:3|8:6] | C2 |
These instructions use the CI format.
C.LWSP loads a 32-bit value from memory into register rd. It computes an effective address by adding the zero-extended offset, scaled by 4, to the stack pointer, x2. It expands to lw rd, offset(x2). C.LWSP is only valid when rd≠x0; the code points with rd=x0 are reserved.
C.LDSP is an RV64C/RV128C-only instruction that loads a 64-bit value from memory into register rd. It computes its effective address by adding the zero-extended offset, scaled by 8, to the stack pointer, x2. It expands to ld rd, offset(x2). C.LDSP is only valid when rd≠x0; the code points with rd=x0 are reserved.
C.LQSP is an RV128C-only instruction that loads a 128-bit value from memory into register rd. It computes its effective address by adding the zero-extended offset, scaled by 16, to the stack pointer, x2. It expands to lq rd, offset(x2). C.LQSP is only valid when rd≠x0; the code points with rd=x0 are reserved.
C.FLWSP is an RV32FC-only instruction that loads a single-precision floating-point value from memory into floating-point register rd. It computes its effective address by adding the zero-extended offset, scaled by 4, to the stack pointer, x2. It expands to flw rd, offset(x2).
C.FLDSP is an RV32DC/RV64DC-only instruction that loads a double-precision floating-point value from memory into floating-point register rd. It computes its effective address by adding the zero-extended offset, scaled by 8, to the stack pointer, x2. It expands to fld rd, offset(x2).
15 13 | 12 7 | 6 2 | 1 0 |
| funct3 | imm | rs2 | op |
3 | 6 | 5 | 2 |
C.SWSP | offset[5:2|7:6] | src | C2 |
C.SDSP | offset[5:3|8:6] | src | C2 |
C.SQSP | offset[5:4|9:6] | src | C2 |
C.FSWSP | offset[5:2|7:6] | src | C2 |
C.FSDSP | offset[5:3|8:6] | src | C2 |
These instructions use the CSS format.
C.SWSP stores a 32-bit value in register rs2 to memory. It computes an effective address by adding the zero-extended offset, scaled by 4, to the stack pointer, x2. It expands to sw rs2, offset(x2).
C.SDSP is an RV64C/RV128C-only instruction that stores a 64-bit value in register rs2 to memory. It computes an effective address by adding the zero-extended offset, scaled by 8, to the stack pointer, x2. It expands to sd rs2, offset(x2).
C.SQSP is an RV128C-only instruction that stores a 128-bit value in register rs2 to memory. It computes an effective address by adding the zero-extended offset, scaled by 16, to the stack pointer, x2. It expands to sq rs2, offset(x2).
C.FSWSP is an RV32FC-only instruction that stores a single-precision floating-point value in floating-point register rs2 to memory. It computes an effective address by adding the zero-extended offset, scaled by 4, to the stack pointer, x2. It expands to fsw rs2, offset(x2).
C.FSDSP is an RV32DC/RV64DC-only instruction that stores a double-precision floating-point value in floating-point register rs2 to memory. It computes an effective address by adding the zero-extended offset, scaled by 8, to the stack pointer, x2. It expands to fsd rs2, offset(x2).
A common mechanism used in other ISAs to further reduce save/restore code size is load-multiple and store-multiple instructions. We considered adopting these for RISC-V but noted the following drawbacks to these instructions:
Furthermore, much of the gains can be realized in software by replacing prologue and epilogue code with subroutine calls to common prologue and epilogue code, a technique described in Section 5.6 of [].
While reasonable architects might come to different conclusions, we decided to omit load and store multiple and instead use the software-only approach of calling save/restore millicode routines to attain the greatest code size reduction.
15 13 | 12 10 | 9 7 | 6 5 | 4 2 | 1 0 |
| funct3 | imm | rs1 ′ | imm | rd ′ | op |
3 | 3 | 3 | 2 | 3 | 2 |
C.LW | offset[5:3] | base | offset[2|6] | dest | C0 |
C.LD | offset[5:3] | base | offset[7:6] | dest | C0 |
C.LQ | offset[5|4|8] | base | offset[7:6] | dest | C0 |
C.FLW | offset[5:3] | base | offset[2|6] | dest | C0 |
C.FLD | offset[5:3] | base | offset[7:6] | dest | C0 |
These instructions use the CL format.
C.LW loads a 32-bit value from memory into register rd ′. It computes an effective address by adding the zero-extended offset, scaled by 4, to the base address in register rs1 ′. It expands to lw rd ′, offset(rs1 ′).
C.LD is an RV64C/RV128C-only instruction that loads a 64-bit value from memory into register rd ′. It computes an effective address by adding the zero-extended offset, scaled by 8, to the base address in register rs1 ′. It expands to ld rd ′, offset(rs1 ′).
C.LQ is an RV128C-only instruction that loads a 128-bit value from memory into register rd ′. It computes an effective address by adding the zero-extended offset, scaled by 16, to the base address in register rs1 ′. It expands to lq rd ′, offset(rs1 ′).
C.FLW is an RV32FC-only instruction that loads a single-precision floating-point value from memory into floating-point register rd ′. It computes an effective address by adding the zero-extended offset, scaled by 4, to the base address in register rs1 ′. It expands to flw rd ′, offset(rs1 ′).
C.FLD is an RV32DC/RV64DC-only instruction that loads a double-precision floating-point value from memory into floating-point register rd ′. It computes an effective address by adding the zero-extended offset, scaled by 8, to the base address in register rs1 ′. It expands to fld rd ′, offset(rs1 ′).
15 13 | 12 10 | 9 7 | 6 5 | 4 2 | 1 0 |
| funct3 | imm | rs1 ′ | imm | rs2 ′ | op |
3 | 3 | 3 | 2 | 3 | 2 |
C.SW | offset[5:3] | base | offset[2|6] | src | C0 |
C.SD | offset[5:3] | base | offset[7:6] | src | C0 |
C.SQ | offset[5|4|8] | base | offset[7:6] | src | C0 |
C.FSW | offset[5:3] | base | offset[2|6] | src | C0 |
C.FSD | offset[5:3] | base | offset[7:6] | src | C0 |
These instructions use the CS format.
C.SW stores a 32-bit value in register rs2 ′ to memory. It computes an effective address by adding the zero-extended offset, scaled by 4, to the base address in register rs1 ′. It expands to sw rs2 ′, offset(rs1 ′).
C.SD is an RV64C/RV128C-only instruction that stores a 64-bit value in register rs2 ′ to memory. It computes an effective address by adding the zero-extended offset, scaled by 8, to the base address in register rs1 ′. It expands to sd rs2 ′, offset(rs1 ′).
C.SQ is an RV128C-only instruction that stores a 128-bit value in register rs2 ′ to memory. It computes an effective address by adding the zero-extended offset, scaled by 16, to the base address in register rs1 ′. It expands to sq rs2 ′, offset(rs1 ′).
C.FSW is an RV32FC-only instruction that stores a single-precision floating-point value in floating-point register rs2 ′ to memory. It computes an effective address by adding the zero-extended offset, scaled by 4, to the base address in register rs1 ′. It expands to fsw rs2 ′, offset(rs1 ′).
C.FSD is an RV32DC/RV64DC-only instruction that stores a double-precision floating-point value in floating-point register rs2 ′ to memory. It computes an effective address by adding the zero-extended offset, scaled by 8, to the base address in register rs1 ′. It expands to fsd rs2 ′, offset(rs1 ′).
RVC provides unconditional jump instructions and conditional branch instructions. As with base RVI instructions, the offsets of all RVC control transfer instruction are in multiples of 2 bytes.
15 13 | 12 2 | 1 0 |
| funct3 | imm | op |
3 | 11 | 2 |
C.J | offset[11|4|9:8|10|6|7|3:1|5] | C1 |
C.JAL | offset[11|4|9:8|10|6|7|3:1|5] | C1 |
These instructions use the CJ format.
C.J performs an unconditional control transfer. The offset is sign-extended and added to the pc to form the jump target address. C.J can therefore target a ±2 KiB range. C.J expands to jal x0, offset.
C.JAL is an RV32C-only instruction that performs the same operation as C.J, but additionally writes the address of the instruction following the jump (pc+2) to the link register, x1. C.JAL expands to jal x1, offset.
15 12 | 11 7 | 6 2 | 1 0 |
| funct4 | rs1 | rs2 | op |
4 | 5 | 5 | 2 |
C.JR | src≠0 | 0 | C2 |
C.JALR | src≠0 | 0 | C2 |
These instructions use the CR format.
C.JR (jump register) performs an unconditional control transfer to the address in register rs1. C.JR expands to jalr x0, 0(rs1). C.JR is only valid when rs1≠x0; the code point with rs1=x0 is reserved.
C.JALR (jump and link register) performs the same operation as C.JR, but additionally writes the address of the instruction following the jump (pc+2) to the link register, x1. C.JALR expands to jalr x1, 0(rs1). C.JALR is only valid when rs1≠x0; the code point with rs1=x0 corresponds to the C.EBREAK instruction.
15 13 | 12 10 | 9 7 | 6 2 | 1 0 |
| funct3 | imm | rs1 ′ | imm | op |
3 | 3 | 3 | 5 | 2 |
C.BEQZ | offset[8|4:3] | src | offset[7:6|2:1|5] | C1 |
C.BNEZ | offset[8|4:3] | src | offset[7:6|2:1|5] | C1 |
These instructions use the CB format.
C.BEQZ performs conditional control transfers. The offset is sign-extended and added to the pc to form the branch target address. It can therefore target a ±256 B range. C.BEQZ takes the branch if the value in register rs1 ′ is zero. It expands to beq rs1 ′, x0, offset.
C.BNEZ is defined analogously, but it takes the branch if rs1 ′ contains a nonzero value. It expands to bne rs1 ′, x0, offset.
RVC provides several instructions for integer arithmetic and constant generation.
The two constant-generation instructions both use the CI instruction format and can target any integer register.
15 13 | 12 | 11 7 | 6 2 | 1 0 |
| funct3 | imm[5] | rd | imm[4:0] | op |
3 | 1 | 5 | 5 | 2 |
C.LI | imm[5] | dest≠0 | imm[4:0] | C1 |
C.LUI | nzimm[17] | dest≠{0,2} | nzimm[16:12] | C1 |
C.LI loads the sign-extended 6-bit immediate, imm, into register rd. C.LI expands into addi rd, x0, imm. C.LI is only valid when rd≠x0; the code points with rd=x0 encode HINTs.
C.LUI loads the non-zero 6-bit immediate field into bits 17–12 of the destination register, clears the bottom 12 bits, and sign-extends bit 17 into all higher bits of the destination. C.LUI expands into lui rd, nzimm. C.LUI is only valid when rd≠{x0,x2}, and when the immediate is not equal to zero. The code points with nzimm=0 are reserved; the remaining code points with rd=x0 are HINTs; and the remaining code points with rd=x2 correspond to the C.ADDI16SP instruction.
These integer register-immediate operations are encoded in the CI format and perform operations on an integer register and a 6-bit immediate.
15 13 | 12 | 11 7 | 6 2 | 1 0 |
| funct3 | imm[5] | rd/rs1 | imm[4:0] | op |
3 | 1 | 5 | 5 | 2 |
C.ADDI | nzimm[5] | dest≠0 | nzimm[4:0] | C1 |
C.ADDIW | imm[5] | dest≠0 | imm[4:0] | C1 |
C.ADDI16SP | nzimm[9] | 2 | nzimm[4|6|8:7|5] | C1 |
C.ADDI adds the non-zero sign-extended 6-bit immediate to the value in register rd then writes the result to rd. C.ADDI expands into addi rd, rd, nzimm. C.ADDI is only valid when rd≠x0 and nzimm≠0. The code points with rd=x0 encode the C.NOP instruction; the remaining code points with nzimm=0 encode HINTs.
C.ADDIW is an RV64C/RV128C-only instruction that performs the same computation but produces a 32-bit result, then sign-extends result to 64 bits. C.ADDIW expands into addiw rd, rd, imm. The immediate can be zero for C.ADDIW, where this corresponds to sext.w rd. C.ADDIW is only valid when rd≠x0; the code points with rd=x0 are reserved.
C.ADDI16SP shares the opcode with C.LUI, but has a destination field of x2. C.ADDI16SP adds the non-zero sign-extended 6-bit immediate to the value in the stack pointer (sp=x2), where the immediate is scaled to represent multiples of 16 in the range (-512,496). C.ADDI16SP is used to adjust the stack pointer in procedure prologues and epilogues. It expands into addi x2, x2, nzimm. C.ADDI16SP is only valid when nzimm≠0; the code point with nzimm=0 is reserved.
15 13 | 12 5 | 4 2 | 1 0 |
| funct3 | imm | rd ′ | op |
3 | 8 | 3 | 2 |
C.ADDI4SPN | nzuimm[5:4|9:6|2|3] | dest | C0 |
C.ADDI4SPN is a CIW-format instruction that adds a zero-extended non-zero immediate, scaled by 4, to the stack pointer, x2, and writes the result to rd ′. This instruction is used to generate pointers to stack-allocated variables, and expands to addi rd ′, x2, nzuimm. C.ADDI4SPN is only valid when nzuimm≠0; the code points with nzuimm=0 are reserved.
15 13 | 12 | 11 7 | 6 2 | 1 0 |
| funct3 | shamt[5] | rd/rs1 | shamt[4:0] | op |
3 | 1 | 5 | 5 | 2 |
C.SLLI | shamt[5] | dest≠0 | shamt[4:0] | C2 |
C.SLLI is a CI-format instruction that performs a logical left shift of the value in register rd then writes the result to rd. The shift amount is encoded in the shamt field. For RV128C, a shift amount of zero is used to encode a shift of 64. C.SLLI expands into slli rd, rd, shamt, except for RV128C with shamt=0, which expands to slli rd, rd, 64.
For RV32C, shamt[5] must be zero; the code points with shamt[5]=1 are designated for custom extensions. For RV32C and RV64C, the shift amount must be non-zero; the code points with shamt=0 are HINTs. For all base ISAs, the code points with rd=x0 are HINTs, except those with shamt[5]=1 in RV32C.
15 13 | 12 | 11 10 | 9 7 | 6 2 | 1 0 |
| funct3 | shamt[5] | funct2 | rd ′/rs1 ′ | shamt[4:0] | op |
3 | 1 | 2 | 3 | 5 | 2 |
C.SRLI | shamt[5] | C.SRLI | dest | shamt[4:0] | C1 |
C.SRAI | shamt[5] | C.SRAI | dest | shamt[4:0] | C1 |
C.SRLI is a CB-format instruction that performs a logical right shift of the value in register rd ′ then writes the result to rd ′. The shift amount is encoded in the shamt field. For RV128C, a shift amount of zero is used to encode a shift of 64. Furthermore, the shift amount is sign-extended for RV128C, and so the legal shift amounts are 1–31, 64, and 96–127. C.SRLI expands into srli rd ′, rd ′, shamt, except for RV128C with shamt=0, which expands to srli rd ′, rd ′, 64.
For RV32C, shamt[5] must be zero; the code points with shamt[5]=1 are designated for custom extensions. For RV32C and RV64C, the shift amount must be non-zero; the code points with shamt=0 are HINTs.
C.SRAI is defined analogously to C.SRLI, but instead performs an arithmetic right shift. C.SRAI expands to srai rd ′, rd ′, shamt.
15 13 | 12 | 11 10 | 9 7 | 6 2 | 1 0 |
| funct3 | imm[5] | funct2 | rd ′/rs1 ′ | imm[4:0] | op |
3 | 1 | 2 | 3 | 5 | 2 |
C.ANDI | imm[5] | C.ANDI | dest | imm[4:0] | C1 |
C.ANDI is a CB-format instruction that computes the bitwise AND of the value in register rd ′ and the sign-extended 6-bit immediate, then writes the result to rd ′. C.ANDI expands to andi rd ′, rd ′, imm.
15 12 | 11 7 | 6 2 | 1 0 |
| funct4 | rd/rs1 | rs2 | op |
4 | 5 | 5 | 2 |
C.MV | dest≠0 | src≠0 | C2 |
C.ADD | dest≠0 | src≠0 | C2 |
These instructions use the CR format.
C.MV copies the value in register rs2 into register rd. C.MV expands into add rd, x0, rs2. C.MV is only valid when rs2≠x0; the code points with rs2=x0 correspond to the C.JR instruction. The code points with rs2≠x0 and rd=x0 are HINTs.
C.ADD adds the values in registers rd and rs2 and writes the result to register rd. C.ADD expands into add rd, rd, rs2. C.ADD is only valid when rs2≠x0; the code points with rs2=x0 correspond to the C.JALR and C.EBREAK instructions. The code points with rs2≠x0 and rd=x0 are HINTs.
15 10 | 9 7 | 6 5 | 4 2 | 1 0 |
| funct6 | rd ′/rs1 ′ | funct2 | rs2 ′ | op |
6 | 3 | 2 | 3 | 2 |
C.AND | dest | C.AND | src | C1 |
C.OR | dest | C.OR | src | C1 |
C.XOR | dest | C.XOR | src | C1 |
C.SUB | dest | C.SUB | src | C1 |
C.ADDW | dest | C.ADDW | src | C1 |
C.SUBW | dest | C.SUBW | src | C1 |
These instructions use the CA format.
C.AND computes the bitwise AND of the values in registers rd ′ and rs2 ′, then writes the result to register rd ′. C.AND expands into and rd ′, rd ′, rs2 ′.
C.OR computes the bitwise OR of the values in registers rd ′ and rs2 ′, then writes the result to register rd ′. C.OR expands into or rd ′, rd ′, rs2 ′.
C.XOR computes the bitwise XOR of the values in registers rd ′ and rs2 ′, then writes the result to register rd ′. C.XOR expands into xor rd ′, rd ′, rs2 ′.
C.SUB subtracts the value in register rs2 ′ from the value in register rd ′, then writes the result to register rd ′. C.SUB expands into sub rd ′, rd ′, rs2 ′.
C.ADDW is an RV64C/RV128C-only instruction that adds the values in registers rd ′ and rs2 ′, then sign-extends the lower 32 bits of the sum before writing the result to register rd ′. C.ADDW expands into addw rd ′, rd ′, rs2 ′.
C.SUBW is an RV64C/RV128C-only instruction that subtracts the value in register rs2 ′ from the value in register rd ′, then sign-extends the lower 32 bits of the difference before writing the result to register rd ′. C.SUBW expands into subw rd ′, rd ′, rs2 ′.
15 13 | 12 | 11 7 | 6 2 | 1 0 |
| 0 | 0 | 0 | 0 | 0 |
3 | 1 | 5 | 5 | 2 |
0 | 0 | 0 | 0 | 0 |
A 16-bit instruction with all bits zero is permanently reserved as an illegal instruction.
15 13 | 12 | 11 7 | 6 2 | 1 0 |
| funct3 | imm[5] | rd/rs1 | imm[4:0] | op |
3 | 1 | 5 | 5 | 2 |
C.NOP | 0 | 0 | 0 | C1 |
C.NOP is a CI-format instruction that does not change any user-visible state, except for advancing the pc and incrementing any applicable performance counters. C.NOP expands to nop. C.NOP is only valid when imm=0; the code points with imm≠0 encode HINTs.
15 12 | 11 2 | 1 0 |
| funct4 | 0 | op |
4 | 10 | 2 |
C.EBREAK | 0 | C2 |
Debuggers can use the C.EBREAK instruction, which expands to ebreak, to cause control to be transferred back to the debugging environment. C.EBREAK shares the opcode with the C.ADD instruction, but with rd and rs2 both zero, thus can also use the CR format.
On implementations that support the C extension, compressed forms of the I instructions permitted inside constrained LR/SC sequences, as described in Section 11.3, are also permitted inside constrained LR/SC sequences.
A portion of the RVC encoding space is reserved for microarchitectural HINTs. Like the HINTs in the RV32I base ISA (see Section 3.9), these instructions do not modify any architectural state, except for advancing the pc and any applicable performance counters. HINTs are executed as no-ops on implementations that ignore them.
RVC HINTs are encoded as computational instructions that do not modify the architectural state, either because rd=x0 (e.g. C.ADD x0, t0), or because rd is overwritten with a copy of itself (e.g. C.ADDI t0, 0).
RVC HINTs do not necessarily expand to their RVI HINT counterparts. For example, C.ADD x0, a0 might not encode the same HINT as ADD x0, x0, a0.
Table 19.3 lists all RVC HINT code points. For RV32C, 78% of the HINT space is reserved for standard HINTs. The remainder of the HINT space is designated for custom HINTs: no standard HINTs will ever be defined in this subspace.
Instruction Constraints Code Points Purpose C.NOP nzimm≠0 63 6*Reserved for future standard use C.ADDI rd≠x0, nzimm=0 31 C.LI rd=x0 64 C.LUI rd=x0, nzimm≠0 63 C.MV rd=x0, rs2≠x0 31 C.ADD rd=x0, rs2≠x0, rs2≠x2–x5 27 4*C.ADD 4*rd=x0, rs2=x2–x5 4*4 (rs2=x2) C.NTL.P1 (rs2=x3) C.NTL.PALL (rs2=x4) C.NTL.S1 (rs2=x5) C.NTL.ALL 2*C.SLLI 2*rd=x0, nzimm≠0 31 (RV32) 6*Designated for custom use 63 (RV64/128) C.SLLI64 rd=x0 1 C.SLLI64 rd≠x0, RV32 and RV64 only 31 C.SRLI64 RV32 and RV64 only 8 C.SRAI64 RV32 and RV64 only 8
Table 19.3: RVC HINT instructions.
Table 19.4 shows a map of the major opcodes for RVC. Each row of the table corresponds to one quadrant of the encoding space. The last quadrant, which has the two least-significant bits set, corresponds to instructions wider than 16 bits, including those in the base ISAs. Several instructions are only valid for certain operands; when invalid, they are marked either RES to indicate that the opcode is reserved for future standard extensions; Custom to indicate that the opcode is designated for custom extensions; or HINT to indicate that the opcode is reserved for microarchitectural hints (see Section 19.7).
inst[15:13] 2*000 2*001 2*010 2*011 2*100 2*101 2*110 2*111 inst[1:0] 3*00 3*ADDI4SPN FLD 3*LW FLW 3*Reserved FSD 3*SW FSW RV32 FLD LD FSD SD RV64 LQ LD SQ SD RV128 3*01 3*ADDI JAL 3*LI 3*LUI/ADDI16SP 3*MISC-ALU 3*J 3*BEQZ 3*BNEZ RV32 ADDIW RV64 ADDIW RV128 3*10 3*SLLI FLDSP 3*LWSP FLWSP 3*J[AL]R/MV/ADD FSDSP 3*SWSP FSWSP RV32 FLDSP LDSP FSDSP SDSP RV64 LQSP LDSP SQSP SDSP RV128 gray 11 gray >16b
Table 19.4: RVC opcode map
Tables 19.5–19.7 list the RVC instructions.
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 000 0 0 00 Illegal instruction 000 nzuimm[5:4|9:6|2|3] rd ′ 00 C.ADDI4SPN (RES, nzuimm=0) 001 uimm[5:3] rs1 ′ uimm[7:6] rd ′ 00 C.FLD (RV32/64) 001 uimm[5:4|8] rs1 ′ uimm[7:6] rd ′ 00 C.LQ (RV128) 010 uimm[5:3] rs1 ′ uimm[2|6] rd ′ 00 C.LW 011 uimm[5:3] rs1 ′ uimm[2|6] rd ′ 00 C.FLW (RV32) 011 uimm[5:3] rs1 ′ uimm[7:6] rd ′ 00 C.LD (RV64/128) 100 — 00 Reserved 101 uimm[5:3] rs1 ′ uimm[7:6] rs2 ′ 00 C.FSD (RV32/64) 101 uimm[5:4|8] rs1 ′ uimm[7:6] rs2 ′ 00 C.SQ (RV128) 110 uimm[5:3] rs1 ′ uimm[2|6] rs2 ′ 00 C.SW 111 uimm[5:3] rs1 ′ uimm[2|6] rs2 ′ 00 C.FSW (RV32) 111 uimm[5:3] rs1 ′ uimm[7:6] rs2 ′ 00 C.SD (RV64/128)
Table 19.5: Instruction listing for RVC, Quadrant 0.
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 000 nzimm[5] 0 nzimm[4:0] 01 C.NOP (HINT, nzimm≠0) 000 nzimm[5] rs1/rd≠0 nzimm[4:0] 01 C.ADDI (HINT, nzimm=0) 001 imm[11|4|9:8|10|6|7|3:1|5] 01 C.JAL (RV32) 001 imm[5] rs1/rd≠0 imm[4:0] 01 C.ADDIW (RV64/128; RES, rd=0) 010 imm[5] rd≠0 imm[4:0] 01 C.LI (HINT, rd=0) 011 nzimm[9] 2 nzimm[4|6|8:7|5] 01 C.ADDI16SP (RES, nzimm=0) 011 nzimm[17] rd≠{0,2} nzimm[16:12] 01 C.LUI (RES, nzimm=0; HINT, rd=0) 100 nzuimm[5] 00 rs1 ′/rd ′ nzuimm[4:0] 01 C.SRLI (RV32 Custom, nzuimm[5]=1) 100 0 00 rs1 ′/rd ′ 0 01 C.SRLI64 (RV128; RV32/64 HINT) 100 nzuimm[5] 01 rs1 ′/rd ′ nzuimm[4:0] 01 C.SRAI (RV32 Custom, nzuimm[5]=1) 100 0 01 rs1 ′/rd ′ 0 01 C.SRAI64 (RV128; RV32/64 HINT) 100 imm[5] 10 rs1 ′/rd ′ imm[4:0] 01 C.ANDI 100 0 11 rs1 ′/rd ′ 00 rs2 ′ 01 C.SUB 100 0 11 rs1 ′/rd ′ 01 rs2 ′ 01 C.XOR 100 0 11 rs1 ′/rd ′ 10 rs2 ′ 01 C.OR 100 0 11 rs1 ′/rd ′ 11 rs2 ′ 01 C.AND 100 1 11 rs1 ′/rd ′ 00 rs2 ′ 01 C.SUBW (RV64/128; RV32 RES) 100 1 11 rs1 ′/rd ′ 01 rs2 ′ 01 C.ADDW (RV64/128; RV32 RES) 100 1 11 — 10 — 01 Reserved 100 1 11 — 11 — 01 Reserved 101 imm[11|4|9:8|10|6|7|3:1|5] 01 C.J 110 imm[8|4:3] rs1 ′ imm[7:6|2:1|5] 01 C.BEQZ 111 imm[8|4:3] rs1 ′ imm[7:6|2:1|5] 01 C.BNEZ
Table 19.6: Instruction listing for RVC, Quadrant 1.
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 000 nzuimm[5] rs1/rd≠0 nzuimm[4:0] 10 C.SLLI (HINT, rd=0; RV32 Custom, nzuimm[5]=1) 000 0 rs1/rd≠0 0 10 C.SLLI64 (RV128; RV32/64 HINT; HINT, rd=0) 001 uimm[5] rd uimm[4:3|8:6] 10 C.FLDSP (RV32/64) 001 uimm[5] rd≠0 uimm[4|9:6] 10 C.LQSP (RV128; RES, rd=0) 010 uimm[5] rd≠0 uimm[4:2|7:6] 10 C.LWSP (RES, rd=0) 011 uimm[5] rd uimm[4:2|7:6] 10 C.FLWSP (RV32) 011 uimm[5] rd≠0 uimm[4:3|8:6] 10 C.LDSP (RV64/128; RES, rd=0) 100 0 rs1≠0 0 10 C.JR (RES, rs1=0) 100 0 rd≠0 rs2≠0 10 C.MV (HINT, rd=0) 100 1 0 0 10 C.EBREAK 100 1 rs1≠0 0 10 C.JALR 100 1 rs1/rd≠0 rs2≠0 10 C.ADD (HINT, rd=0) 101 uimm[5:3|8:6] rs2 10 C.FSDSP (RV32/64) 101 uimm[5:4|9:6] rs2 10 C.SQSP (RV128) 110 uimm[5:2|7:6] rs2 10 C.SWSP 111 uimm[5:2|7:6] rs2 10 C.FSWSP (RV32) 111 uimm[5:3|8:6] rs2 10 C.SDSP (RV64/128)
Table 19.7: Instruction listing for RVC, Quadrant 2.
This chapter is a placeholder for a future standard extension to provide bit manipulation instructions, including instructions to insert, extract, and test bit fields, and for rotations, funnel shifts, and bit and byte permutations.
We anticipate the B extension will be a brownfield encoding within the base 30-bit instruction space.
This chapter is a placeholder for a future standard extension to support dynamically translated languages.
The current working group draft is hosted at https://github.com/riscv/riscv-v-spec.
This chapter defines the “Zam” extension, which extends the “A” extension by standardizing support for misaligned atomic memory operations (AMOs). On platforms implementing “Zam”, misaligned AMOs need only execute atomically with respect to other accesses (including non-atomic loads and stores) to the same address and of the same size. More precisely, execution environments implementing “Zam” are subject to the following axiom:
If r and w are paired misaligned load and store instructions from a hart h with the same address and of the same size, then there can be no store instruction s from a hart other than h with the same address and of the same size as r and w such that a store operation generated by s lies in between memory operations generated by r and w in the global memory order. Furthermore, there can be no load instruction l from a hart other than h with the same address and of the same size as r and w such that a load operation generated by l lies between two memory operations generated by r or by w in the global memory order.
This restricted form of atomicity is intended to balance the needs of applications which require support for misaligned atomics and the ability of the implementation to actually provide the necessary degree of atomicity.
Aligned instructions under “Zam” continue to behave as they normally do under RVWMO.
This chapter defines the “Zfinx” extension (pronounced “z-f-in-x”) that provides instructions similar to those in the standard floating-point F extension for single-precision floating-point instructions but which operate on the x registers instead of the f registers. This chapter also defines the “Zdinx”, “Zhinx”, and “Zhinxmin” extensions that provide similar instructions for other floating-point precisions.
In general, software that assumes the presence of the F extension is incompatible with software that assumes the presence of the Zfinx extension, and vice versa.
The Zfinx extension adds all of the instructions that the F extension adds, except for the transfer instructions FLW, FSW, FMV.W.X, FMV.X.W, C.FLW[SP], and C.FSW[SP].
The Zfinx variants of these F-extension instructions have the same semantics, except that whenever such an instruction would have accessed an f register, it instead accesses the x register with the same number.
Floating-point operands of width w < XLEN bits occupy bits w-1:0 of an x register. Floating-point operations on w-bit operands ignore operand bits XLEN-1:w.
Floating-point operations that produce w < XLEN-bit results fill bits XLEN-1:w with copies of bit w-1 (the sign bit).
Sign-extending 32-bit floating-point numbers when held in RV64 x registers matches the existing RV64 calling conventions, which require all 32-bit types to be sign-extended when passed or returned in x registers. To keep the architecture more regular, we extend this pattern to 16-bit floating-point numbers in both RV32 and RV64.
The Zdinx extension provides analogous double-precision floating-point instructions. The Zdinx extension requires the Zfinx extension.
The Zdinx extension adds all of the instructions that the D extension adds, except for the transfer instructions FLD, FSD, FMV.D.X, FMV.X.D, C.FLD[SP], and C.FSD[SP].
The Zdinx variants of these D-extension instructions have the same semantics, except that whenever such an instruction would have accessed an f register, it instead accesses the x register with the same number.
Double-precision operands in RV32Zdinx are held in aligned x-register pairs, i.e., register numbers must be even. Use of misaligned (odd-numbered) registers for double-width floating-point operands is reserved.
Regardless of endianness, the lower-numbered register holds the low-order bits, and the higher-numbered register holds the high-order bits: e.g., bits 31:0 of a double-precision operand in RV32Zdinx might be held in register x14, with bits 63:32 of that operand held in x15.
When a double-width floating-point result is written to x0, the entire write takes no effect: e.g., for RV32Zdinx, writing a double-precision result to x0 does not cause x1 to be written.
When x0 is used as a double-width floating-point operand, the entire operand is zero—i.e., x1 is not accessed.
The Zhinx extension provides analogous half-precision floating-point instructions. The Zhinx extension requires the Zfinx extension.
The Zhinx extension adds all of the instructions that the Zfh extension adds, except for the transfer instructions FLH, FSH, FMV.H.X, and FMV.X.H.
The Zhinx variants of these Zfh-extension instructions have the same semantics, except that whenever such an instruction would have accessed an f register, it instead accesses the x register with the same number.
The Zhinxmin extension provides minimal support for 16-bit half-precision floating-point instructions that operate on the x registers. The Zhinxmin extension requires the Zfinx extension.
The Zhinxmin extension includes the following instructions from the Zhinx extension: FCVT.S.H and FCVT.H.S. If the Zdinx extension is present, the FCVT.D.H and FCVT.H.D instructions are also included.
In the standard privileged architecture defined in Volume II, the mstatus field FS is hardwired to 0 if the Zfinx extension is implemented, and FS no longer affects the trapping behavior of floating-point instructions or fcsr accesses.
The misa bits F, D, and Q are hardwired to 0 when the Zfinx extension is implemented.
This chapter defines the “Ztso” extension for the RISC-V Total Store Ordering (RVTSO) memory consistency model. RVTSO is defined as a delta from RVWMO, which is defined in Chapter 18.1.
RVTSO makes the following adjustments to RVWMO:
In the context of RVTSO, as is the case for RVWMO, the storage ordering annotations are concisely and completely defined by PPO rules 2–4. In both of these memory models, it is the rvwmo:ax:load that allows a hart to forward a value from its store buffer to a subsequent (in program order) load—that is to say that stores can be forwarded locally before they are visible to other harts.
In spite of the fact that Ztso adds no new instructions to the ISA, code written assuming RVTSO will not run correctly on implementations not supporting Ztso. Binaries compiled to run only under Ztso should indicate as such via a flag in the binary, so that platforms which do not implement Ztso can simply refuse to run them.
One goal of the RISC-V project is that it be used as a stable software development target. For this purpose, we define a combination of a base ISA (RV32I or RV64I) plus selected standard extensions (IMAFD, Zicsr, Zifencei) as a “general-purpose” ISA, and we use the abbreviation G for the IMAFDZicsr_Zifencei combination of instruction-set extensions. This chapter presents opcode maps and instruction-set listings for RV32G and RV64G.
inst[4:2] 000 001 010 011 100 101 110 gray111 inst[6:5] gray(>32b) 00 LOAD LOAD-FP custom-0 MISC-MEM OP-IMM AUIPC OP-IMM-32 gray 48b 01 STORE STORE-FP custom-1 AMO OP LUI OP-32 gray 64b 10 MADD MSUB NMSUB NMADD OP-FP reserved custom-2/rv128 gray 48b 11 BRANCH JALR reserved JAL SYSTEM reserved custom-3/rv128 gray ≥80b
Table 27.1: RISC-V base opcode map, inst[1:0]=11
Table 27.1 shows a map of the major opcodes for RVG. Major opcodes with 3 or more lower bits set are reserved for instruction lengths greater than 32 bits. Opcodes marked as reserved should be avoided for custom instruction-set extensions as they might be used by future standard extensions. Major opcodes marked as custom-0 and custom-1 will be avoided by future standard extensions and are recommended for use by custom instruction-set extensions within the base 32-bit instruction format. The opcodes marked custom-2/rv128 and custom-3/rv128 are reserved for future use by RV128, but will otherwise be avoided for standard extensions and so can also be used for custom instruction-set extensions in RV32 and RV64.
We believe RV32G and RV64G provide simple but complete instruction sets for a broad range of general-purpose computing. The optional compressed instruction set described in Chapter 19 can be added (forming RV32GC and RV64GC) to improve performance, code size, and energy efficiency, though with some additional hardware complexity.
As we move beyond IMAFDC into further instruction-set extensions, the added instructions tend to be more domain-specific and only provide benefits to a restricted class of applications, e.g., for multimedia or security. Unlike most commercial ISAs, the RISC-V ISA design clearly separates the base ISA and broadly applicable standard extensions from these more specialized additions. Chapter 28 has a more extensive discussion of ways to add extensions to the RISC-V ISA.
31 27 26 25 24 20 19 15 14 12 11 7 6 0 funct7 rs2 rs1 funct3 rd opcode R-type imm[11:0] rs1 funct3 rd opcode I-type imm[11:5] rs2 rs1 funct3 imm[4:0] opcode S-type imm[12|10:5] rs2 rs1 funct3 imm[4:1|11] opcode B-type imm[31:12] rd opcode U-type imm[20|10:1|11|19:12] rd opcode J-type RV32I Base Instruction Set imm[31:12] rd 0110111 LUI imm[31:12] rd 0010111 AUIPC imm[20|10:1|11|19:12] rd 1101111 JAL imm[11:0] rs1 000 rd 1100111 JALR imm[12|10:5] rs2 rs1 000 imm[4:1|11] 1100011 BEQ imm[12|10:5] rs2 rs1 001 imm[4:1|11] 1100011 BNE imm[12|10:5] rs2 rs1 100 imm[4:1|11] 1100011 BLT imm[12|10:5] rs2 rs1 101 imm[4:1|11] 1100011 BGE imm[12|10:5] rs2 rs1 110 imm[4:1|11] 1100011 BLTU imm[12|10:5] rs2 rs1 111 imm[4:1|11] 1100011 BGEU imm[11:0] rs1 000 rd 0000011 LB imm[11:0] rs1 001 rd 0000011 LH imm[11:0] rs1 010 rd 0000011 LW imm[11:0] rs1 100 rd 0000011 LBU imm[11:0] rs1 101 rd 0000011 LHU imm[11:5] rs2 rs1 000 imm[4:0] 0100011 SB imm[11:5] rs2 rs1 001 imm[4:0] 0100011 SH imm[11:5] rs2 rs1 010 imm[4:0] 0100011 SW imm[11:0] rs1 000 rd 0010011 ADDI imm[11:0] rs1 010 rd 0010011 SLTI imm[11:0] rs1 011 rd 0010011 SLTIU imm[11:0] rs1 100 rd 0010011 XORI imm[11:0] rs1 110 rd 0010011 ORI imm[11:0] rs1 111 rd 0010011 ANDI 0000000 shamt rs1 001 rd 0010011 SLLI 0000000 shamt rs1 101 rd 0010011 SRLI 0100000 shamt rs1 101 rd 0010011 SRAI 0000000 rs2 rs1 000 rd 0110011 ADD 0100000 rs2 rs1 000 rd 0110011 SUB 0000000 rs2 rs1 001 rd 0110011 SLL 0000000 rs2 rs1 010 rd 0110011 SLT 0000000 rs2 rs1 011 rd 0110011 SLTU 0000000 rs2 rs1 100 rd 0110011 XOR 0000000 rs2 rs1 101 rd 0110011 SRL 0100000 rs2 rs1 101 rd 0110011 SRA 0000000 rs2 rs1 110 rd 0110011 OR 0000000 rs2 rs1 111 rd 0110011 AND fm pred succ rs1 000 rd 0001111 FENCE 1000 0011 0011 00000 000 00000 0001111 FENCE.TSO 0000 0001 0000 00000 000 00000 0001111 PAUSE 000000000000 00000 000 00000 1110011 ECALL 000000000001 00000 000 00000 1110011 EBREAK
31 27 26 25 24 20 19 15 14 12 11 7 6 0 funct7 rs2 rs1 funct3 rd opcode R-type imm[11:0] rs1 funct3 rd opcode I-type imm[11:5] rs2 rs1 funct3 imm[4:0] opcode S-type RV64I Base Instruction Set (in addition to RV32I) imm[11:0] rs1 110 rd 0000011 LWU imm[11:0] rs1 011 rd 0000011 LD imm[11:5] rs2 rs1 011 imm[4:0] 0100011 SD 000000 shamt rs1 001 rd 0010011 SLLI 000000 shamt rs1 101 rd 0010011 SRLI 010000 shamt rs1 101 rd 0010011 SRAI imm[11:0] rs1 000 rd 0011011 ADDIW 0000000 shamt rs1 001 rd 0011011 SLLIW 0000000 shamt rs1 101 rd 0011011 SRLIW 0100000 shamt rs1 101 rd 0011011 SRAIW 0000000 rs2 rs1 000 rd 0111011 ADDW 0100000 rs2 rs1 000 rd 0111011 SUBW 0000000 rs2 rs1 001 rd 0111011 SLLW 0000000 rs2 rs1 101 rd 0111011 SRLW 0100000 rs2 rs1 101 rd 0111011 SRAW RV32/RV64 Zifencei Standard Extension imm[11:0] rs1 001 rd 0001111 FENCE.I RV32/RV64 Zicsr Standard Extension csr rs1 001 rd 1110011 CSRRW csr rs1 010 rd 1110011 CSRRS csr rs1 011 rd 1110011 CSRRC csr uimm 101 rd 1110011 CSRRWI csr uimm 110 rd 1110011 CSRRSI csr uimm 111 rd 1110011 CSRRCI RV32M Standard Extension 0000001 rs2 rs1 000 rd 0110011 MUL 0000001 rs2 rs1 001 rd 0110011 MULH 0000001 rs2 rs1 010 rd 0110011 MULHSU 0000001 rs2 rs1 011 rd 0110011 MULHU 0000001 rs2 rs1 100 rd 0110011 DIV 0000001 rs2 rs1 101 rd 0110011 DIVU 0000001 rs2 rs1 110 rd 0110011 REM 0000001 rs2 rs1 111 rd 0110011 REMU RV64M Standard Extension (in addition to RV32M) 0000001 rs2 rs1 000 rd 0111011 MULW 0000001 rs2 rs1 100 rd 0111011 DIVW 0000001 rs2 rs1 101 rd 0111011 DIVUW 0000001 rs2 rs1 110 rd 0111011 REMW 0000001 rs2 rs1 111 rd 0111011 REMUW
31 27 26 25 24 20 19 15 14 12 11 7 6 0 funct7 rs2 rs1 funct3 rd opcode R-type RV32A Standard Extension 00010 aq rl 00000 rs1 010 rd 0101111 LR.W 00011 aq rl rs2 rs1 010 rd 0101111 SC.W 00001 aq rl rs2 rs1 010 rd 0101111 AMOSWAP.W 00000 aq rl rs2 rs1 010 rd 0101111 AMOADD.W 00100 aq rl rs2 rs1 010 rd 0101111 AMOXOR.W 01100 aq rl rs2 rs1 010 rd 0101111 AMOAND.W 01000 aq rl rs2 rs1 010 rd 0101111 AMOOR.W 10000 aq rl rs2 rs1 010 rd 0101111 AMOMIN.W 10100 aq rl rs2 rs1 010 rd 0101111 AMOMAX.W 11000 aq rl rs2 rs1 010 rd 0101111 AMOMINU.W 11100 aq rl rs2 rs1 010 rd 0101111 AMOMAXU.W RV64A Standard Extension (in addition to RV32A) 00010 aq rl 00000 rs1 011 rd 0101111 LR.D 00011 aq rl rs2 rs1 011 rd 0101111 SC.D 00001 aq rl rs2 rs1 011 rd 0101111 AMOSWAP.D 00000 aq rl rs2 rs1 011 rd 0101111 AMOADD.D 00100 aq rl rs2 rs1 011 rd 0101111 AMOXOR.D 01100 aq rl rs2 rs1 011 rd 0101111 AMOAND.D 01000 aq rl rs2 rs1 011 rd 0101111 AMOOR.D 10000 aq rl rs2 rs1 011 rd 0101111 AMOMIN.D 10100 aq rl rs2 rs1 011 rd 0101111 AMOMAX.D 11000 aq rl rs2 rs1 011 rd 0101111 AMOMINU.D 11100 aq rl rs2 rs1 011 rd 0101111 AMOMAXU.D
31 27 26 25 24 20 19 15 14 12 11 7 6 0 funct7 rs2 rs1 funct3 rd opcode R-type rs3 funct2 rs2 rs1 funct3 rd opcode R4-type imm[11:0] rs1 funct3 rd opcode I-type imm[11:5] rs2 rs1 funct3 imm[4:0] opcode S-type RV32F Standard Extension imm[11:0] rs1 010 rd 0000111 FLW imm[11:5] rs2 rs1 010 imm[4:0] 0100111 FSW rs3 00 rs2 rs1 rm rd 1000011 FMADD.S rs3 00 rs2 rs1 rm rd 1000111 FMSUB.S rs3 00 rs2 rs1 rm rd 1001011 FNMSUB.S rs3 00 rs2 rs1 rm rd 1001111 FNMADD.S 0000000 rs2 rs1 rm rd 1010011 FADD.S 0000100 rs2 rs1 rm rd 1010011 FSUB.S 0001000 rs2 rs1 rm rd 1010011 FMUL.S 0001100 rs2 rs1 rm rd 1010011 FDIV.S 0101100 00000 rs1 rm rd 1010011 FSQRT.S 0010000 rs2 rs1 000 rd 1010011 FSGNJ.S 0010000 rs2 rs1 001 rd 1010011 FSGNJN.S 0010000 rs2 rs1 010 rd 1010011 FSGNJX.S 0010100 rs2 rs1 000 rd 1010011 FMIN.S 0010100 rs2 rs1 001 rd 1010011 FMAX.S 1100000 00000 rs1 rm rd 1010011 FCVT.W.S 1100000 00001 rs1 rm rd 1010011 FCVT.WU.S 1110000 00000 rs1 000 rd 1010011 FMV.X.W 1010000 rs2 rs1 010 rd 1010011 FEQ.S 1010000 rs2 rs1 001 rd 1010011 FLT.S 1010000 rs2 rs1 000 rd 1010011 FLE.S 1110000 00000 rs1 001 rd 1010011 FCLASS.S 1101000 00000 rs1 rm rd 1010011 FCVT.S.W 1101000 00001 rs1 rm rd 1010011 FCVT.S.WU 1111000 00000 rs1 000 rd 1010011 FMV.W.X RV64F Standard Extension (in addition to RV32F) 1100000 00010 rs1 rm rd 1010011 FCVT.L.S 1100000 00011 rs1 rm rd 1010011 FCVT.LU.S 1101000 00010 rs1 rm rd 1010011 FCVT.S.L 1101000 00011 rs1 rm rd 1010011 FCVT.S.LU
31 27 26 25 24 20 19 15 14 12 11 7 6 0 funct7 rs2 rs1 funct3 rd opcode R-type rs3 funct2 rs2 rs1 funct3 rd opcode R4-type imm[11:0] rs1 funct3 rd opcode I-type imm[11:5] rs2 rs1 funct3 imm[4:0] opcode S-type RV32D Standard Extension imm[11:0] rs1 011 rd 0000111 FLD imm[11:5] rs2 rs1 011 imm[4:0] 0100111 FSD rs3 01 rs2 rs1 rm rd 1000011 FMADD.D rs3 01 rs2 rs1 rm rd 1000111 FMSUB.D rs3 01 rs2 rs1 rm rd 1001011 FNMSUB.D rs3 01 rs2 rs1 rm rd 1001111 FNMADD.D 0000001 rs2 rs1 rm rd 1010011 FADD.D 0000101 rs2 rs1 rm rd 1010011 FSUB.D 0001001 rs2 rs1 rm rd 1010011 FMUL.D 0001101 rs2 rs1 rm rd 1010011 FDIV.D 0101101 00000 rs1 rm rd 1010011 FSQRT.D 0010001 rs2 rs1 000 rd 1010011 FSGNJ.D 0010001 rs2 rs1 001 rd 1010011 FSGNJN.D 0010001 rs2 rs1 010 rd 1010011 FSGNJX.D 0010101 rs2 rs1 000 rd 1010011 FMIN.D 0010101 rs2 rs1 001 rd 1010011 FMAX.D 0100000 00001 rs1 rm rd 1010011 FCVT.S.D 0100001 00000 rs1 rm rd 1010011 FCVT.D.S 1010001 rs2 rs1 010 rd 1010011 FEQ.D 1010001 rs2 rs1 001 rd 1010011 FLT.D 1010001 rs2 rs1 000 rd 1010011 FLE.D 1110001 00000 rs1 001 rd 1010011 FCLASS.D 1100001 00000 rs1 rm rd 1010011 FCVT.W.D 1100001 00001 rs1 rm rd 1010011 FCVT.WU.D 1101001 00000 rs1 rm rd 1010011 FCVT.D.W 1101001 00001 rs1 rm rd 1010011 FCVT.D.WU RV64D Standard Extension (in addition to RV32D) 1100001 00010 rs1 rm rd 1010011 FCVT.L.D 1100001 00011 rs1 rm rd 1010011 FCVT.LU.D 1110001 00000 rs1 000 rd 1010011 FMV.X.D 1101001 00010 rs1 rm rd 1010011 FCVT.D.L 1101001 00011 rs1 rm rd 1010011 FCVT.D.LU 1111001 00000 rs1 000 rd 1010011 FMV.D.X
31 27 26 25 24 20 19 15 14 12 11 7 6 0 funct7 rs2 rs1 funct3 rd opcode R-type rs3 funct2 rs2 rs1 funct3 rd opcode R4-type imm[11:0] rs1 funct3 rd opcode I-type imm[11:5] rs2 rs1 funct3 imm[4:0] opcode S-type RV32Q Standard Extension imm[11:0] rs1 100 rd 0000111 FLQ imm[11:5] rs2 rs1 100 imm[4:0] 0100111 FSQ rs3 11 rs2 rs1 rm rd 1000011 FMADD.Q rs3 11 rs2 rs1 rm rd 1000111 FMSUB.Q rs3 11 rs2 rs1 rm rd 1001011 FNMSUB.Q rs3 11 rs2 rs1 rm rd 1001111 FNMADD.Q 0000011 rs2 rs1 rm rd 1010011 FADD.Q 0000111 rs2 rs1 rm rd 1010011 FSUB.Q 0001011 rs2 rs1 rm rd 1010011 FMUL.Q 0001111 rs2 rs1 rm rd 1010011 FDIV.Q 0101111 00000 rs1 rm rd 1010011 FSQRT.Q 0010011 rs2 rs1 000 rd 1010011 FSGNJ.Q 0010011 rs2 rs1 001 rd 1010011 FSGNJN.Q 0010011 rs2 rs1 010 rd 1010011 FSGNJX.Q 0010111 rs2 rs1 000 rd 1010011 FMIN.Q 0010111 rs2 rs1 001 rd 1010011 FMAX.Q 0100000 00011 rs1 rm rd 1010011 FCVT.S.Q 0100011 00000 rs1 rm rd 1010011 FCVT.Q.S 0100001 00011 rs1 rm rd 1010011 FCVT.D.Q 0100011 00001 rs1 rm rd 1010011 FCVT.Q.D 1010011 rs2 rs1 010 rd 1010011 FEQ.Q 1010011 rs2 rs1 001 rd 1010011 FLT.Q 1010011 rs2 rs1 000 rd 1010011 FLE.Q 1110011 00000 rs1 001 rd 1010011 FCLASS.Q 1100011 00000 rs1 rm rd 1010011 FCVT.W.Q 1100011 00001 rs1 rm rd 1010011 FCVT.WU.Q 1101011 00000 rs1 rm rd 1010011 FCVT.Q.W 1101011 00001 rs1 rm rd 1010011 FCVT.Q.WU RV64Q Standard Extension (in addition to RV32Q) 1100011 00010 rs1 rm rd 1010011 FCVT.L.Q 1100011 00011 rs1 rm rd 1010011 FCVT.LU.Q 1101011 00010 rs1 rm rd 1010011 FCVT.Q.L 1101011 00011 rs1 rm rd 1010011 FCVT.Q.LU
31 27 26 25 24 20 19 15 14 12 11 7 6 0 funct7 rs2 rs1 funct3 rd opcode R-type rs3 funct2 rs2 rs1 funct3 rd opcode R4-type imm[11:0] rs1 funct3 rd opcode I-type imm[11:5] rs2 rs1 funct3 imm[4:0] opcode S-type RV32Zfh Standard Extension imm[11:0] rs1 001 rd 0000111 FLH imm[11:5] rs2 rs1 001 imm[4:0] 0100111 FSH rs3 10 rs2 rs1 rm rd 1000011 FMADD.H rs3 10 rs2 rs1 rm rd 1000111 FMSUB.H rs3 10 rs2 rs1 rm rd 1001011 FNMSUB.H rs3 10 rs2 rs1 rm rd 1001111 FNMADD.H 0000010 rs2 rs1 rm rd 1010011 FADD.H 0000110 rs2 rs1 rm rd 1010011 FSUB.H 0001010 rs2 rs1 rm rd 1010011 FMUL.H 0001110 rs2 rs1 rm rd 1010011 FDIV.H 0101110 00000 rs1 rm rd 1010011 FSQRT.H 0010010 rs2 rs1 000 rd 1010011 FSGNJ.H 0010010 rs2 rs1 001 rd 1010011 FSGNJN.H 0010010 rs2 rs1 010 rd 1010011 FSGNJX.H 0010110 rs2 rs1 000 rd 1010011 FMIN.H 0010110 rs2 rs1 001 rd 1010011 FMAX.H 0100000 00010 rs1 rm rd 1010011 FCVT.S.H 0100010 00000 rs1 rm rd 1010011 FCVT.H.S 0100001 00010 rs1 rm rd 1010011 FCVT.D.H 0100010 00001 rs1 rm rd 1010011 FCVT.H.D 0100011 00010 rs1 rm rd 1010011 FCVT.Q.H 0100010 00011 rs1 rm rd 1010011 FCVT.H.Q 1010010 rs2 rs1 010 rd 1010011 FEQ.H 1010010 rs2 rs1 001 rd 1010011 FLT.H 1010010 rs2 rs1 000 rd 1010011 FLE.H 1110010 00000 rs1 001 rd 1010011 FCLASS.H 1100010 00000 rs1 rm rd 1010011 FCVT.W.H 1100010 00001 rs1 rm rd 1010011 FCVT.WU.H 1110010 00000 rs1 000 rd 1010011 FMV.X.H 1101010 00000 rs1 rm rd 1010011 FCVT.H.W 1101010 00001 rs1 rm rd 1010011 FCVT.H.WU 1111010 00000 rs1 000 rd 1010011 FMV.H.X RV64Zfh Standard Extension (in addition to RV32Zfh) 1100010 00010 rs1 rm rd 1010011 FCVT.L.H 1100010 00011 rs1 rm rd 1010011 FCVT.LU.H 1101010 00010 rs1 rm rd 1010011 FCVT.H.L 1101010 00011 rs1 rm rd 1010011 FCVT.H.LU
Table 27.2: Instruction listing for RISC-V
Table 27.3 lists the CSRs that have currently been allocated CSR addresses. The timers, counters, and floating-point CSRs are the only CSRs defined in this specification.
Number Privilege Name Description Floating-Point Control and Status Registers 0x001 Read/write fflags Floating-Point Accrued Exceptions. 0x002 Read/write frm Floating-Point Dynamic Rounding Mode. 0x003 Read/write fcsr Floating-Point Control and Status Register (frm + fflags). Counters and Timers 0xC00 Read-only cycle Cycle counter for RDCYCLE instruction. 0xC01 Read-only time Timer for RDTIME instruction. 0xC02 Read-only instret Instructions-retired counter for RDINSTRET instruction. 0xC80 Read-only cycleh Upper 32 bits of cycle, RV32I only. 0xC81 Read-only timeh Upper 32 bits of time, RV32I only. 0xC82 Read-only instreth Upper 32 bits of instret, RV32I only.
Table 27.3: RISC-V control and status register (CSR) address map.
In addition to supporting standard general-purpose software development, another goal of RISC-V is to provide a basis for more specialized instruction-set extensions or more customized accelerators. The instruction encoding spaces and optional variable-length instruction encoding are designed to make it easier to leverage software development effort for the standard ISA toolchain when building more customized processors. For example, the intent is to continue to provide full software support for implementations that only use the standard I base, perhaps together with many non-standard instruction-set extensions.
This chapter describes various ways in which the base RISC-V ISA can be extended, together with the scheme for managing instruction-set extensions developed by independent groups. This volume only deals with the unprivileged ISA, although the same approach and terminology is used for supervisor-level extensions described in the second volume.
This section defines some standard terminology for describing RISC-V extensions.
Any RISC-V processor implementation must support a base integer ISA (RV32I, RV32E, RV64I, or RV128I). In addition, an implementation may support one or more extensions. We divide extensions into two broad categories: standard versus non-standard.
An instruction encoding space is some number of instruction bits within which a base ISA or ISA extension is encoded. RISC-V supports varying instruction lengths, but even within a single instruction length, there are various sizes of encoding space available. For example, the base ISAs are defined within a 30-bit encoding space (bits 31–2 of the 32-bit instruction), while the atomic extension “A” fits within a 25-bit encoding space (bits 31–7).
We use the term prefix to refer to the bits to the right of an instruction encoding space (since instruction fetch in RISC-V is little-endian, the bits to the right are stored at earlier memory addresses, hence form a prefix in instruction-fetch order). The prefix for the standard base ISA encoding is the two-bit “11” field held in bits 1–0 of the 32-bit word, while the prefix for the standard atomic extension “A” is the seven-bit “0101111” field held in bits 6–0 of the 32-bit word representing the AMO major opcode. A quirk of the encoding format is that the 3-bit funct3 field used to encode a minor opcode is not contiguous with the major opcode bits in the 32-bit instruction format, but is considered part of the prefix for 22-bit instruction spaces.
Although an instruction encoding space could be of any size, adopting a smaller set of common sizes simplifies packing independently developed extensions into a single global encoding. Table 28.1 gives the suggested sizes for RISC-V.
Size Usage # Available in standard instruction length 16-bit 32-bit 48-bit 64-bit 14-bit Quadrant of compressed 16-bit encoding 3 22-bit Minor opcode in base 32-bit encoding 28 220 235 25-bit Major opcode in base 32-bit encoding 32 217 232 30-bit Quadrant of base 32-bit encoding 1 212 227 32-bit Minor opcode in 48-bit encoding 210 225 37-bit Major opcode in 48-bit encoding 32 220 40-bit Quadrant of 48-bit encoding 4 217 45-bit Sub-minor opcode in 64-bit encoding 212 48-bit Minor opcode in 64-bit encoding 29 52-bit Major opcode in 64-bit encoding 32
Table 28.1: Suggested standard RISC-V instruction encoding space sizes.
We use the term greenfield extension to describe an extension that begins populating a new instruction encoding space, and hence can only cause encoding conflicts at the prefix level. We use the term brownfield extension to describe an extension that fits around existing encodings in a previously defined instruction space. A brownfield extension is necessarily tied to a particular greenfield parent encoding, and there may be multiple brownfield extensions to the same greenfield parent encoding. For example, the base ISAs are greenfield encodings of a 30-bit instruction space, while the FDQ floating-point extensions are all brownfield extensions adding to the parent base ISA 30-bit encoding space.
Note that we consider the standard A extension to have a greenfield encoding as it defines a new previously empty 25-bit encoding space in the leftmost bits of the full 32-bit base instruction encoding, even though its standard prefix locates it within the 30-bit encoding space of its parent base ISA. Changing only its single 7-bit prefix could move the A extension to a different 30-bit encoding space while only worrying about conflicts at the prefix level, not within the encoding space itself.
Adds state No new state Greenfield RV32I(30), RV64I(30) A(25) Brownfield F(I), D(F), Q(D) M(I)
Table 28.2: Two-dimensional characterization of standard instruction-set extensions.
Table 28.2 shows the bases and standard extensions placed in a simple two-dimensional taxonomy. One axis is whether the extension is greenfield or brownfield, while the other axis is whether the extension adds architectural state. For greenfield extensions, the size of the instruction encoding space is given in parentheses. For brownfield extensions, the name of the extension (greenfield or brownfield) it builds upon is given in parentheses. Additional user-level architectural state usually implies changes to the supervisor-level system or possibly to the standard calling convention.
Note that RV64I is not considered an extension of RV32I, but a different complete base encoding.
A complete or global encoding of an ISA for an actual RISC-V implementation must allocate a unique non-conflicting prefix for every included instruction encoding space. The bases and every standard extension have each had a standard prefix allocated to ensure they can all coexist in a global encoding.
A standard-compatible global encoding is one where the base and every included standard extension have their standard prefixes. A standard-compatible global encoding can include non-standard extensions that do not conflict with the included standard extensions. A standard-compatible global encoding can also use standard prefixes for non-standard extensions if the associated standard extensions are not included in the global encoding. In other words, a standard extension must use its standard prefix if included in a standard-compatible global encoding, but otherwise its prefix is free to be reallocated. These constraints allow a common toolchain to target the standard subset of any RISC-V standard-compatible global encoding.
To support development of proprietary custom extensions, portions of the encoding space are guaranteed to never be used by standard extensions.
We intend to support a large number of independently developed extensions by encouraging extension developers to operate within instruction encoding spaces, and by providing tools to pack these into a standard-compatible global encoding by allocating unique prefixes. Some extensions are more naturally implemented as brownfield augmentations of existing extensions, and will share whatever prefix is allocated to their parent greenfield extension. The standard extension prefixes avoid spurious incompatibilities in the encoding of core functionality, while allowing custom packing of more esoteric extensions.
This capability of repacking RISC-V extensions into different standard-compatible global encodings can be used in a number of ways.
One use-case is developing highly specialized custom accelerators, designed to run kernels from important application domains. These might want to drop all but the base integer ISA and add in only the extensions that are required for the task in hand. The base ISAs have been designed to place minimal requirements on a hardware implementation, and has been encoded to use only a small fraction of a 32-bit instruction encoding space.
Another use-case is to build a research prototype for a new type of instruction-set extension. The researchers might not want to expend the effort to implement a variable-length instruction-fetch unit, and so would like to prototype their extension using a simple 32-bit fixed-width instruction encoding. However, this new extension might be too large to coexist with standard extensions in the 32-bit space. If the research experiments do not need all of the standard extensions, a standard-compatible global encoding might drop the unused standard extensions and reuse their prefixes to place the proposed extension in a non-standard location to simplify engineering of the research prototype. Standard tools will still be able to target the base and any standard extensions that are present to reduce development time. Once the instruction-set extension has been evaluated and refined, it could then be made available for packing into a larger variable-length encoding space to avoid conflicts with all standard extensions.
The following sections describe increasingly sophisticated strategies for developing implementations with new instruction-set extensions. These are mostly intended for use in highly customized, educational, or experimental architectures rather than for the main line of RISC-V ISA development.
In this section, we discuss adding extensions to implementations that only support the base fixed-width 32-bit instruction format.
In the standard encoding, three of the available 30-bit instruction encoding spaces (those with 2-bit prefixes 00, 01, and 10) are used to enable the optional compressed instruction extension. However, if the compressed instruction-set extension is not required, then these three further 30-bit encoding spaces become available. This quadruples the available encoding space within the 32-bit format.
A 25-bit instruction encoding space corresponds to a major opcode in the base and standard extension encodings.
There are four major opcodes expressly designated for custom extensions (Table 27.1), each of which represents a 25-bit encoding space. Two of these are reserved for eventual use in the RV128 base encoding (will be OP-IMM-64 and OP-64), but can be used for non-standard extensions for RV32 and RV64.
The two major opcodes reserved for RV64 (OP-IMM-32 and OP-32) can also be used for non-standard extensions to RV32 only.
If an implementation does not require floating-point, then the seven major opcodes reserved for standard floating-point extensions (LOAD-FP, STORE-FP, MADD, MSUB, NMSUB, NMADD, OP-FP) can be reused for non-standard extensions. Similarly, the AMO major opcode can be reused if the standard atomic extensions are not required.
If an implementation does not require instructions longer than 32-bits, then an additional four major opcodes are available (those marked in gray in Table 27.1).
The base RV32I encoding uses only 11 major opcodes plus 3 reserved opcodes, leaving up to 18 available for extensions. The base RV64I encoding uses only 13 major opcodes plus 3 reserved opcodes, leaving up to 16 available for extensions.
A 22-bit encoding space corresponds to a funct3 minor opcode space in the base and standard extension encodings. Several major opcodes have a funct3 field minor opcode that is not completely occupied, leaving available several 22-bit encoding spaces.
Usually a major opcode selects the format used to encode operands in the remaining bits of the instruction, and ideally, an extension should follow the operand format of the major opcode to simplify hardware decoding.
Smaller spaces are available under certain major opcodes, and not all minor opcodes are entirely filled.
The simplest approach to provide space for extensions that are too large for the base 32-bit fixed-width instruction format is to add naturally aligned 64-bit instructions. The implementation must still support the 32-bit base instruction format, but can require that 64-bit instructions are aligned on 64-bit boundaries to simplify instruction fetch, with a 32-bit NOP instruction used as alignment padding where necessary.
To simplify use of standard tools, the 64-bit instructions should be encoded as described in Figure 2.1. However, an implementation might choose a non-standard instruction-length encoding for 64-bit instructions, while retaining the standard encoding for 32-bit instructions. For example, if compressed instructions are not required, then a 64-bit instruction could be encoded using one or more zero bits in the first two bits of an instruction.
Although RISC-V was not designed as a base for a pure VLIW machine, VLIW encodings can be added as extensions using several alternative approaches. In all cases, the base 32-bit encoding has to be supported to allow use of any standard software tools.
The simplest approach is to define a single large naturally aligned instruction format (e.g., 128 bits) within which VLIW operations are encoded. In a conventional VLIW, this approach would tend to waste instruction memory to hold NOPs, but a RISC-V-compatible implementation would have to also support the base 32-bit instructions, confining the VLIW code size expansion to VLIW-accelerated functions.
Another approach is to use the standard length encoding from Figure 2.1 to encode parallel instruction groups, allowing NOPs to be compressed out of the VLIW instruction. For example, a 64-bit instruction could hold two 28-bit operations, while a 96-bit instruction could hold three 28-bit operations, and so on. Alternatively, a 48-bit instruction could hold one 42-bit operation, while a 96-bit instruction could hold two 42-bit operations, and so on.
This approach has the advantage of retaining the base ISA encoding for instructions holding a single operation, but has the disadvantage of requiring a new 28-bit or 42-bit encoding for operations within the VLIW instructions, and misaligned instruction fetch for larger groups. One simplification is to not allow VLIW instructions to straddle certain microarchitecturally significant boundaries (e.g., cache lines or virtual memory pages).
Another approach, similar to Itanium, is to use a larger naturally aligned fixed instruction bundle size (e.g., 128 bits) across which parallel operation groups are encoded. This simplifies instruction fetch, but shifts the complexity to the group execution engine. To remain RISC-V compatible, the base 32-bit instruction would still have to be supported.
None of the above approaches retains the RISC-V encoding for the individual operations within a VLIW instruction. Yet another approach is to repurpose the two prefix bits in the fixed-width 32-bit encoding. One prefix bit can be used to signal “end-of-group” if set, while the second bit could indicate execution under a predicate if clear. Standard RISC-V 32-bit instructions generated by tools unaware of the VLIW extension would have both prefix bits set (11) and thus have the correct semantics, with each instruction at the end of a group and not predicated.
The main disadvantage of this approach is that the base ISAs lack the complex predication support usually required in an aggressive VLIW system, and it is difficult to add space to specify more predicate registers in the standard 30-bit encoding space.
This chapter describes the RISC-V ISA extension naming scheme that is used to concisely describe the set of instructions present in a hardware implementation, or the set of instructions used by an application binary interface (ABI).
The ISA naming strings are case insensitive.
RISC-V ISA strings begin with either RV32I, RV32E, RV64I, or RV128I indicating the supported address space size in bits for the base integer ISA.
Standard ISA extensions are given a name consisting of a single letter. For example, the first four standard extensions to the integer bases are: “M” for integer multiplication and division, “A” for atomic memory instructions, “F” for single-precision floating-point instructions, and “D” for double-precision floating-point instructions. Any RISC-V instruction-set variant can be succinctly described by concatenating the base integer prefix with the names of the included extensions, e.g., “RV64IMAFD”.
We have also defined an abbreviation “G” to represent the “IMAFDZicsr_Zifencei” base and extensions, as this is intended to represent our standard general-purpose ISA.
Standard extensions to the RISC-V ISA are given other reserved letters, e.g., “Q” for quad-precision floating-point, or “C” for the 16-bit compressed instruction format.
Some ISA extensions depend on the presence of other extensions, e.g., “D” depends on “F” and “F” depends on “Zicsr”. These dependences may be implicit in the ISA name: for example, RV32IF is equivalent to RV32IFZicsr, and RV32ID is equivalent to RV32IFD and RV32IFDZicsr.
Recognizing that instruction sets may expand or alter over time, we encode extension version numbers following the extension name. Version numbers are divided into major and minor version numbers, separated by a “p”. If the minor version is “0”, then “p0” can be omitted from the version string. Changes in major version numbers imply a loss of backwards compatibility, whereas changes in only the minor version number must be backwards-compatible. For example, the original 64-bit standard ISA defined in release 1.0 of this manual can be written in full as “RV64I1p0M1p0A1p0F1p0D1p0”, more concisely as “RV64I1M1A1F1D1”.
We introduced the version numbering scheme with the second release. Hence, we define the default version of a standard extension to be the version present at that time, e.g., “RV32I” is equivalent to “RV32I2”.
Underscores “_” may be used to separate ISA extensions to improve readability and to provide disambiguation, e.g., “RV32I2_M2_A2”.
Because the “P” extension for Packed SIMD can be confused for the decimal point in a version number, it must be preceded by an underscore if it follows a number. For example, “rv32i2p2” means version 2.2 of RV32I, whereas “rv32i2_p2” means version 2.0 of RV32I with version 2.0 of the P extension.
Standard extensions can also be named using a single “Z” followed by an alphabetical name and an optional version number. For example, “Zifencei” names the instruction-fetch fence extension described in Chapter 4; “Zifencei2” and “Zifencei2p0” name version 2.0 of same.
The first letter following the “Z” conventionally indicates the most closely related alphabetical extension category, IMAFDQLCBKJTPV. For the “Zam” extension for misaligned atomics, for example, the letter “a” indicates the extension is related to the “A” standard extension. If multiple “Z” extensions are named, they should be ordered first by category, then alphabetically within a category—for example, “Zicsr_Zifencei_Zam”.
Extensions with the “Z” prefix must be separated from other multi-letter extensions by an underscore, e.g., “RV32IMACZicsr_Zifencei”.
Standard supervisor-level instruction-set extensions are defined in Volume II, but are named using “S” as a prefix, followed by an alphabetical name and an optional version number. Supervisor-level extensions must be separated from other multi-letter extensions by an underscore.
Standard supervisor-level extensions should be listed after standard unprivileged extensions. If multiple supervisor-level extensions are listed, they should be ordered alphabetically.
Standard hypervisor-level instruction-set extensions are named like supervisor-level extensions, but beginning with the letter “H” instead of the letter “S”.
Standard hypervisor-level extensions should be listed after standard lesser-privileged extensions. If multiple hypervisor-level extensions are listed, they should be ordered alphabetically.
Standard machine-level instruction-set extensions are prefixed with the three letters “Zxm”.
Standard machine-level extensions should be listed after standard lesser-privileged extensions. If multiple machine-level extensions are listed, they should be ordered alphabetically.
Non-standard extensions are named using a single “X” followed by an alphabetical name and an optional version number. For example, “Xhwacha” names the Hwacha vector-fetch ISA extension; “Xhwacha2” and “Xhwacha2p0” name version 2.0 of same.
Non-standard extensions must be listed after all standard extensions. They must be separated from other multi-letter extensions by an underscore. For example, an ISA with non-standard extensions Argle and Bargle may be named “RV64IZifencei_Xargle_Xbargle”.
If multiple non-standard extensions are listed, they should be ordered alphabetically.
Table ?? summarizes the standardized extension names.
FIXME table missing during html conversion
We developed RISC-V to support our own needs in research and education, where our group is particularly interested in actual hardware implementations of research ideas (we have completed eleven different silicon fabrications of RISC-V since the first edition of this specification), and in providing real implementations for students to explore in classes (RISC-V processor RTL designs have been used in multiple undergraduate and graduate classes at Berkeley). In our current research, we are especially interested in the move towards specialized and heterogeneous accelerators, driven by the power constraints imposed by the end of conventional transistor scaling. We wanted a highly flexible and extensible base ISA around which to build our research effort.
A question we have been repeatedly asked is “Why develop a new ISA?” The biggest obvious benefit of using an existing commercial ISA is the large and widely supported software ecosystem, both development tools and ported applications, which can be leveraged in research and teaching. Other benefits include the existence of large amounts of documentation and tutorial examples. However, our experience of using commercial instruction sets for research and teaching is that these benefits are smaller in practice, and do not outweigh the disadvantages:
Our position is that the ISA is perhaps the most important interface in a computing system, and there is no reason that such an important interface should be proprietary. The dominant commercial ISAs are based on instruction-set concepts that were already well known over 30 years ago. Software developers should be able to target an open standard hardware target, and commercial processor designers should compete on implementation quality.
We are far from the first to contemplate an open ISA design suitable for hardware implementation. We also considered other existing open ISA designs, of which the closest to our goals was the OpenRISC architecture []. We decided against adopting the OpenRISC ISA for several technical reasons:
By starting from a clean slate, we could design an ISA that met all of our goals, though of course, this took far more effort than we had planned at the outset. We have now invested considerable effort in building up the RISC-V ISA infrastructure, including documentation, compiler tool chains, operating system ports, reference ISA simulators, FPGA implementations, efficient ASIC implementations, architecture test suites, and teaching materials. Since the last edition of this manual, there has been considerable uptake of the RISC-V ISA in both academia and industry, and we have created the non-profit RISC-V Foundation to protect and promote the standard. The RISC-V Foundation website at https://riscv.org contains the latest information on the Foundation membership and various open-source projects using RISC-V.
The RISC-V ISA and instruction-set manual builds upon several earlier projects. Several aspects of the supervisor-level machine and the overall format of the manual date back to the T0 (Torrent-0) vector microprocessor project at UC Berkeley and ICSI, begun in 1992. T0 was a vector processor based on the MIPS-II ISA, with Krste Asanović as main architect and RTL designer, and Brian Kingsbury and Bertrand Irrisou as principal VLSI implementors. David Johnson at ICSI was a major contributor to the T0 ISA design, particularly supervisor mode, and to the manual text. John Hauser also provided considerable feedback on the T0 ISA design.
The Scale (Software-Controlled Architecture for Low Energy) project at MIT, begun in 2000, built upon the T0 project infrastructure, refined the supervisor-level interface, and moved away from the MIPS scalar ISA by dropping the branch delay slot. Ronny Krashinsky and Christopher Batten were the principal architects of the Scale Vector-Thread processor at MIT, while Mark Hampton ported the GCC-based compiler infrastructure and tools for Scale.
A lightly edited version of the T0 MIPS scalar processor specification (MIPS-6371) was used in teaching a new version of the MIT 6.371 Introduction to VLSI Systems class in the Fall 2002 semester, with Chris Terman and Krste Asanović as lecturers. Chris Terman contributed most of the lab material for the class (there was no TA!). The 6.371 class evolved into the trial 6.884 Complex Digital Design class at MIT, taught by Arvind and Krste Asanović in Spring 2005, which became a regular Spring class 6.375. A reduced version of the Scale MIPS-based scalar ISA, named SMIPS, was used in 6.884/6.375. Christopher Batten was the TA for the early offerings of these classes and developed a considerable amount of documentation and lab material based around the SMIPS ISA. This same SMIPS lab material was adapted and enhanced by TA Yunsup Lee for the UC Berkeley Fall 2009 CS250 VLSI Systems Design class taught by John Wawrzynek, Krste Asanović, and John Lazzaro.
The Maven (Malleable Array of Vector-thread ENgines) project was a second-generation vector-thread architecture. Its design was led by Christopher Batten when he was an Exchange Scholar at UC Berkeley starting in summer 2007. Hidetaka Aoki, a visiting industrial fellow from Hitachi, gave considerable feedback on the early Maven ISA and microarchitecture design. The Maven infrastructure was based on the Scale infrastructure but the Maven ISA moved further away from the MIPS ISA variant defined in Scale, with a unified floating-point and integer register file. Maven was designed to support experimentation with alternative data-parallel accelerators. Yunsup Lee was the main implementor of the various Maven vector units, while Rimas Avižienis was the main implementor of the various Maven scalar units. Yunsup Lee and Christopher Batten ported GCC to work with the new Maven ISA. Christopher Celio provided the initial definition of a traditional vector instruction set (“Flood”) variant of Maven.
Based on experience with all these previous projects, the RISC-V ISA definition was begun in Summer 2010, with Andrew Waterman, Yunsup Lee, Krste Asanović, and David Patterson as principal designers. An initial version of the RISC-V 32-bit instruction subset was used in the UC Berkeley Fall 2010 CS250 VLSI Systems Design class, with Yunsup Lee as TA. RISC-V is a clean break from the earlier MIPS-inspired designs. John Hauser contributed to the floating-point ISA definition, including the sign-injection instructions and a register encoding scheme that permits internal recoding of floating-point values.
Multiple implementations of RISC-V processors have been completed, including several silicon fabrications, as shown in Figure 30.1.
Name Tapeout Date Process ISA Raven-1 May 29, 2011 ST 28nm FDSOI RV64G1_Xhwacha1 EOS14 April 1, 2012 IBM 45nm SOI RV64G1p1_Xhwacha2 EOS16 August 17, 2012 IBM 45nm SOI RV64G1p1_Xhwacha2 Raven-2 August 22, 2012 ST 28nm FDSOI RV64G1p1_Xhwacha2 EOS18 February 6, 2013 IBM 45nm SOI RV64G1p1_Xhwacha2 EOS20 July 3, 2013 IBM 45nm SOI RV64G1p99_Xhwacha2 Raven-3 September 26, 2013 ST 28nm SOI RV64G1p99_Xhwacha2 EOS22 March 7, 2014 IBM 45nm SOI RV64G1p9999_Xhwacha3
Table 30.1: Fabricated RISC-V testchips.
The first RISC-V processors to be fabricated were written in Verilog and manufactured in a pre-production 28 nm FDSOI technology from ST as the Raven-1 testchip in 2011. Two cores were developed by Yunsup Lee and Andrew Waterman, advised by Krste Asanović, and fabricated together: 1) an RV64 scalar core with error-detecting flip-flops, and 2) an RV64 core with an attached 64-bit floating-point vector unit. The first microarchitecture was informally known as “TrainWreck”, due to the short time available to complete the design with immature design libraries.
Subsequently, a clean microarchitecture for an in-order decoupled RV64 core was developed by Andrew Waterman, Rimas Avižienis, and Yunsup Lee, advised by Krste Asanović, and, continuing the railway theme, was codenamed “Rocket” after George Stephenson’s successful steam locomotive design. Rocket was written in Chisel, a new hardware design language developed at UC Berkeley. The IEEE floating-point units used in Rocket were developed by John Hauser, Andrew Waterman, and Brian Richards. Rocket has since been refined and developed further, and has been fabricated two more times in 28 nm FDSOI (Raven-2, Raven-3), and five times in IBM 45 nm SOI technology (EOS14, EOS16, EOS18, EOS20, EOS22) for a photonics project. Work is ongoing to make the Rocket design available as a parameterized RISC-V processor generator.
EOS14–EOS22 chips include early versions of Hwacha, a 64-bit IEEE floating-point vector unit, developed by Yunsup Lee, Andrew Waterman, Huy Vo, Albert Ou, Quan Nguyen, and Stephen Twigg, advised by Krste Asanović. EOS16–EOS22 chips include dual cores with a cache-coherence protocol developed by Henry Cook and Andrew Waterman, advised by Krste Asanović. EOS14 silicon has successfully run at 1.25 GHz. EOS16 silicon suffered from a bug in the IBM pad libraries. EOS18 and EOS20 have successfully run at 1.35 GHz.
Contributors to the Raven testchips include Yunsup Lee, Andrew Waterman, Rimas Avižienis, Brian Zimmer, Jaehwa Kwak, Ruzica Jevtić, Milovan Blagojević, Alberto Puggelli, Steven Bailey, Ben Keller, Pi-Feng Chiu, Brian Richards, Borivoje Nikolić, and Krste Asanović.
Contributors to the EOS testchips include Yunsup Lee, Rimas Avižienis, Andrew Waterman, Henry Cook, Huy Vo, Daiwei Li, Chen Sun, Albert Ou, Quan Nguyen, Stephen Twigg, Vladimir Stojanović, and Krste Asanović.
Andrew Waterman and Yunsup Lee developed the C++ ISA simulator “Spike”, used as a golden model in development and named after the golden spike used to celebrate completion of the US transcontinental railway. Spike has been made available as a BSD open-source project.
Andrew Waterman completed a Master’s thesis with a preliminary design of the RISC-V compressed instruction set [].
Various FPGA implementations of the RISC-V have been completed, primarily as part of integrated demos for the Par Lab project research retreats. The largest FPGA design has 3 cache-coherent RV64IMA processors running a research operating system. Contributors to the FPGA implementations include Andrew Waterman, Yunsup Lee, Rimas Avižienis, and Krste Asanović.
RISC-V processors have been used in several classes at UC Berkeley. Rocket was used in the Fall 2011 offering of CS250 as a basis for class projects, with Brian Zimmer as TA. For the undergraduate CS152 class in Spring 2012, Christopher Celio used Chisel to write a suite of educational RV32 processors, named “Sodor” after the island on which “Thomas the Tank Engine” and friends live. The suite includes a microcoded core, an unpipelined core, and 2, 3, and 5-stage pipelined cores, and is publicly available under a BSD license. The suite was subsequently updated and used again in CS152 in Spring 2013, with Yunsup Lee as TA, and in Spring 2014, with Eric Love as TA. Christopher Celio also developed an out-of-order RV64 design known as BOOM (Berkeley Out-of-Order Machine), with accompanying pipeline visualizations, that was used in the CS152 classes. The CS152 classes also used cache-coherent versions of the Rocket core developed by Andrew Waterman and Henry Cook.
Over the summer of 2013, the RoCC (Rocket Custom Coprocessor) interface was defined to simplify adding custom accelerators to the Rocket core. Rocket and the RoCC interface were used extensively in the Fall 2013 CS250 VLSI class taught by Jonathan Bachrach, with several student accelerator projects built to the RoCC interface. The Hwacha vector unit has been rewritten as a RoCC coprocessor.
Two Berkeley undergraduates, Quan Nguyen and Albert Ou, have successfully ported Linux to run on RISC-V in Spring 2013.
Colin Schmidt successfully completed an LLVM backend for RISC-V 2.0 in January 2014.
Darius Rad at Bluespec contributed soft-float ABI support to the GCC port in March 2014.
John Hauser contributed the definition of the floating-point classification instructions.
We are aware of several other RISC-V core implementations, including one in Verilog by Tommy Thorn, and one in Bluespec by Rishiyur Nikhil.
Thanks to Christopher F. Batten, Preston Briggs, Christopher Celio, David Chisnall, Stefan Freudenberger, John Hauser, Ben Keller, Rishiyur Nikhil, Michael Taylor, Tommy Thorn, and Robert Watson for comments on the draft ISA version 2.0 specification.
Uptake of the RISC-V ISA has been very rapid since the introduction of the frozen version 2.0 in May 2014, with too much activity to record in a short history section such as this. Perhaps the most important single event was the formation of the non-profit RISC-V Foundation in August 2015. The Foundation will now take over stewardship of the official RISC-V ISA standard, and the official website riscv.org is the best place to obtain news and updates on the RISC-V standard.
Thanks to Scott Beamer, Allen J. Baum, Christopher Celio, David Chisnall, Paul Clayton, Palmer Dabbelt, Jan Gray, Michael Hamburg, and John Hauser for comments on the version 2.0 specification.
Thanks to Jacob Bachmeyer, Alex Bradbury, David Horner, Stefan O’Rear, and Joseph Myers for comments on the version 2.1 specification.
Uptake of RISC-V continues at breakneck pace.
John Hauser and Andrew Waterman contributed a hypervisor ISA extension based upon a proposal from Paolo Bonzini.
Daniel Lustig, Arvind, Krste Asanović, Shaked Flur, Paul Loewenstein, Yatin Manerkar, Luc Maranget, Margaret Martonosi, Vijayanand Nagarajan, Rishiyur Nikhil, Jonas Oberhauser, Christopher Pulte, Jose Renau, Peter Sewell, Susmit Sarkar, Caroline Trippel, Muralidaran Vijayaraghavan, Andrew Waterman, Derek Williams, Andrew Wright, and Sizhuo Zhang contributed the memory consistency model.
Development of the RISC-V architecture and implementations has been partially funded by the following sponsors.
The content of this paper does not necessarily reflect the position or the policy of the US government and no official endorsement should be inferred.
This section provides more explanation for RVWMO (Chapter 18), using more informal language and concrete examples. These are intended to clarify the meaning and intent of the axioms and preserved program order rules. This appendix should be treated as commentary; all normative material is provided in Chapter 18 and in the rest of the main body of the ISA specification. All currently known discrepancies are listed in Section A.7. Any other discrepancies are unintentional.
Memory consistency models fall along a loose spectrum from weak to strong. Weak memory models allow more hardware implementation flexibility and deliver arguably better performance, performance per watt, power, scalability, and hardware verification overheads than strong models, at the expense of a more complex programming model. Strong models provide simpler programming models, but at the cost of imposing more restrictions on the kinds of (non-speculative) hardware optimizations that can be performed in the pipeline and in the memory system, and in turn imposing some cost in terms of power, area overhead, and verification burden.
RISC-V has chosen the RVWMO memory model, a variant of release consistency. This places it in between the two extremes of the memory model spectrum. The RVWMO memory model enables architects to build simple implementations, aggressive implementations, implementations embedded deeply inside a much larger system and subject to complex memory system interactions, or any number of other possibilities, all while simultaneously being strong enough to support programming language memory models at high performance.
To facilitate the porting of code from other architectures, some hardware implementations may choose to implement the Ztso extension, which provides stricter RVTSO ordering semantics by default. Code written for RVWMO is automatically and inherently compatible with RVTSO, but code written assuming RVTSO is not guaranteed to run correctly on RVWMO implementations. In fact, most RVWMO implementations will (and should) simply refuse to run RVTSO-only binaries. Each implementation must therefore choose whether to prioritize compatibility with RVTSO code (e.g., to facilitate porting from x86) or whether to instead prioritize compatibility with other RISC-V cores implementing RVWMO.
Some fences and/or memory ordering annotations in code written for RVWMO may become redundant under RVTSO; the cost that the default of RVWMO imposes on Ztso implementations is the incremental overhead of fetching those fences (e.g., FENCE R,RW and FENCE RW,W) which become no-ops on that implementation. However, these fences must remain present in the code if compatibility with non-Ztso implementations is desired.
The explanations in this chapter make use of litmus tests, or small programs designed to test or highlight one particular aspect of a memory model. Figure A.1 shows an example of a litmus test with two harts. As a convention for this figure and for all figures that follow in this chapter, we assume that s0–s2 are pre-set to the same value in all harts and that s0 holds the address labeled x, s1 holds y, and s2 holds z, where x, y, and z are disjoint memory locations aligned to 8 byte boundaries. Each figure shows the litmus test code on the left, and a visualization of one particular valid or invalid execution on the right.
Hart 0 Hart 1 ⋮ ⋮ li t1,1 li t4,4 (a) sw t1,0(s0) (e) sw t4,0(s0) ⋮ ⋮ li t2,2 (b) sw t2,0(s0) ⋮ ⋮ (c) lw a0,0(s0) ⋮ ⋮ li t3,3 li t5,5 (d) sw t3,0(s0) (f) sw t5,0(s0) ⋮ ⋮ (0,0) (2410,2794)(-14,-1943) (720,599)(0,0)[b]129.6pta: Wx=1 (720,-211)(0,0)[b]129.6ptb: Wx=2 (720,-1021)(0,0)[b]129.6ptc: Rx=1 (720,-1831)(0,0)[b]129.6ptd: Wx=3 (1944, -8)(0,0)[b]129.6pte: Wx=4 (1944,-818)(0,0)[b]129.6ptf: Wx=5 (837,272)(0,0)[lb]1213.2ptco (1251,-121)(0,0)[lb]1213.2ptrf (382,282)(0,0)[lb]1213.2ptco (1217,-931)(0,0)[lb]1213.2ptco ( 1,-121)(0,0)[lb]1213.2ptfr (560,-763)(0,0)[lb]1213.2ptfr (560,-1339)(0,0)[lb]1213.2ptfr (1724,-566)(0,0)[lb]1213.2ptco
Figure A.1: A sample litmus test and one forbidden execution (a0=1).
Litmus tests are used to understand the implications of the memory model in specific concrete situations. For example, in the litmus test of Figure A.1, the final value of a0 in the first hart can be either 2, 4, or 5, depending on the dynamic interleaving of the instruction stream from each hart at runtime. However, in this example, the final value of a0 in Hart 0 will never be 1 or 3; intuitively, the value 1 will no longer be visible at the time the load executes, and the value 3 will not yet be visible by the time the load executes. We analyze this test and many others below.
Edge Full Name (and explanation) rf Reads From (from each store to the loads that return a value written by that store) co Coherence (a total order on the stores to each address) fr From-Reads (from each load to co-successors of the store from which the load returned a value) ppo Preserved Program Order fence Orderings enforced by a FENCE instruction addr Address Dependency ctrl Control Dependency data Data Dependency
Table A.1: A key for the litmus test diagrams drawn in this appendix
The diagram shown to the right of each litmus test shows a visual representation of the particular execution candidate being considered. These diagrams use a notation that is common in the memory model literature for constraining the set of possible global memory orders that could produce the execution in question. It is also the basis for the herd models presented in Appendix B.2. This notation is explained in Table A.1. Of the listed relations, rf edges between harts, co edges, fr edges, and ppo edges directly constrain the global memory order (as do fence, addr, data, and some ctrl edges, via ppo). Other edges (such as intra-hart rf edges) are informative but do not constrain the global memory order.
For example, in Figure A.1, a0=1 could occur only if (c) reads the value written by (a) and one of the following were true:
Since neither of these scenarios satisfies the RVWMO axioms, the outcome a0=1 is forbidden.
Beyond what is described in this appendix, a suite of more than seven thousand litmus tests is available at https://github.com/litmus-tests/litmus-tests-riscv.
In this section, we provide explanation and examples for all of the RVWMO rules and axioms.
Preserved program order represents the subset of program order that must be respected within the global memory order. Conceptually, events from the same hart that are ordered by preserved program order must appear in that order from the perspective of other harts and/or observers. Events from the same hart that are not ordered by preserved program order, on the other hand, may appear reordered from the perspective of other harts and/or observers.
Informally, the global memory order represents the order in which loads and stores perform. The formal memory model literature has moved away from specifications built around the concept of performing, but the idea is still useful for building up informal intuition. A load is said to have performed when its return value is determined. A store is said to have performed not when it has executed inside the pipeline, but rather only when its value has been propagated to globally visible memory. In this sense, the global memory order also represents the contribution of the coherence protocol and/or the rest of the memory system to interleave the (possibly reordered) memory accesses being issued by each hart into a single total order agreed upon by all harts.
The order in which loads perform does not always directly correspond to the relative age of the values those two loads return. In particular, a load b may perform before another load a to the same address (i.e., b may execute before a, and b may appear before a in the global memory order), but a may nevertheless return an older value than b. This discrepancy captures (among other things) the reordering effects of buffering placed between the core and memory. For example, b may have returned a value from a store in the store buffer, while a may have ignored that younger store and read an older value from memory instead. To account for this, at the time each load performs, the value it returns is determined by the load value axiom, not just strictly by determining the most recent store to the same address in the global memory order, as described below.
rvwmo:ax:load:
Each byte of each load i returns the value written to that byte by the store that is the latest in global memory order among the following stores:
|
Preserved program order is not required to respect the ordering of a store followed by a load to an overlapping address. This complexity arises due to the ubiquity of store buffers in nearly all implementations. Informally, the load may perform (return a value) by forwarding from the store while the store is still in the store buffer, and hence before the store itself performs (writes back to globally visible memory). Any other hart will therefore observe the load as performing before the store.
Hart 0 Hart 1 li t1, 1 li t1, 1 (a) sw t1,0(s0) (e) sw t1,0(s1) (b) lw a0,0(s0) (f) lw a2,0(s1) (c) fence r,r (g) fence r,r (d) lw a1,0(s1) (h) lw a3,0(s0) Outcome: a0=1, a1=0, a2=1, a3=0 (0,0) (3447,1984)(-14,-1133) (821,599)(0,0)[b]129.6pta: Wx=1 (821,-211)(0,0)[b]129.6ptb: Rx=1 (821,-1021)(0,0)[b]129.6ptd: Ry=0 (2981,599)(0,0)[b]129.6pte: Wy=1 (2981,-211)(0,0)[b]129.6ptf: Ry=1 (2981,-1021)(0,0)[b]129.6pth: Rx=0 (661,281)(0,0)[lb]1213.2ptrf ( 1,-485)(0,0)[lb]1213.2ptfence (450,-485)(0,0)[lb]1213.2ptppo (1539,-122)(0,0)[lb]1213.2ptfr (3021,281)(0,0)[lb]1213.2ptrf (3061,-485)(0,0)[lb]1213.2ptfence (3511,-485)(0,0)[lb]1213.2ptppo (2103,-122)(0,0)[lb]1213.2ptfr
Figure A.2: A store buffer forwarding litmus test (outcome permitted)
Consider the litmus test of Figure A.2. When running this program on an implementation with store buffers, it is possible to arrive at the final outcome a0=1, a1=0, a2=1, a3=0 as follows:
Therefore, the memory model must be able to account for this behavior.
To put it another way, suppose the definition of preserved program order did include the following hypothetical rule: memory access a precedes memory access b in preserved program order (and hence also in the global memory order) if a precedes b in program order and a and b are accesses to the same memory location, a is a write, and b is a read. Call this “Rule X”. Then we get the following:
The global memory order must be a total order and cannot be cyclic, because a cycle would imply that every event in the cycle happens before itself, which is impossible. Therefore, the execution proposed above would be forbidden, and hence the addition of rule X would forbid implementations with store buffer forwarding, which would clearly be undesirable.
Nevertheless, even if (b) precedes (a) and/or (f) precedes (e) in the global memory order, the only sensible possibility in this example is for (b) to return the value written by (a), and likewise for (f) and (e). This combination of circumstances is what leads to the second option in the definition of the load value axiom. Even though (b) precedes (a) in the global memory order, (a) will still be visible to (b) by virtue of sitting in the store buffer at the time (b) executes. Therefore, even if (b) precedes (a) in the global memory order, (b) should return the value written by (a) because (a) precedes (b) in program order. Likewise for (e) and (f).
Hart 0 Hart 1 li t1, 1 li t1, 1 (a) sw t1,0(s0) LOOP: (b) fence w,w (d) lw a0,0(s1) (c) sw t1,0(s1) beqz a0, LOOP (e) sw t1,0(s2) (f) lw a1,0(s2) xor a2,a1,a1 add s0,s0,a2 (g) lw a2,0(s0) Outcome: a0=1, a1=1, a2=0 (0,0) (3886,2794)(-14,-1943) (821,-211)(0,0)[b]129.6pta: Wx=1 (821,-1021)(0,0)[b]129.6ptc: Wy=1 (2981,599)(0,0)[b]129.6ptd: Ry=1 (2981,-211)(0,0)[b]129.6pte: Wz=1 (2981,-1021)(0,0)[b]129.6ptf: Rz=1 (2981,-1831)(0,0)[b]129.6ptg: Rx=0 (0,-625)(0,0)[lb]1213.2ptfence (441,-625)(0,0)[lb]1213.2ptppo (1739,-122)(0,0)[lb]1213.2ptrf (2641,225)(0,0)[lb]1213.2ptctrl (3020,225)(0,0)[lb]1213.2ptppo (3520,-1000)(0,0)[lb]1213.2ptctrl (3100,-544)(0,0)[lb]1213.2ptctrl (2800,-600)(0,0)[lb]1213.2ptrf (2561,-1295)(0,0)[lb]1213.2ptaddr (3020,-1295)(0,0)[lb]1213.2ptppo (1743,-782)(0,0)[lb]1213.2ptfr
Figure A.3: The “PPOCA” store buffer forwarding litmus test (outcome permitted)
Another test that highlights the behavior of store buffers is shown in Figure A.3. In this example, (d) is ordered before (e) because of the control dependency, and (f) is ordered before (g) because of the address dependency. However, (e) is not necessarily ordered before (f), even though (f) returns the value written by (e). This could correspond to the following sequence of events:
| rvwmo:ax:atom (for Aligned Atomics): If r and w are paired load and store operations generated by aligned LR and SC instructions in a hart h, s is a store to byte x, and r returns a value written by s, then s must precede w in the global memory order, and there can be no store from a hart other than h to byte x following s and preceding w in the global memory order. |
The RISC-V architecture decouples the notion of atomicity from the notion of ordering. Unlike architectures such as TSO, RISC-V atomics under RVWMO do not impose any ordering requirements by default. Ordering semantics are only guaranteed by the PPO rules that otherwise apply.
RISC-V contains two types of atomics: AMOs and LR/SC pairs. These conceptually behave differently, in the following way. LR/SC behave as if the old value is brought up to the core, modified, and written back to memory, all while a reservation is held on that memory location. AMOs on the other hand conceptually behave as if they are performed directly in memory. AMOs are therefore inherently atomic, while LR/SC pairs are atomic in the slightly different sense that the memory location in question will not be modified by another hart during the time the original hart holds the reservation.
(a) lr.d a0, 0(s0) (b) sd t1, 0(s0) (c) sc.d t2, 0(s0) (a) lr.d a0, 0(s0) (b) sw t1, 4(s0) (c) sc.d t2, 0(s0) (a) lr.w a0, 0(s0) (b) sw t1, 4(s0) (c) sc.w t2, 0(s0) (a) lr.w a0, 0(s0) (b) sw t1, 4(s0) (c) sc.w t2, 8(s0)
Figure A.4: In all four (independent) code snippets, the store-conditional (c) is permitted but not guaranteed to succeed
The atomicity axiom forbids stores from other harts from being interleaved in global memory order between an LR and the SC paired with that LR. The atomicity axiom does not forbid loads from being interleaved between the paired operations in program order or in the global memory order, nor does it forbid stores from the same hart or stores to non-overlapping locations from appearing between the paired operations in either program order or in the global memory order. For example, the SC instructions in Figure A.4 may (but are not guaranteed to) succeed. None of those successes would violate the atomicity axiom, because the intervening non-conditional stores are from the same hart as the paired load-reserved and store-conditional instructions. This way, a memory system that tracks memory accesses at cache line granularity (and which therefore will see the four snippets of Figure A.4 as identical) will not be forced to fail a store-conditional instruction that happens to (falsely) share another portion of the same cache line as the memory location being held by the reservation.
The atomicity axiom also technically supports cases in which the LR and SC touch different addresses and/or use different access sizes; however, use cases for such behaviors are expected to be rare in practice. Likewise, scenarios in which stores from the same hart between an LR/SC pair actually overlap the memory location(s) referenced by the LR or SC are expected to be rare compared to scenarios where the intervening store may simply fall onto the same cache line.
| rvwmo:ax:prog: No memory operation may be preceded in the global memory order by an infinite sequence of other memory operations. |
The progress axiom ensures a minimal forward progress guarantee. It ensures that stores from one hart will eventually be made visible to other harts in the system in a finite amount of time, and that loads from other harts will eventually be able to read those values (or successors thereof). Without this rule, it would be legal, for example, for a spinlock to spin infinitely on a value, even with a store from another hart waiting to unlock the spinlock.
The progress axiom is intended not to impose any other notion of fairness, latency, or quality of service onto the harts in a RISC-V implementation. Any stronger notions of fairness are up to the rest of the ISA and/or up to the platform and/or device to define and implement.
The forward progress axiom will in almost all cases be naturally satisfied by any standard cache coherence protocol. Implementations with non-coherent caches may have to provide some other mechanism to ensure the eventual visibility of all stores (or successors thereof) to all harts.
| Rule 1: b is a store, and a and b access overlapping memory addresses | |
| Rule 2: a and b are loads, x is a byte read by both a and b, there is no store to x between a and b in program order, and a and b return values for x written by different memory operations | |
| Rule 3: a is generated by an AMO or SC instruction, b is a load, and b returns a value written by a |
Same-address orderings where the latter is a store are straightforward: a load or store can never be reordered with a later store to an overlapping memory location. From a microarchitecture perspective, generally speaking, it is difficult or impossible to undo a speculatively reordered store if the speculation turns out to be invalid, so such behavior is simply disallowed by the model. Same-address orderings from a store to a later load, on the other hand, do not need to be enforced. As discussed in Section A.3.2, this reflects the observable behavior of implementations that forward values from buffered stores to later loads.
Same-address load-load ordering requirements are far more subtle. The basic requirement is that a younger load must not return a value that is older than a value returned by an older load in the same hart to the same address. This is often known as “CoRR” (Coherence for Read-Read pairs), or as part of a broader “coherence” or “sequential consistency per location” requirement. Some architectures in the past have relaxed same-address load-load ordering, but in hindsight this is generally considered to complicate the programming model too much, and so RVWMO requires CoRR ordering to be enforced. However, because the global memory order corresponds to the order in which loads perform rather than the ordering of the values being returned, capturing CoRR requirements in terms of the global memory order requires a bit of indirection.
FIXME figure missing during html conversion
Consider the litmus test of Figure ??, which is one particular instance of the more general “fri-rfi” pattern. The term “fri-rfi” refers to the sequence (d), (e), (f): (d) “from-reads” (i.e., reads from an earlier write than) (e) which is the same hart, and (f) reads from (e) which is in the same hart.
From a microarchitectural perspective, outcome a0=1, a1=2, a2=0 is legal (as are various other less subtle outcomes). Intuitively, the following would produce the outcome in question:
This corresponds to a global memory order of (f), (i), (a), (c), (d), (e). Note that even though (f) performs before (d), the value returned by (f) is newer than the value returned by (d). Therefore, this execution is legal and does not violate the CoRR requirements.
Likewise, if two back-to-back loads return the values written by the same store, then they may also appear out-of-order in the global memory order without violating CoRR. Note that this is not the same as saying that the two loads return the same value, since two different stores may write the same value.
Hart 0 Hart 1 li t1, 1 (d) lw a0,0(s1) (a) sw t1,0(s0) (e) xor t2,a0,a0 (b) fence w, w (f) add s4,s2,t2 (c) sw t1,0(s1) (g) lw a1,0(s4) (h) lw a2,0(s2) (i) xor t3,a2,a2 (j) add s0,s0,t3 (k) lw a3,0(s0) Outcome: a0=1, a1=v, a2=v, a3=0 (0,0) (4187,2308)(-14,-1457) (821,599)(0,0)[b]129.6pta: Wx=1 (821,-49)(0,0)[b]129.6ptc: Wy=1 (2261,599)(0,0)[b]129.6ptd: Ry=1 (2261,-49)(0,0)[b]129.6ptg: Rz=v (2261,-697)(0,0)[b]129.6pth: Rz=v (2261,-1345)(0,0)[b]129.6ptk: Rx=0 (3701,-373)(0,0)[b]129.6pt Wz=v ( 1,173)(0,0)[lb]1213.2ptfence (501,173)(0,0)[lb]1213.2ptppo (1376,363)(0,0)[lb]1213.2ptrf (1541,173)(0,0)[lb]1213.2ptaddr (1941,173)(0,0)[lb]1213.2ptppo (2041,-279)(0,0)[lb]1213.2ptpo (1541,-1123)(0,0)[lb]1213.2ptaddr (1941,-1123)(0,0)[lb]1213.2ptppo (1347,-294)(0,0)[lb]1213.2ptfr (2844,-126)(0,0)[lb]1213.2ptrf (2844,-440)(0,0)[lb]1213.2ptrf
Figure A.5: Litmus test RSW (outcome permitted)
Consider the litmus test of Figure A.5. The outcome a0=1, a1=v, a2=v, a3=0 (where v is some value written by another hart) can be observed by allowing (g) and (h) to be reordered. This might be done speculatively, and the speculation can be justified by the microarchitecture (e.g., by snooping for cache invalidations and finding none) because replaying (h) after (g) would return the value written by the same store anyway. Hence assuming a1 and a2 would end up with the same value written by the same store anyway, (g) and (h) can be legally reordered. The global memory order corresponding to this execution would be (h),(k),(a),(c),(d),(g).
Executions of the test in Figure A.5 in which a1 does not equal a2 do in fact require that (g) appears before (h) in the global memory order. Allowing (h) to appear before (g) in the global memory order would in that case result in a violation of CoRR, because then (h) would return an older value than that returned by (g). Therefore, PPO rule 2 forbids this CoRR violation from occurring. As such, PPO rule 2 strikes a careful balance between enforcing CoRR in all cases while simultaneously being weak enough to permit “RSW” and “fri-rfi” patterns that commonly appear in real microarchitectures.
There is one more overlapping-address rule: PPO rule 3 simply states that a value cannot be returned from an AMO or SC to a subsequent load until the AMO or SC has (in the case of the SC, successfully) performed globally. This follows somewhat naturally from the conceptual view that both AMOs and SC instructions are meant to be performed atomically in memory. However, notably, PPO rule 3 states that hardware may not even non-speculatively forward the value being stored by an AMOSWAP to a subsequent load, even though for AMOSWAP that store value is not actually semantically dependent on the previous value in memory, as is the case for the other AMOs. The same holds true even when forwarding from SC store values that are not semantically dependent on the value returned by the paired LR.
The three PPO rules above also apply when the memory accesses in question only overlap partially. This can occur, for example, when accesses of different sizes are used to access the same object. Note also that the base addresses of two overlapping memory operations need not necessarily be the same for two memory accesses to overlap. When misaligned memory accesses are being used, the overlapping-address PPO rules apply to each of the component memory accesses independently.
| Rule 1: There is a FENCE instruction that orders a before b |
By default, the FENCE instruction ensures that all memory accesses from instructions preceding the fence in program order (the “predecessor set”) appear earlier in the global memory order than memory accesses from instructions appearing after the fence in program order (the “successor set”). However, fences can optionally further restrict the predecessor set and/or the successor set to a smaller set of memory accesses in order to provide some speedup. Specifically, fences have PR, PW, SR, and SW bits which restrict the predecessor and/or successor sets. The predecessor set includes loads (resp. stores) if and only if PR (resp. PW) is set. Similarly, the successor set includes loads (resp. stores) if and only if SR (resp. SW) is set.
The FENCE encoding currently has nine non-trivial combinations of the four bits PR, PW, SR, and SW, plus one extra encoding FENCE.TSO which facilitates mapping of “acquire+release” or RVTSO semantics. The remaining seven combinations have empty predecessor and/or successor sets and hence are no-ops. Of the ten non-trivial options, only six are commonly used in practice:
FENCE instructions using any other combination of PR, PW, SR, and SW are reserved. We strongly recommend that programmers stick to these six. Other combinations may have unknown or unexpected interactions with the memory model.
Finally, we note that since RISC-V uses a multi-copy atomic memory model, programmers can reason about fences bits in a thread-local manner. There is no complex notion of “fence cumulativity” as found in memory models that are not multi-copy atomic.
| Rule 2: a has an acquire annotation | |
| Rule 3: b has a release annotation | |
| Rule 4: a and b both have RCsc annotations | |
| Rule 5: a is paired with b |
An acquire operation, as would be used at the start of a critical section, requires all memory operations following the acquire in program order to also follow the acquire in the global memory order. This ensures, for example, that all loads and stores inside the critical section are up to date with respect to the synchronization variable being used to protect it. Acquire ordering can be enforced in one of two ways: with an acquire annotation, which enforces ordering with respect to just the synchronization variable itself, or with a FENCE R,RW, which enforces ordering with respect to all previous loads.
sd x1, (a1) # Arbitrary unrelated store ld x2, (a2) # Arbitrary unrelated load li t0, 1 # Initialize swap value. again: amoswap.w.aq t0, t0, (a0) # Attempt to acquire lock. bnez t0, again # Retry if held. # ... # Critical section. # ... amoswap.w.rl x0, x0, (a0) # Release lock by storing 0. sd x3, (a3) # Arbitrary unrelated store ld x4, (a4) # Arbitrary unrelated load
Figure A.6: A spinlock with atomics
Consider Figure A.6. Because this example uses aq, the loads and stores in the critical section are guaranteed to appear in the global memory order after the AMOSWAP used to acquire the lock. However, assuming a0, a1, and a2 point to different memory locations, the loads and stores in the critical section may or may not appear after the “Arbitrary unrelated load” at the beginning of the example in the global memory order.
sd x1, (a1) # Arbitrary unrelated store ld x2, (a2) # Arbitrary unrelated load li t0, 1 # Initialize swap value. again: amoswap.w t0, t0, (a0) # Attempt to acquire lock. fence r, rw # Enforce "acquire" memory ordering bnez t0, again # Retry if held. # ... # Critical section. # ... fence rw, w # Enforce "release" memory ordering amoswap.w x0, x0, (a0) # Release lock by storing 0. sd x3, (a3) # Arbitrary unrelated store ld x4, (a4) # Arbitrary unrelated load
Figure A.7: A spinlock with fences
Now, consider the alternative in Figure A.7. In this case, even though the AMOSWAP does not enforce ordering with an aq bit, the fence nevertheless enforces that the acquire AMOSWAP appears earlier in the global memory order than all loads and stores in the critical section. Note, however, that in this case, the fence also enforces additional orderings: it also requires that the “Arbitrary unrelated load” at the start of the program appears earlier in the global memory order than the loads and stores of the critical section. (This particular fence does not, however, enforce any ordering with respect to the “Arbitrary unrelated store” at the start of the snippet.) In this way, fence-enforced orderings are slightly coarser than orderings enforced by .aq.
Release orderings work exactly the same as acquire orderings, just in the opposite direction. Release semantics require all loads and stores preceding the release operation in program order to also precede the release operation in the global memory order. This ensures, for example, that memory accesses in a critical section appear before the lock-releasing store in the global memory order. Just as for acquire semantics, release semantics can be enforced using release annotations or with a FENCE RW,W operation. Using the same examples, the ordering between the loads and stores in the critical section and the “Arbitrary unrelated store” at the end of the code snippet is enforced only by the FENCE RW,W in Figure A.7, not by the rl in Figure A.6.
With RCpc annotations alone, store-release-to-load-acquire ordering is not enforced. This facilitates the porting of code written under the TSO and/or RCpc memory models. To enforce store-release-to-load-acquire ordering, the code must use store-release-RCsc and load-acquire-RCsc operations so that PPO rule 4 applies. RCpc alone is sufficient for many use cases in C/C++ but is insufficient for many other use cases in C/C++, Java, and Linux, to name just a few examples; see Section A.5 for details.
PPO rule 5 indicates that an SC must appear after its paired LR in the global memory order. This will follow naturally from the common use of LR/SC to perform an atomic read-modify-write operation due to the inherent data dependency. However, PPO rule 5 also applies even when the value being stored does not syntactically depend on the value returned by the paired LR.
Lastly, we note that just as with fences, programmers need not worry about “cumulativity” when analyzing ordering annotations.
| Rule 1: b has a syntactic address dependency on a | |
| Rule 2: b has a syntactic data dependency on a | |
| Rule 3: b is a store, and b has a syntactic control dependency on a |
Dependencies from a load to a later memory operation in the same hart are respected by the RVWMO memory model. The Alpha memory model was notable for choosing not to enforce the ordering of such dependencies, but most modern hardware and software memory models consider allowing dependent instructions to be reordered too confusing and counterintuitive. Furthermore, modern code sometimes intentionally uses such dependencies as a particularly lightweight ordering enforcement mechanism.
The terms in Section 18.1 work as follows. Instructions are said to carry dependencies from their source register(s) to their destination register(s) whenever the value written into each destination register is a function of the source register(s). For most instructions, this means that the destination register(s) carry a dependency from all source register(s). However, there are a few notable exceptions. In the case of memory instructions, the value written into the destination register ultimately comes from the memory system rather than from the source register(s) directly, and so this breaks the chain of dependencies carried from the source register(s). In the case of unconditional jumps, the value written into the destination register comes from the current pc (which is never considered a source register by the memory model), and so likewise, JALR (the only jump with a source register) does not carry a dependency from rs1 to rd.
(a) fadd f3,f1,f2 (b) fadd f6,f4,f5 (c) csrrs a0,fflags,x0
The notion of accumulating into a destination register rather than writing into it reflects the behavior of CSRs such as fflags. In particular, an accumulation into a register does not clobber any previous writes or accumulations into the same register. For example, in Figure A.8, (c) has a syntactic dependency on both (a) and (b).
Like other modern memory models, the RVWMO memory model uses syntactic rather than semantic dependencies. In other words, this definition depends on the identities of the registers being accessed by different instructions, not the actual contents of those registers. This means that an address, control, or data dependency must be enforced even if the calculation could seemingly be “optimized away”. This choice ensures that RVWMO remains compatible with code that uses these false syntactic dependencies as a lightweight ordering mechanism.
ld a1,0(s0) xor a2,a1,a1 add s1,s1,a2 ld a5,0(s1)
For example, there is a syntactic address dependency from the memory operation generated by the first instruction to the memory operation generated by the last instruction in Figure A.9, even though a1 XOR a1 is zero and hence has no effect on the address accessed by the second load.
The benefit of using dependencies as a lightweight synchronization mechanism is that the ordering enforcement requirement is limited only to the specific two instructions in question. Other non-dependent instructions may be freely reordered by aggressive implementations. One alternative would be to use a load-acquire, but this would enforce ordering for the first load with respect to all subsequent instructions. Another would be to use a FENCE R,R, but this would include all previous and all subsequent loads, making this option more expensive.
lw x1,0(x2) bne x1,x0,next sw x3,0(x4) next: sw x5,0(x6)
Control dependencies behave differently from address and data dependencies in the sense that a control dependency always extends to all instructions following the original target in program order. Consider Figure A.10: the instruction at next will always execute, but the memory operation generated by that last instruction nevertheless still has a control dependency from the memory operation generated by the first instruction.
lw x1,0(x2) bne x1,x0,next next: sw x3,0(x4)
Likewise, consider Figure A.11. Even though both branch outcomes have the same target, there is still a control dependency from the memory operation generated by the first instruction in this snippet to the memory operation generated by the last instruction. This definition of control dependency is subtly stronger than what might be seen in other contexts (e.g., C++), but it conforms with standard definitions of control dependencies in the literature.
Notably, PPO rules 1–3 are also intentionally designed to respect dependencies that originate from the output of a successful store-conditional instruction. Typically, an SC instruction will be followed by a conditional branch checking whether the outcome was successful; this implies that there will be a control dependency from the store operation generated by the SC instruction to any memory operations following the branch. PPO rule 3 in turn implies that any subsequent store operations will appear later in the global memory order than the store operation generated by the SC. However, since control, address, and data dependencies are defined over memory operations, and since an unsuccessful SC does not generate a memory operation, no order is enforced between unsuccessful SC and its dependent instructions. Moreover, since SC is defined to carry dependencies from its source registers to rd only when the SC is successful, an unsuccessful SC has no effect on the global memory order.
Initial values: 0(s0)=1; 0(s2)=1 Hart 0 Hart 1 (a) ld a0,0(s0) (e) ld a3,0(s2) (b) lr a1,0(s1) (f) sd a3,0(s0) (c) sc a2,a0,0(s1) (d) sd a2,0(s2) Outcome: a0=0, a3=0 (0,0) (3104,2794)(-11,-1943) (481,599)(0,0)[b]129.6pta: Rx=0 (481,-211)(0,0)[b]129.6ptb: Rz*=0 (481,-1021)(0,0)[b]129.6ptc: Wz*=0 (481,-1831)(0,0)[b]129.6ptd: Wy=0 (2641,599)(0,0)[b]129.6pte: Ry=0 (2641,-211)(0,0)[b]129.6ptf: Wx=0 (261,281)(0,0)[lb]1213.2ptpo (646,40)(0,0)[lb]1213.2ptdata ppo (85,-529)(0,0)[lb]1213.2pt ppo (85,-1339)(0,0)[lb]1213.2ptdata ppo (1418,-538)(0,0)[lb]1213.2ptrf (2680,281)(0,0)[lb]1213.2ptdata ppo (1400,350)(0,0)[lb]1213.2ptrf
Figure A.12: A variant of the LB litmus test (outcome forbidden)
In addition, the choice to respect dependencies originating at store-conditional instructions ensures that certain out-of-thin-air-like behaviors will be prevented. Consider Figure A.12. Suppose a hypothetical implementation could occasionally make some early guarantee that a store-conditional operation will succeed. In this case, (c) could return 0 to a2 early (before actually executing), allowing the sequence (d), (e), (f), (a), and then (b) to execute, and then (c) might execute (successfully) only at that point. This would imply that (c) writes its own success value to 0(s1)! Fortunately, this situation and others like it are prevented by the fact that RVWMO respects dependencies originating at the stores generated by successful SC instructions.
We also note that syntactic dependencies between instructions only have any force when they take the form of a syntactic address, control, and/or data dependency. For example: a syntactic dependency between two “F” instructions via one of the “accumulating CSRs” in Section 18.3 does not imply that the two “F” instructions must be executed in order. Such a dependency would only serve to ultimately set up later a dependency from both “F” instructions to a later CSR instruction accessing the CSR flag in question.
| Rule 1: b is a load, and there exists some store m between a and b in program order such that m has an address or data dependency on a, and b returns a value written by m | |
| Rule 2: b is a store, and there exists some instruction m between a and b in program order such that m has an address dependency on a |
Hart 0 Hart 1 li t1, 1 (d) lw a0, 0(s1) (a) sw t1,0(s0) (e) sw a0, 0(s2) (b) fence w, w (f) lw a1, 0(s2) (c) sw t1,0(s1) xor a2,a1,a1 add s0,s0,a2 (g) lw a3,0(s0) Outcome: a0=1, a3=0 (0,0) (3886,2794)(-14,-1943) (821,-211)(0,0)[b]129.6pta: Wx=1 (821,-1021)(0,0)[b]129.6ptc: Wy=1 (2981,599)(0,0)[b]129.6ptd: Ry=1 (2981,-211)(0,0)[b]129.6pte: Wz=1 (2981,-1021)(0,0)[b]129.6ptf: Rz=1 (2981,-1831)(0,0)[b]129.6ptg: Rx=0 ( 1,-575)(0,0)[lb]1213.2ptfence (460,-575)(0,0)[lb]1213.2ptppo (1739,-122)(0,0)[lb]1213.2ptrf (2581,250)(0,0)[lb]1213.2ptdata (3011,250)(0,0)[lb]1213.2ptppo (3540,-121)(0,0)[lb]1213.2ptppo (2821,-769)(0,0)[lb]1213.2ptrf (2561,-1295)(0,0)[lb]1213.2ptaddr (3031 ,-1295)(0,0)[lb]1213.2ptppo (2043,-732)(0,0)[lb]1213.2ptfr
Figure A.13: Because of PPO rule 1 and the data dependency from (d) to (e), (d) must also precede (f) in the global memory order (outcome forbidden)
PPO rules 1 and 2 reflect behaviors of almost all real processor pipeline implementations. Rule 1 states that a load cannot forward from a store until the address and data for that store are known. Consider Figure A.13: (f) cannot be executed until the data for (e) has been resolved, because (f) must return the value written by (e) (or by something even later in the global memory order), and the old value must not be clobbered by the writeback of (e) before (d) has had a chance to perform. Therefore, (f) will never perform before (d) has performed.
Hart 0 Hart 1 li t1, 1 li t1, 1 (a) sw t1,0(s0) (d) lw a0, 0(s1) (b) fence w, w (e) sw a0, 0(s2) (c) sw t1,0(s1) (f) sw t1, 0(s2) (g) lw a1, 0(s2) xor a2,a1,a1 add s0,s0,a2 (h) lw a3,0(s0) Outcome: a0=1, a3=0 (0,0) (3447,3604)(-14,-2753) (821,-616)(0,0)[b]129.6pta: Wx=1 (821,-1426)(0,0)[b]129.6ptc: Wy=1 (2981,599)(0,0)[b]129.6ptd: Ry=1 (2981,-211)(0,0)[b]129.6pte: Wz=1 (2981,-1021)(0,0)[b]129.6ptf: Wz=1 (2981,-1831)(0,0)[b]129.6ptg: Rz=1 (2981,-2641)(0,0)[b]129.6pth: Rx=0 ( 1,-990)(0,0)[lb]1213.2ptfence (460,-990)(0,0)[lb]1213.2ptppo (1739,-325)(0,0)[lb]1213.2ptrf (2601,225)(0,0)[lb]1213.2ptdata (3031,225)(0,0)[lb]1213.2ptppo (2741,-485)(0,0)[lb]1213.2ptco (3031,-485)(0,0)[lb]1213.2ptppo (2821,-1339)(0,0)[lb]1213.2ptrf (2561,-2105)(0,0)[lb]1213.2ptaddr (3031,-2105)(0,0)[lb]1213.2ptppo (1743,-1340)(0,0)[lb]1213.2ptfr
Figure A.14: Because of the extra store between (e) and (g), (d) no longer necessarily precedes (g) (outcome permitted)
If there were another store to the same address in between (e) and (f), as in Figure A.14, then (f) would no longer be dependent on the data of (e) being resolved, and hence the dependency of (f) on (d), which produces the data for (e), would be broken.
Rule 2 makes a similar observation to the previous rule: a store cannot be performed at memory until all previous loads that might access the same address have themselves been performed. Such a load must appear to execute before the store, but it cannot do so if the store were to overwrite the value in memory before the load had a chance to read the old value. Likewise, a store generally cannot be performed until it is known that preceding instructions will not cause an exception due to failed address resolution, and in this sense, rule 2 can be seen as somewhat of a special case of rule 3.
Hart 0 Hart 1 li t1, 1 (a) lw a0,0(s0) (d) lw a1, 0(s1) (b) fence rw,rw (e) lw a2, 0(a1) (c) sw s2,0(s1) (f) sw t1, 0(s0) Outcome: a0=1, a1=t (0,0) (3628,1984)(-14,-1133) (821,599)(0,0)[b]129.6pta: Ry=1 (821,-211)(0,0)[b]129.6ptc: Wx=t (2981,599)(0,0)[b]129.6ptd: Rx=t (2981,-211)(0,0)[b]129.6pte: Rt=v (2981,-1021)(0,0)[b]129.6ptf: Wy=1 ( 1, 240)(0,0)[lb]1213.2ptfence (461, 240)(0,0)[lb]1213.2ptppo (1742,284)(0,0)[lb]1213.2ptrf (2561, 250)(0,0)[lb]1213.2ptaddr (3011, 250)(0,0)[lb]1213.2ptppo (3185,-400)(0,0)[lb]1213.2ptppo (2731,-529)(0,0)[lb]1213.2ptpo (1743,20)(0,0)[lb]1213.2ptrf
Figure A.15: Because of the address dependency from (d) to (e), (d) also precedes (f) (outcome forbidden)
Consider Figure A.15: (f) cannot be executed until the address for (e) is resolved, because it may turn out that the addresses match; i.e., that a1=s0. Therefore, (f) cannot be sent to memory before (d) has executed and confirmed whether the addresses do indeed overlap.
RVWMO does not currently attempt to formally describe how FENCE.I, SFENCE.VMA, I/O fences, and PMAs behave. All of these behaviors will be described by future formalizations. In the meantime, the behavior of FENCE.I is described in Chapter 4, the behavior of SFENCE.VMA is described in the RISC-V Instruction Set Privileged Architecture Manual, and the behavior of I/O fences and the effects of PMAs are described below.
The RISC-V Privileged ISA defines Physical Memory Attributes (PMAs) which specify, among other things, whether portions of the address space are coherent and/or cacheable. See the RISC-V Privileged ISA Specification for the complete details. Here, we simply discuss how the various details in each PMA relate to the memory model:
For I/O, the load value axiom and atomicity axiom in general do not apply, as both reads and writes might have device-specific side effects and may return values other than the value “written” by the most recent store to the same address. Nevertheless, the following preserved program order rules still generally apply for accesses to I/O memory: memory access a precedes memory access b in global memory order if a precedes b in program order and one or more of the following holds:
Note that the FENCE instruction distinguishes between main memory operations and I/O operations in its predecessor and successor sets. To enforce ordering between I/O operations and main memory operations, code must use a FENCE with PI, PO, SI, and/or SO, plus PR, PW, SR, and/or SW. For example, to enforce ordering between a write to main memory and an I/O write to a device register, a FENCE W,O or stronger is needed.
sd t0, 0(a0) fence w,o sd a0, 0(a1)
When a fence is in fact used, implementations must assume that the device may attempt to access memory immediately after receiving the MMIO signal, and subsequent memory accesses from that device to memory must observe the effects of all accesses ordered prior to that MMIO operation. In other words, in Figure A.16, suppose 0(a0) is in main memory and 0(a1) is the address of a device register in I/O memory. If the device accesses 0(a0) upon receiving the MMIO write, then that load must conceptually appear after the first store to 0(a0) according to the rules of the RVWMO memory model. In some implementations, the only way to ensure this will be to require that the first store does in fact complete before the MMIO write is issued. Other implementations may find ways to be more aggressive, while others still may not need to do anything different at all for I/O and main memory accesses. Nevertheless, the RVWMO memory model does not distinguish between these options; it simply provides an implementation-agnostic mechanism to specify the orderings that must be enforced.
Many architectures include separate notions of “ordering” and “completion” fences, especially as it relates to I/O (as opposed to regular main memory). Ordering fences simply ensure that memory operations stay in order, while completion fences ensure that predecessor accesses have all completed before any successors are made visible. RISC-V does not explicitly distinguish between ordering and completion fences. Instead, this distinction is simply inferred from different uses of the FENCE bits.
For implementations that conform to the RISC-V Unix Platform Specification, I/O devices and DMA operations are required to access memory coherently and via strongly ordered I/O channels. Therefore, accesses to regular main memory regions that are concurrently accessed by external devices can also use the standard synchronization mechanisms. Implementations that do not conform to the Unix Platform Specification and/or in which devices do not access memory coherently will need to use mechanisms (which are currently platform-specific or device-specific) to enforce coherency.
I/O regions in the address space should be considered non-cacheable regions in the PMAs for those regions. Such regions can be considered coherent by the PMA if they are not cached by any agent.
The ordering guarantees in this section may not apply beyond a platform-specific boundary between the RISC-V cores and the device. In particular, I/O accesses sent across an external bus (e.g., PCIe) may be reordered before they reach their ultimate destination. Ordering must be enforced in such situations according to the platform-specific rules of those external devices and buses.
Table A.2 provides a mapping from TSO memory operations onto RISC-V memory instructions. Normal x86 loads and stores are all inherently acquire-RCpc and release-RCpc operations: TSO enforces all load-load, load-store, and store-store ordering by default. Therefore, under RVWMO, all TSO loads must be mapped onto a load followed by FENCE R,RW, and all TSO stores must be mapped onto FENCE RW,W followed by a store. TSO atomic read-modify-writes and x86 instructions using the LOCK prefix are fully ordered and can be implemented either via an AMO with both aq and rl set, or via an LR with aq set, the arithmetic operation in question, an SC with both aq and rl set, and a conditional branch checking the success condition. In the latter case, the rl annotation on the LR turns out (for non-obvious reasons) to be redundant and can be omitted.
Alternatives to Table A.2 are also possible. A TSO store can be mapped onto AMOSWAP with rl set. However, since RVWMO PPO Rule 3 forbids forwarding of values from AMOs to subsequent loads, the use of AMOSWAP for stores may negatively affect performance. A TSO load can be mapped using LR with aq set: all such LR instructions will be unpaired, but that fact in and of itself does not preclude the use of LR for loads. However, again, this mapping may also negatively affect performance if it puts more pressure on the reservation mechanism than was originally intended.
Table A.3 provides a mapping from Power memory operations onto RISC-V memory instructions. Power ISYNC maps on RISC-V to a FENCE.I followed by a FENCE R,R; the latter fence is needed because ISYNC is used to define a “control+control fence” dependency that is not present in RVWMO.
ARM Operation RVWMO Mapping Load l{b|h|w|d} Load-Acquire fence rw, rw; l{b|h|w|d}; fence r,rw Load-Exclusive lr.{w|d} Load-Acquire-Exclusive lr.{w|d}.aqrl Store s{b|h|w|d} Store-Release fence rw,w; s{b|h|w|d} Store-Exclusive sc.{w|d} Store-Release-Exclusive sc.{w|d}.rl dmb fence rw,rw dmb.ld fence r,rw dmb.st fence w,w isb fence.i; fence r,r
Table A.4: Mappings from ARM operations to RISC-V operations
Table A.4 provides a mapping from ARM memory operations onto RISC-V memory instructions. Since RISC-V does not currently have plain load and store opcodes with aq or rl annotations, ARM load-acquire and store-release operations should be mapped using fences instead. Furthermore, in order to enforce store-release-to-load-acquire ordering, there must be a FENCE RW,RW between the store-release and load-acquire; Table A.4 enforces this by always placing the fence in front of each acquire operation. ARM load-exclusive and store-exclusive instructions can likewise map onto their RISC-V LR and SC equivalents, but instead of placing a FENCE RW,RW in front of an LR with aq set, we simply also set rl instead. ARM ISB maps on RISC-V to FENCE.I followed by FENCE R,R similarly to how ISYNC maps for Power.
Linux Operation RVWMO Mapping smp_mb() fence rw,rw smp_rmb() fence r,r smp_wmb() fence w,w dma_rmb() fence r,r dma_wmb() fence w,w mb() fence iorw,iorw rmb() fence ri,ri wmb() fence wo,wo smp_load_acquire() l{b|h|w|d}; fence r,rw smp_store_release() fence.tso; s{b|h|w|d} Linux Construct RVWMO AMO Mapping atomic_<op>_relaxed amo<op>.{w|d} atomic_<op>_acquire amo<op>.{w|d}.aq atomic_<op>_release amo<op>.{w|d}.rl atomic_<op> amo<op>.{w|d}.aqrl Linux Construct RVWMO LR/SC Mapping atomic_<op>_relaxed loop: lr.{w|d}; <op>; sc.{w|d}; bnez loop atomic_<op>_acquire loop: lr.{w|d}.aq; <op>; sc.{w|d}; bnez loop 2*atomic_<op>_release loop: lr.{w|d}; <op>; sc.{w|d}.aqrl*; bnez loop OR fence.tso; loop: lr.{w|d}; <op>; sc.{w|d}*; bnez loop atomic_<op> loop: lr.{w|d}.aq; <op>; sc.{w|d}.aqrl; bnez loop
Table A.5: Mappings from Linux memory primitives to RISC-V primitives. Other constructs (such as spinlocks) should follow accordingly. Platforms or devices with non-coherent DMA may need additional synchronization (such as cache flush or invalidate mechanisms); currently any such extra synchronization will be device-specific.
Table A.5 provides a mapping of Linux memory ordering macros onto RISC-V memory instructions. The Linux fences dma_rmb() and dma_wmb() map onto FENCE R,R and FENCE W,W, respectively, since the RISC-V Unix Platform requires coherent DMA, but would be mapped onto FENCE RI,RI and FENCE WO,WO, respectively, on a platform with non-coherent DMA. Platforms with non-coherent DMA may also require a mechanism by which cache lines can be flushed and/or invalidated. Such mechanisms will be device-specific and/or standardized in a future extension to the ISA.
The Linux mappings for release operations may seem stronger than necessary, but these mappings are needed to cover some cases in which Linux requires stronger orderings than the more intuitive mappings would provide. In particular, as of the time this text is being written, Linux is actively debating whether to require load-load, load-store, and store-store orderings between accesses in one critical section and accesses in a subsequent critical section in the same hart and protected by the same synchronization object. Not all combinations of FENCE RW,W/FENCE R,RW mappings with aq/rl mappings combine to provide such orderings. There are a few ways around this problem, including:
Linux code: (a) int r0 = *x; (bc) spin_unlock(y, 0); ... ... (d) spin_lock(y); (e) int r1 = *z; RVWMO Mapping: (a) lw a0, 0(s0) (b) fence.tso // vs. fence rw,w (c) sd x0,0(s1) ... loop: (d) amoswap.d.aq a1,t1,0(s1) bnez a1,loop (e) lw a2,0(s2)
Figure A.17: Orderings between critical sections in Linux
For example, the critical section ordering rule currently being debated by the Linux community would require (a) to be ordered before (e) in Figure A.17. If that will indeed be required, then it would be insufficient for (b) to map as FENCE RW,W. That said, these mappings are subject to change as the Linux Kernel Memory Model evolves.
C/C++ Construct RVWMO Mapping Non-atomic load l{b|h|w|d} atomic_load(memory_order_relaxed) l{b|h|w|d} atomic_load(memory_order_acquire) l{b|h|w|d}; fence r,rw atomic_load(memory_order_seq_cst) fence rw,rw; l{b|h|w|d}; fence r,rw Non-atomic store s{b|h|w|d} atomic_store(memory_order_relaxed) s{b|h|w|d} atomic_store(memory_order_release) fence rw,w; s{b|h|w|d} atomic_store(memory_order_seq_cst) fence rw,w; s{b|h|w|d} atomic_thread_fence(memory_order_acquire) fence r,rw atomic_thread_fence(memory_order_release) fence rw,w atomic_thread_fence(memory_order_acq_rel) fence.tso atomic_thread_fence(memory_order_seq_cst) fence rw,rw C/C++ Construct RVWMO AMO Mapping atomic_<op>(memory_order_relaxed) amo<op>.{w|d} atomic_<op>(memory_order_acquire) amo<op>.{w|d}.aq atomic_<op>(memory_order_release) amo<op>.{w|d}.rl atomic_<op>(memory_order_acq_rel) amo<op>.{w|d}.aqrl atomic_<op>(memory_order_seq_cst) amo<op>.{w|d}.aqrl C/C++ Construct RVWMO LR/SC Mapping 2*atomic_<op>(memory_order_relaxed) loop: lr.{w|d}; <op>; sc.{w|d}; bnez loop 2*atomic_<op>(memory_order_acquire) loop: lr.{w|d}.aq; <op>; sc.{w|d}; bnez loop 2*atomic_<op>(memory_order_release) loop: lr.{w|d}; <op>; sc.{w|d}.rl; bnez loop 2*atomic_<op>(memory_order_acq_rel) loop: lr.{w|d}.aq; <op>; sc.{w|d}.rl; bnez loop 2*atomic_<op>(memory_order_seq_cst) loop: lr.{w|d}.aqrl; <op>; sc.{w|d}.rl; bnez loop
Table A.6: Mappings from C/C++ primitives to RISC-V primitives.
C/C++ Construct RVWMO Mapping Non-atomic load l{b|h|w|d} atomic_load(memory_order_relaxed) l{b|h|w|d} atomic_load(memory_order_acquire) l{b|h|w|d}.aq atomic_load(memory_order_seq_cst) l{b|h|w|d}.aq Non-atomic store s{b|h|w|d} atomic_store(memory_order_relaxed) s{b|h|w|d} atomic_store(memory_order_release) s{b|h|w|d}.rl atomic_store(memory_order_seq_cst) s{b|h|w|d}.rl atomic_thread_fence(memory_order_acquire) fence r,rw atomic_thread_fence(memory_order_release) fence rw,w atomic_thread_fence(memory_order_acq_rel) fence.tso atomic_thread_fence(memory_order_seq_cst) fence rw,rw C/C++ Construct RVWMO AMO Mapping atomic_<op>(memory_order_relaxed) amo<op>.{w|d} atomic_<op>(memory_order_acquire) amo<op>.{w|d}.aq atomic_<op>(memory_order_release) amo<op>.{w|d}.rl atomic_<op>(memory_order_acq_rel) amo<op>.{w|d}.aqrl atomic_<op>(memory_order_seq_cst) amo<op>.{w|d}.aqrl C/C++ Construct RVWMO LR/SC Mapping atomic_<op>(memory_order_relaxed) lr.{w|d}; <op>; sc.{w|d} atomic_<op>(memory_order_acquire) lr.{w|d}.aq; <op>; sc.{w|d} atomic_<op>(memory_order_release) lr.{w|d}; <op>; sc.{w|d}.rl atomic_<op>(memory_order_acq_rel) lr.{w|d}.aq; <op>; sc.{w|d}.rl atomic_<op>(memory_order_seq_cst) lr.{w|d}.aq*; <op>; sc.{w|d}.rl *must be lr.{w|d}.aqrl in order to interoperate with code mapped per Table A.6
Table A.7: Hypothetical mappings from C/C++ primitives to RISC-V primitives, if native load-acquire and store-release opcodes are introduced.
Table A.6 provides a mapping of C11/C++11 atomic operations onto RISC-V memory instructions. If load and store opcodes with aq and rl modifiers are introduced, then the mappings in Table A.7 will suffice. Note however that the two mappings only interoperate correctly if atomic_<op>(memory_order_seq_cst) is mapped using an LR that has both aq and rl set.
Any AMO can be emulated by an LR/SC pair, but care must be taken to ensure that any PPO orderings that originate from the LR are also made to originate from the SC, and that any PPO orderings that terminate at the SC are also made to terminate at the LR. For example, the LR must also be made to respect any data dependencies that the AMO has, given that load operations do not otherwise have any notion of a data dependency. Likewise, the effect a FENCE R,R elsewhere in the same hart must also be made to apply to the SC, which would not otherwise respect that fence. The emulator may achieve this effect by simply mapping AMOs onto lr.aq; <op>; sc.aqrl, matching the mapping used elsewhere for fully ordered atomics.
These C11/C++11 mappings require the platform to provide the following Physical Memory Attributes (as defined in the RISC-V Privileged ISA) for all memory:
Platforms with different attributes may require different mappings, or require platform-specific SW (e.g., memory-mapped I/O).
The RVWMO and RVTSO memory models by no means preclude microarchitectures from employing sophisticated speculation techniques or other forms of optimization in order to deliver higher performance. The models also do not impose any requirement to use any one particular cache hierarchy, nor even to use a cache coherence protocol at all. Instead, these models only specify the behaviors that can be exposed to software. Microarchitectures are free to use any pipeline design, any coherent or non-coherent cache hierarchy, any on-chip interconnect, etc., as long as the design only admits executions that satisfy the memory model rules. That said, to help people understand the actual implementations of the memory model, in this section we provide some guidelines on how architects and programmers should interpret the models’ rules.
Both RVWMO and RVTSO are multi-copy atomic (or “other-multi-copy-atomic”): any store value that is visible to a hart other than the one that originally issued it must also be conceptually visible to all other harts in the system. In other words, harts may forward from their own previous stores before those stores have become globally visible to all harts, but no early inter-hart forwarding is permitted. Multi-copy atomicity may be enforced in a number of ways. It might hold inherently due to the physical design of the caches and store buffers, it may be enforced via a single-writer/multiple-reader cache coherence protocol, or it might hold due to some other mechanism.
Although multi-copy atomicity does impose some restrictions on the microarchitecture, it is one of the key properties keeping the memory model from becoming extremely complicated. For example, a hart may not legally forward a value from a neighbor hart’s private store buffer (unless of course it is done in such a way that no new illegal behaviors become architecturally visible). Nor may a cache coherence protocol forward a value from one hart to another until the coherence protocol has invalidated all older copies from other caches. Of course, microarchitectures may (and high-performance implementations likely will) violate these rules under the covers through speculation or other optimizations, as long as any non-compliant behaviors are not exposed to the programmer.
As a rough guideline for interpreting the PPO rules in RVWMO, we expect the following from the software perspective:
We also expect the following from the hardware perspective:
Architectures are free to implement any of the memory model rules as conservatively as they choose. For example, a hardware implementation may choose to do any or all of the following:
Architectures that implement RVTSO can safely do the following:
Other general notes:
The question of write subsumption can be understood from the following example:
Hart 0 Hart 1 li t1, 3 li t3, 2 li t2, 1 (a) sw t1,0(s0) (d) lw a0,0(s1) (b) fence w, w (e) sw a0,0(s0) (c) sw t2,0(s1) (f) sw t3,0(s0) (0,0) (3447,1984)(-14,-1133) (821,599)(0,0)[b]129.6pta: Wx=3 (821,-211)(0,0)[b]129.6ptc: Wy=1 (2981,-211)(0,0)[b]129.6pte: Wx=1 (2981,599)(0,0)[b]129.6ptd: Ry=1 (2981,-1021)(0,0)[b]129.6ptf: Wx=2 ( -40, 190)(0,0)[lb]1213.2ptfence (450, 190)(0,0)[lb]1213.2ptppo (1673,380)(0,0)[lb]1213.2ptco (1742, 44)(0,0)[lb]1213.2ptrf (2261, 230)(0,0)[lb]1213.2ptdata (2650, 230)(0,0)[lb]1213.2ptppo (2420,-485)(0,0)[lb]1213.2ptco (2630,-485)(0,0)[lb]1213.2ptppo
Figure A.18: Write subsumption litmus test, allowed execution.
As written, if the load (d) reads value 1, then (a) must precede (f) in the global memory order:
In other words the final value of the memory location whose address is in s0 must be 2 (the value written by the store (f)) and cannot be 3 (the value written by the store (a)).
A very aggressive microarchitecture might erroneously decide to discard (e), as (f) supersedes it, and this may in turn lead the microarchitecture to break the now-eliminated dependency between (d) and (f) (and hence also between (a) and (f)). This would violate the memory model rules, and hence it is forbidden. Write subsumption may in other cases be legal, if for example there were no data dependency between (d) and (e).
We expect that any or all of the following possible future extensions would be compatible with the RVWMO memory model:
Hart 0 Hart 1 li t1, 1 li t1, 1 (a) lw a0,0(s0) (d) lw a1,0(s1) (b) fence rw,rw (e) amoswap.w.rl a2,t1,0(s2) (c) sw t1,0(s1) (f) ld a3,0(s2) (g) lw a4,4(s2) xor a5,a4,a4 add s0,s0,a5 (h) sw a2,0(s0) Outcome: a0=1, a1=1, a2=0, a3=1, a4=0
Figure A.19: Mixed-size discrepancy (permitted by axiomatic models, forbidden by operational model)
There is a known discrepancy between the operational and axiomatic specifications within the family of mixed-size RSW variants shown in Figures A.19–A.21. To address this, we may choose to add something like the following new PPO rule: Memory operation a precedes memory operation b in preserved program order (and hence also in the global memory order) if a precedes b in program order, a and b both access regular main memory (rather than I/O regions), a is a load, b is a store, there is a load m between a and b, there is a byte x that both a and m read, there is no store between a and m that writes to x, and m precedes b in PPO. In other words, in herd syntax, we may choose to add “(po-loc & rsw);ppo;[W]” to PPO. Many implementations will already enforce this ordering naturally. As such, even though this rule is not official, we recommend that implementers enforce it nevertheless in order to ensure forwards compatibility with the possible future addition of this rule to RVWMO.
To facilitate formal analysis of RVWMO, this chapter presents a set of formalizations using different tools and modeling approaches. Any discrepancies are unintended; the expectation is that the models describe exactly the same sets of legal behaviors.
This appendix should be treated as commentary; all normative material is provided in Chapter 18 and in the rest of the main body of the ISA specification. All currently known discrepancies are listed in Section A.7. Any other discrepancies are unintentional.
We present a formal specification of the RVWMO memory model in Alloy (http://alloy.mit.edu). This model is available online at https://github.com/daniellustig/riscv-memory-model.
The online material also contains some litmus tests and some examples of how Alloy can be used to model check some of the mappings in Section A.5.
//////////////////////////////////////////////////////////////////////////////// // =RVWMO PPO= // Preserved Program Order fun ppo : Event->Event { // same-address ordering po_loc :> Store + rdw + (AMO + StoreConditional) <: rfi // explicit synchronization + ppo_fence + Acquire <: ^po :> MemoryEvent + MemoryEvent <: ^po :> Release + RCsc <: ^po :> RCsc + pair // syntactic dependencies + addrdep + datadep + ctrldep :> Store // pipeline dependencies + (addrdep+datadep).rfi + addrdep.^po :> Store } // the global memory order respects preserved program order fact { ppo in ^gmo }
Figure B.1: The RVWMO memory model formalized in Alloy (1/5: PPO)
//////////////////////////////////////////////////////////////////////////////// // =RVWMO axioms= // Load Value Axiom fun candidates[r: MemoryEvent] : set MemoryEvent { (r.~^gmo & Store & same_addr[r]) // writes preceding r in gmo + (r.^~po & Store & same_addr[r]) // writes preceding r in po } fun latest_among[s: set Event] : Event { s - s.~^gmo } pred LoadValue { all w: Store | all r: Load | w->r in rf <=> w = latest_among[candidates[r]] } // Atomicity Axiom pred Atomicity { all r: Store.~pair | // starting from the lr, no x: Store & same_addr[r] | // there is no store x to the same addr x not in same_hart[r] // such that x is from a different hart, and x in r.~rf.^gmo // x follows (the store r reads from) in gmo, and r.pair in x.^gmo // and r follows x in gmo } // Progress Axiom implicit: Alloy only considers finite executions pred RISCV_mm { LoadValue and Atomicity /* and Progress */ }
Figure B.2: The RVWMO memory model formalized in Alloy (2/5: Axioms)
//////////////////////////////////////////////////////////////////////////////// // Basic model of memory sig Hart { // hardware thread start : one Event } sig Address {} abstract sig Event { po: lone Event // program order } abstract sig MemoryEvent extends Event { address: one Address, acquireRCpc: lone MemoryEvent, acquireRCsc: lone MemoryEvent, releaseRCpc: lone MemoryEvent, releaseRCsc: lone MemoryEvent, addrdep: set MemoryEvent, ctrldep: set Event, datadep: set MemoryEvent, gmo: set MemoryEvent, // global memory order rf: set MemoryEvent } sig LoadNormal extends MemoryEvent {} // l{b|h|w|d} sig LoadReserve extends MemoryEvent { // lr pair: lone StoreConditional } sig StoreNormal extends MemoryEvent {} // s{b|h|w|d} // all StoreConditionals in the model are assumed to be successful sig StoreConditional extends MemoryEvent {} // sc sig AMO extends MemoryEvent {} // amo sig NOP extends Event {} fun Load : Event { LoadNormal + LoadReserve + AMO } fun Store : Event { StoreNormal + StoreConditional + AMO } sig Fence extends Event { pr: lone Fence, // opcode bit pw: lone Fence, // opcode bit sr: lone Fence, // opcode bit sw: lone Fence // opcode bit } sig FenceTSO extends Fence {} /* Alloy encoding detail: opcode bits are either set (encoded, e.g., * as f.pr in iden) or unset (f.pr not in iden). The bits cannot be used for * anything else */ fact { pr + pw + sr + sw in iden } // likewise for ordering annotations fact { acquireRCpc + acquireRCsc + releaseRCpc + releaseRCsc in iden } // don't try to encode FenceTSO via pr/pw/sr/sw; just use it as-is fact { no FenceTSO.(pr + pw + sr + sw) }
Figure B.3: The RVWMO memory model formalized in Alloy (3/5: model of memory)
//////////////////////////////////////////////////////////////////////////////// // =Basic model rules= // Ordering annotation groups fun Acquire : MemoryEvent { MemoryEvent.acquireRCpc + MemoryEvent.acquireRCsc } fun Release : MemoryEvent { MemoryEvent.releaseRCpc + MemoryEvent.releaseRCsc } fun RCpc : MemoryEvent { MemoryEvent.acquireRCpc + MemoryEvent.releaseRCpc } fun RCsc : MemoryEvent { MemoryEvent.acquireRCsc + MemoryEvent.releaseRCsc } // There is no such thing as store-acquire or load-release, unless it's both fact { Load & Release in Acquire } fact { Store & Acquire in Release } // FENCE PPO fun FencePRSR : Fence { Fence.(pr & sr) } fun FencePRSW : Fence { Fence.(pr & sw) } fun FencePWSR : Fence { Fence.(pw & sr) } fun FencePWSW : Fence { Fence.(pw & sw) } fun ppo_fence : MemoryEvent->MemoryEvent { (Load <: ^po :> FencePRSR).(^po :> Load) + (Load <: ^po :> FencePRSW).(^po :> Store) + (Store <: ^po :> FencePWSR).(^po :> Load) + (Store <: ^po :> FencePWSW).(^po :> Store) + (Load <: ^po :> FenceTSO) .(^po :> MemoryEvent) + (Store <: ^po :> FenceTSO) .(^po :> Store) } // auxiliary definitions fun po_loc : Event->Event { ^po & address.~address } fun same_hart[e: Event] : set Event { e + e.^~po + e.^po } fun same_addr[e: Event] : set Event { e.address.~address } // initial stores fun NonInit : set Event { Hart.start.*po } fun Init : set Event { Event - NonInit } fact { Init in StoreNormal } fact { Init->(MemoryEvent & NonInit) in ^gmo } fact { all e: NonInit | one e.*~po.~start } // each event is in exactly one hart fact { all a: Address | one Init & a.~address } // one init store per address fact { no Init <: po and no po :> Init }
Figure B.4: The RVWMO memory model formalized in Alloy (4/5: Basic model rules)
// po fact { acyclic[po] } // gmo fact { total[^gmo, MemoryEvent] } // gmo is a total order over all MemoryEvents //rf fact { rf.~rf in iden } // each read returns the value of only one write fact { rf in Store <: address.~address :> Load } fun rfi : MemoryEvent->MemoryEvent { rf & (*po + *~po) } //dep fact { no StoreNormal <: (addrdep + ctrldep + datadep) } fact { addrdep + ctrldep + datadep + pair in ^po } fact { datadep in datadep :> Store } fact { ctrldep.*po in ctrldep } fact { no pair & (^po :> (LoadReserve + StoreConditional)).^po } fact { StoreConditional in LoadReserve.pair } // assume all SCs succeed // rdw fun rdw : Event->Event { (Load <: po_loc :> Load) // start with all same_address load-load pairs, - (~rf.rf) // subtract pairs that read from the same store, - (po_loc.rfi) // and subtract out "fri-rfi" patterns } // filter out redundant instances and/or visualizations fact { no gmo & gmo.gmo } // keep the visualization uncluttered fact { all a: Address | some a.~address } //////////////////////////////////////////////////////////////////////////////// // =Optional: opcode encoding restrictions= // the list of blessed fences fact { Fence in Fence.pr.sr + Fence.pw.sw + Fence.pr.pw.sw + Fence.pr.sr.sw + FenceTSO + Fence.pr.pw.sr.sw } pred restrict_to_current_encodings { no (LoadNormal + StoreNormal) & (Acquire + Release) } //////////////////////////////////////////////////////////////////////////////// // =Alloy shortcuts= pred acyclic[rel: Event->Event] { no iden & ^rel } pred total[rel: Event->Event, bag: Event] { all disj e, e': bag | e->e' in rel + ~rel acyclic[rel] }
Figure B.5: The RVWMO memory model formalized in Alloy (5/5: Auxiliaries)
The tool herd takes a memory model and a litmus test as input and simulates the execution of the test on top of the memory model. Memory models are written in the domain specific language Cat. This section provides two Cat memory model of RVWMO. The first model, Figure B.7, follows the global memory order, Chapter 18, definition of RVWMO, as much as is possible for a Cat model. The second model, Figure B.8, is an equivalent, more efficient, partial order based RVWMO model.
The simulator herd is part of the diy tool suite — see http://diy.inria.fr for software and documentation. The models and more are available online at http://diy.inria.fr/cats7/riscv/.
(*************) (* Utilities *) (*************) (* All fence relations *) let fence.r.r = [R];fencerel(Fence.r.r);[R] let fence.r.w = [R];fencerel(Fence.r.w);[W] let fence.r.rw = [R];fencerel(Fence.r.rw);[M] let fence.w.r = [W];fencerel(Fence.w.r);[R] let fence.w.w = [W];fencerel(Fence.w.w);[W] let fence.w.rw = [W];fencerel(Fence.w.rw);[M] let fence.rw.r = [M];fencerel(Fence.rw.r);[R] let fence.rw.w = [M];fencerel(Fence.rw.w);[W] let fence.rw.rw = [M];fencerel(Fence.rw.rw);[M] let fence.tso = let f = fencerel(Fence.tso) in ([W];f;[W]) | ([R];f;[M]) let fence = fence.r.r | fence.r.w | fence.r.rw | fence.w.r | fence.w.w | fence.w.rw | fence.rw.r | fence.rw.w | fence.rw.rw | fence.tso (* Same address, no W to the same address in-between *) let po-loc-no-w = po-loc \ (po-loc?;[W];po-loc) (* Read same write *) let rsw = rf^-1;rf (* Acquire, or stronger *) let AQ = Acq|AcqRel (* Release or stronger *) and RL = RelAcqRel (* All RCsc *) let RCsc = Acq|Rel|AcqRel (* Amo events are both R and W, relation rmw relates paired lr/sc *) let AMO = R & W let StCond = range(rmw) (*************) (* ppo rules *) (*************) (* Overlapping-Address Orderings *) let r1 = [M];po-loc;[W] and r2 = ([R];po-loc-no-w;[R]) \ rsw and r3 = [AMO|StCond];rfi;[R] (* Explicit Synchronization *) and r4 = fence and r5 = [AQ];po;[M] and r6 = [M];po;[RL] and r7 = [RCsc];po;[RCsc] and r8 = rmw (* Syntactic Dependencies *) and r9 = [M];addr;[M] and r10 = [M];data;[W] and r11 = [M];ctrl;[W] (* Pipeline Dependencies *) and r12 = [R];(addr|data);[W];rfi;[R] and r13 = [R];addr;[M];po;[W] let ppo = r1 | r2 | r3 | r4 | r5 | r6 | r7 | r8 | r9 | r10 | r11 | r12 | r13
Figure B.6: riscv-defs.cat, a herd definition of preserved program order (1/3)
Total (* Notice that herd has defined its own rf relation *) (* Define ppo *) include "riscv-defs.cat" (********************************) (* Generate global memory order *) (********************************) let gmo0 = (* precursor: ie build gmo as an total order that include gmo0 *) loc & (W\FW) * FW | # Final write after any write to the same location ppo | # ppo compatible rfe # includes herd external rf (optimization) (* Walk over all linear extensions of gmo0 *) with gmo from linearizations(M\IW,gmo0) (* Add initial writes upfront -- convenient for computing rfGMO *) let gmo = gmo | loc & IW * (M\IW) (**********) (* Axioms *) (**********) (* Compute rf according to the load value axiom, aka rfGMO *) let WR = loc & ([W];(gmo|po);[R]) let rfGMO = WR \ (loc&([W];gmo);WR) (* Check equality of herd rf and of rfGMO *) empty (rf\rfGMO)|(rfGMO\rf) as RfCons (* Atomicity axiom *) let infloc = (gmo & loc)^-1 let inflocext = infloc & ext let winside = (infloc;rmw;inflocext) & (infloc;rf;rmw;inflocext) & [W] empty winside as Atomic
Figure B.7: riscv.cat, a herd version of the RVWMO memory model (2/3)
Partial (***************) (* Definitions *) (***************) (* Define ppo *) include "riscv-defs.cat" (* Compute coherence relation *) include "cos-opt.cat" (**********) (* Axioms *) (**********) (* Sc per location *) acyclic co|rf|fr|po-loc as Coherence (* Main model axiom *) acyclic co|rfe|fr|ppo as Model (* Atomicity axiom *) empty rmw & (fre;coe) as Atomic
Figure B.8: riscv.cat, an alternative herd presentation of the RVWMO memory model (3/3)
This is an alternative presentation of the RVWMO memory model in operational style. It aims to admit exactly the same extensional behavior as the axiomatic presentation: for any given program, admitting an execution if and only if the axiomatic presentation allows it.
The axiomatic presentation is defined as a predicate on complete candidate executions. In contrast, this operational presentation has an abstract microarchitectural flavor: it is expressed as a state machine, with states that are an abstract representation of hardware machine states, and with explicit out-of-order and speculative execution (but abstracting from more implementation-specific microarchitectural details such as register renaming, store buffers, cache hierarchies, cache protocols, etc.). As such, it can provide useful intuition. It can also construct executions incrementally, making it possible to interactively and randomly explore the behavior of larger examples, while the axiomatic model requires complete candidate executions over which the axioms can be checked.
The operational presentation covers mixed-size execution, with potentially overlapping memory accesses of different power-of-two byte sizes. Misaligned accesses are broken up into single-byte accesses.
The operational model, together with a fragment of the RISC-V ISA semantics (RV64I and A), are integrated into the rmem exploration tool (https://github.com/rems-project/rmem). rmem can explore litmus tests (see A.2) and small ELF binaries exhaustively, pseudo-randomly and interactively. In rmem, the ISA semantics is expressed explicitly in Sail (see https://github.com/rems-project/sail for the Sail language, and https://github.com/rems-project/sail-riscv for the RISC-V ISA model), and the concurrency semantics is expressed in Lem (see https://github.com/rems-project/lem for the Lem language).
rmem has a command-line interface and a web-interface. The web-interface runs entirely on the client side, and is provided online together with a library of litmus tests: http://www.cl.cam.ac.uk/~pes20/rmem. The command-line interface is faster than the web-interface, specially in exhaustive mode.
Below is an informal introduction of the model states and transitions. The description of the formal model starts in the next subsection.
Terminology: In contrast to the axiomatic presentation, here every memory operation is either a load or a store. Hence, AMOs give rise to two distinct memory operations, a load and a store. When used in conjunction with “instruction”, the terms “load” and “store” refer to instructions that give rise to such memory operations. As such, both include AMO instructions. The term “acquire” refers to an instruction (or its memory operation) with the acquire-RCpc or acquire-RCsc annotation. The term “release” refers to an instruction (or its memory operation) with the release-RCpc or release-RCsc annotation.
A model state consists of a shared memory and a tuple of hart states.
| Hart 0 | … | Hart n |
| ↑ ↓ | ↑ ↓ | |
| Shared Memory | ||
The shared memory state records all the memory store operations that have propagated so far, in the order they propagated (this can be made more efficient, but for simplicity of the presentation we keep it this way).
Each hart state consists principally of a tree of instruction instances, some of which have been finished, and some of which have not. Non-finished instruction instances can be subject to restart, e.g. if they depend on an out-of-order or speculative load that turns out to be unsound.
Conditional branch and indirect jump instructions may have multiple successors in the instruction tree. When such instruction is finished, any un-taken alternative paths are discarded.
Each instruction instance in the instruction tree has a state that includes an execution state of the intra-instruction semantics (the ISA pseudocode for this instruction). The model uses a formalization of the intra-instruction semantics in Sail. One can think of the execution state of an instruction as a representation of the pseudocode control state, pseudocode call stack, and local variable values. An instruction instance state also includes information about the instance’s memory and register footprints, its register reads and writes, its memory operations, whether it is finished, etc.
The model defines, for any model state, the set of allowed transitions, each of which is a single atomic step to a new abstract machine state. Execution of a single instruction will typically involve many transitions, and they may be interleaved in operational-model execution with transitions arising from other instructions. Each transition arises from a single instruction instance; it will change the state of that instance, and it may depend on or change the rest of its hart state and the shared memory state, but it does not depend on other hart states, and it will not change them. The transitions are introduced below and defined in Section B.3.5, with a precondition and a construction of the post-transition model state for each.
Transitions for all instructions:
The model assumes the instruction memory is fixed; it does not describe the behavior of self-modifying code. In particular, the omm:fetch transition does not generate memory load operations, and the shared memory is not involved in the transition. Instead, the model depends on an external oracle that provides an opcode when given a memory location.
Transitions specific to load instructions:
Transitions specific to store instructions:
Transitions specific to sc instructions:
Transitions specific to AMO instructions:
Transitions specific to fence instructions:
The transitions labeled ∘ can always be taken eagerly, as soon as their precondition is satisfied, without excluding other behavior; the • cannot. Although omm:fetch is marked with a •, it can be taken eagerly as long as it is not taken infinitely many times.
An instance of a non-AMO load instruction, after being fetched, will typically experience the following transitions in this order:
Before, between and after the transitions above, any number of omm:sail_interp transitions may appear. In addition, a omm:fetch transition for fetching the instruction in the next program location will be available until it is taken.
This concludes the informal description of the operational model. The following sections describe the formal operational model.
The intra-instruction semantics for each instruction instance is expressed as a state machine, essentially running the instruction pseudocode. Given a pseudocode execution state, it computes the next state. Most states identify a pending memory or register operation, requested by the pseudocode, which the memory model has to do. The states are (this is a tagged union; tags in small-caps):
| Load_mem(kind, address, size, load_continuation) | - | memory load operation |
| Early_sc_fail(res_continuation) | - | allow sc to fail early |
| Store_ea(kind, address, size, next_state) | - | memory store effective address |
| Store_memv(mem_value, store_continuation) | - | memory store value |
| Fence(kind, next_state) | - | fence |
| Read_reg(reg_name, read_continuation) | - | register read |
| Write_reg(reg_name, reg_value, next_state) | - | register write |
| Internal(next_state) | - | pseudocode internal step |
| Done | - | end of pseudocode |
Here: mem_value and reg_value are lists of bytes; address is an integer of XLEN bits; for load/store, kind identifies whether it is lr/sc, acquire-RCpc/release-RCpc, acquire-RCsc/release-RCsc, acquire-release-RCsc; for fence, kind identifies whether it is a normal or TSO, and (for normal fences) the predecessor and successor ordering bits; reg_name identifies a register and a slice thereof (start and end bit indices); and the continuations describe how the instruction instance will continue for each value that might be provided by the surrounding memory model (the load_continuation and read_continuation take the value loaded from memory and read from the previous register write, the store_continuation takes false for an sc that failed and true in all other cases, and res_continuation takes false if the sc fails and true otherwise).
lw x1,0(x2),
an execution will typically go as follows.
The initial execution state will be computed from the pseudocode for the given opcode.
This can be expected to be Read_reg(x2, read_continuation).
Feeding the most recently written value of register x2 (the instruction semantics will be blocked if necessary until the register value is available), say 0x4000, to read_continuation returns Load_mem(plain_load, 0x4000, 4, load_continuation).
Feeding the 4-byte value loaded from memory location 0x4000, say 0x42, to load_continuation returns
Write_reg(x1, 0x42, Done).
Many Internal(next_state) states may appear before and between the states above.
Notice that writing to memory is split into two steps, Store_ea and Store_memv: the first one makes the memory footprint of the store provisionally known, and the second one adds the value to be stored. We ensure these are paired in the pseudocode (Store_ea followed by Store_memv), but there may be other steps between them.
The pseudocode of each instruction performs at most one store or one load, except for AMOs that perform exactly one load and one store. Those memory accesses are then split apart into the architecturally atomic units by the hart semantics (see omm:initiate_load and omm:initiate_store_footprint below).
Informally, each bit of a register read should be satisfied from a register write by the most recent (in program order) instruction instance that can write that bit (or from the hart’s initial register state if there is no such write). Hence, it is essential to know the register write footprint of each instruction instance, which we calculate when the instruction instance is created (see the action of omm:fetch below). We ensure in the pseudocode that each instruction does at most one register write to each register bit, and also that it does not try to read a register value it just wrote.
Data-flow dependencies (address and data) in the model emerge from the fact that each register read has to wait for the appropriate register write to be executed (as described above).
Each instruction instance i has a state comprising:
| Plain(isa_state) | - | ready to make a pseudocode transition |
| Pending_mem_loads(load_continuation) | - | requesting memory load operation(s) |
| Pending_mem_stores(store_continuation) | - | requesting memory store operation(s) |
Each memory load operation includes a memory footprint (address and size). Each memory store operations includes a memory footprint, and, when available, a value.
A load instruction instance with a non-empty mem_loads, for which all the load operations are satisfied (i.e. there are no unsatisfied load slices) is said to be entirely satisfied.
Informally, an instruction instance is said to have fully determined data if the load (and sc) instructions feeding its source registers are finished. Similarly, it is said to have a fully determined memory footprint if the load (and sc) instructions feeding its memory operation address register are finished. Formally, we first define the notion of fully determined register write: a register write w from reg_writes of instruction instance i is said to be fully determined if one of the following conditions hold:
Now, an instruction instance i is said to have fully determined data if for every register read r from reg_reads, the register writes that r reads from are fully determined. An instruction instance i is said to have a fully determined memory footprint if for every register read r from reg_reads that feeds into i’s memory operation address, the register writes that r reads from are fully determined.
The model state of a single hart comprises:
The model state of the shared memory comprises a list of memory store operations, in the order they propagated to the shared memory.
When a store operation is propagated to the shared memory it is simply added to the end of the list. When a load operation is satisfied from memory, for each byte of the load operation, the most recent corresponding store slice is returned.
Each of the paragraphs below describes a single kind of system transition. The description starts with a condition over the current system state. The transition can be taken in the current state only if the condition is satisfied. The condition is followed by an action that is applied to that state when the transition is taken, in order to generate the new system state.
A possible program-order-successor of instruction instance i can be fetched from address loc if:
Action: construct a freshly initialized instruction instance i′ for the instruction in the program memory at loc, with state Plain(isa_state), computed from the instruction pseudocode, including the static information available from the pseudocode such as its instruction_kind, src_regs, and dst_regs, and add i′ to the hart’s instruction_tree as a successor of i.
An instruction instance i in state Plain(Load_mem(kind, address, size, load_continuation)) can always initiate the corresponding memory load operations. Action:
For a non-AMO load instruction instance i in state Pending_mem_loads(load_continuation), and a memory load operation mlo in i.mem_loads that has unsatisfied slices, the memory load operation can be partially or entirely satisfied by forwarding from unpropagated memory store operations by store instruction instances that are program-order-before i if:
Let msoss be the set of all unpropagated memory store operation slices from non-sc store instruction instances that are program-order-before i and have already calculated the value to be stored, that overlap with the unsatisfied slices of mlo, and which are not superseded by intervening store operations or store operations that are read from by an intervening load. The last condition requires, for each memory store operation slice msos in msoss from instruction i′: that there is no store instruction program-order-between i and i′ with a memory store operation overlapping msos; and that there is no load instruction program-order-between i and i′ that was satisfied from an overlapping memory store operation slice from a different hart.
Action:
Where, the restart-dependents of instruction j are: program-order-successors of j that have data-flow dependency on a register write of j; program-order-successors of j that have a memory load operation that reads from a memory store operation of j (by forwarding); if j is a load-acquire, all the program-order-successors of j; if j is a load, for every fence, f, with .sr and .pr set, and .pw not set, that is a program-order-successor of j, all the load instructions that are program-order-successors of f; if j is a load, for every fence.tso, f, that is a program-order-successor of j, all the load instructions that are program-order-successors of f; and (recursively) all the restart-dependents of all the instruction instances above.
A program-order-previous store operation that was not available when taking the transition above might make msoss provisionally unsound (violating coherence) when it becomes available. That store will prevent the load from being finished (see omm:finish), and will cause it to restart when that store operation is propagated (see omm:prop_store).
A consequence of the transition condition above is that store-release-RCsc memory store operations cannot be forwarded to load-acquire-RCsc instructions: msoss does not include memory store operations from finished stores (as those must be propagated memory store operations), and the condition above requires all program-order-previous store-releases-RCsc to be finished when the load is acquire-RCsc.
For an instruction instance i of a non-AMO load instruction or an AMO instruction in the context of the “omm:do_amo” transition, any memory load operation mlo in i.mem_loads that has unsatisfied slices, can be satisfied from memory if all the conditions of omm:sat_by_forwarding are satisfied. Action: let msoss be the memory store operation slices from memory covering the unsatisfied slices of mlo, and apply the action of omm:sat_by_forwarding.
A load instruction instance i in state Pending_mem_loads(load_continuation) can be completed (not to be confused with finished) if all the memory load operations i.mem_loads are entirely satisfied (i.e. there are no unsatisfied slices). Action: update the state of i to Plain(load_continuation(mem_value)), where mem_value is assembled from all the memory store operation slices that satisfied i.mem_loads.
An sc instruction instance i in state Plain(Early_sc_fail(res_continuation)) can always be made to fail. Action: update the state of i to Plain(res_continuation(false)).
An sc instruction instance i in state Plain(Early_sc_fail(res_continuation)) can continue its (potentially successful) execution if i is paired with an lr. Action: update the state of i to Plain(res_continuation(true)).
An instruction instance i in state Plain(Store_ea(kind, address, size, next_state)) can always announce its pending memory store operation footprint. Action:
An instruction instance i in state Plain(Store_memv(mem_value, store_continuation)) can always instantiate the values of the memory store operations i.mem_stores. Action:
An uncommitted instruction instance i of a non-sc store instruction or an sc instruction in the context of the “omm:commit_sc” transition, in state Pending_mem_stores(store_continuation), can be committed (not to be confused with propagated) if:
Action: record that i is committed.
For a committed instruction instance i in state Pending_mem_stores(store_continuation), and an unpropagated memory store operation mso in i.mem_stores, mso can be propagated if:
Where a non-finished instruction instance j is non-restartable if:
Action:
An uncommitted sc instruction instance i, from hart h, in state Pending_mem_stores(store_continuation), with a paired lr i′ that has been satisfied by some store slices msoss, can be committed and propagated at the same time if:
Action:
An sc instruction instance i in state Pending_mem_stores(store_continuation), that has not propagated its memory store operation, can always be made to fail. Action:
A store instruction instance i in state Pending_mem_stores(store_continuation), for which all the memory store operations in i.mem_stores have been propagated, can always be completed (not to be confused with finished). Action: update the state of i to Plain(store_continuation(true)).
An AMO instruction instance i in state Pending_mem_loads(load_continuation) can perform its memory access if it is possible to perform the following sequence of transitions with no intervening transitions:
and in addition, the condition of omm:finish, with the exception of not requiring i to be in state Plain(Done), holds after those transitions. Action: perform the above sequence of transitions (this does not include omm:finish), one after the other, with no intervening transitions.
In addition, the store of an AMO cannot be forwarded to a program-order-successor load. Before taking the transition above, the store operation of the AMO does not have its value and therefore cannot be forwarded; after taking the transition above the store operation is propagated and therefore cannot be forwarded.
A fence instruction instance i in state Plain(Fence(kind, next_state)) can be committed if:
Action:
An instruction instance i in state Plain(Read_reg(reg_name, read_cont)) can do a register read of reg_name if every instruction instance that it needs to read from has already performed the expected reg_name register write.
Let read_sources include, for each bit of reg_name, the write to that bit by the most recent (in program order) instruction instance that can write to that bit, if any. If there is no such instruction, the source is the initial register value from initial_register_state. Let reg_value be the value assembled from read_sources. Action:
An instruction instance i in state Plain(Write_reg(reg_name, reg_value, next_state)) can always do a reg_name register write. Action:
where deps is a pair of the set of all read_sources from i.reg_reads, and a flag that is true iff i is a load instruction instance that has already been entirely satisfied.
An instruction instance i in state Plain(Internal(next_state)) can always do that pseudocode-internal step. Action: update the state of i to Plain(next_state).
A non-finished instruction instance i in state Plain(Done) can be finished if:
Action:
This document was translated from LATEX by HEVEA.